
Специалист по разметке данных
3 мин
Сегодня замечательный день (if you know what I mean), чтобы анонсировать нашу новую программу — Специалист по разметке данных.
На текущий момент в сфере искусственного интеллекта сложилась такая ситуация, при которой для обучения сильной нейронной сети нужны несколько компонентов: железо, софт и, непосредственно, данные. Много данных.
Железо, в общем-то, доступно каждому через облака. Да, оно может быть недешевым, но GPU-инстансы на EC2 вполне по карману большинству исследователей. Софт опенсорсный, большинство фреймворков можно скачать себе куда-то и работать с ними. Некоторые сложнее, некоторые проще. Но порог для входа вполне приемлемый. Остается только последний компонент — это данные. И вот здесь и возникает загвоздка.
Deep learning требует действительно больших данных: сотни тысяч–миллионы объектов. Если вы хотите заниматься, например, задачей классификации изображений, то вам, помимо самих данных, нужно передать нейронке информацию, к какому классу относится тот или иной объект. Если у вас задача связана еще и с сегментацией изображения, то получение хорошего датасета — это уже фантастически сложно. Представьте, что вам нужно на каждом изображении выделить границы каждого объекта.

В этом посте хочется сделать обзор тех инструментов (коммерческих и бесплатных), которые пытаются облегчить жизнь этих прекрасных людей — разметчиков данных.
На текущий момент в сфере искусственного интеллекта сложилась такая ситуация, при которой для обучения сильной нейронной сети нужны несколько компонентов: железо, софт и, непосредственно, данные. Много данных.
Железо, в общем-то, доступно каждому через облака. Да, оно может быть недешевым, но GPU-инстансы на EC2 вполне по карману большинству исследователей. Софт опенсорсный, большинство фреймворков можно скачать себе куда-то и работать с ними. Некоторые сложнее, некоторые проще. Но порог для входа вполне приемлемый. Остается только последний компонент — это данные. И вот здесь и возникает загвоздка.
Deep learning требует действительно больших данных: сотни тысяч–миллионы объектов. Если вы хотите заниматься, например, задачей классификации изображений, то вам, помимо самих данных, нужно передать нейронке информацию, к какому классу относится тот или иной объект. Если у вас задача связана еще и с сегментацией изображения, то получение хорошего датасета — это уже фантастически сложно. Представьте, что вам нужно на каждом изображении выделить границы каждого объекта.
В этом посте хочется сделать обзор тех инструментов (коммерческих и бесплатных), которые пытаются облегчить жизнь этих прекрасных людей — разметчиков данных.

 , и добро пожаловать под кат.
, и добро пожаловать под кат. С развитием компьютерных мощностей и появлением множества технологий обработки изображений всё чаще стал возникать вопрос: а можно ли научить машину видеть и распознавать образы? Например, отличать кошку от собаки или даже бладхаунда от бассета? О точности распознавания говорить не приходится: наш мозг несравнимо быстрее может понять, что перед нами, при условии, что раньше мы получили достаточно сведений об объекте. Т.е. даже видя только часть собаки, мы можем с уверенностью сказать, что это собака. А если ты — собаковод, то легко определишь и породу собаки. Но как научить машину различать их? Какие существуют алгоритмы? А можно ли обмануть машину? (Спойлер: конечно можно! Точно так же, как и наш мозг.) Попробуем осмыслить все эти вопросы и по возможности ответить на них. Итак, приступим.
С развитием компьютерных мощностей и появлением множества технологий обработки изображений всё чаще стал возникать вопрос: а можно ли научить машину видеть и распознавать образы? Например, отличать кошку от собаки или даже бладхаунда от бассета? О точности распознавания говорить не приходится: наш мозг несравнимо быстрее может понять, что перед нами, при условии, что раньше мы получили достаточно сведений об объекте. Т.е. даже видя только часть собаки, мы можем с уверенностью сказать, что это собака. А если ты — собаковод, то легко определишь и породу собаки. Но как научить машину различать их? Какие существуют алгоритмы? А можно ли обмануть машину? (Спойлер: конечно можно! Точно так же, как и наш мозг.) Попробуем осмыслить все эти вопросы и по возможности ответить на них. Итак, приступим.
 В последнее время машины одержали ряд убедительных побед над людьми: они уже лучше играют в го, шахматы и даже в Dota 2. Алгоритмы сочиняют музыку и пишут стихи. Учёные и предприниматели всего мира дают прогнозы по поводу будущего, в котором искусственный интеллект сильно превзойдёт человека. С большой вероятностью через несколько десятков лет мы будем жить в мире, в котором роботы не только водят автомобили и работают на заводах, но и развлекают нас. Одна из важных составляющих нашей жизни — юмор. Принято считать, что только человек может придумывать шутки. Несмотря на это, многие ученые, инженеры и даже простые обыватели задаются вопросом: можно ли научить компьютер шутить?
В последнее время машины одержали ряд убедительных побед над людьми: они уже лучше играют в го, шахматы и даже в Dota 2. Алгоритмы сочиняют музыку и пишут стихи. Учёные и предприниматели всего мира дают прогнозы по поводу будущего, в котором искусственный интеллект сильно превзойдёт человека. С большой вероятностью через несколько десятков лет мы будем жить в мире, в котором роботы не только водят автомобили и работают на заводах, но и развлекают нас. Одна из важных составляющих нашей жизни — юмор. Принято считать, что только человек может придумывать шутки. Несмотря на это, многие ученые, инженеры и даже простые обыватели задаются вопросом: можно ли научить компьютер шутить? 







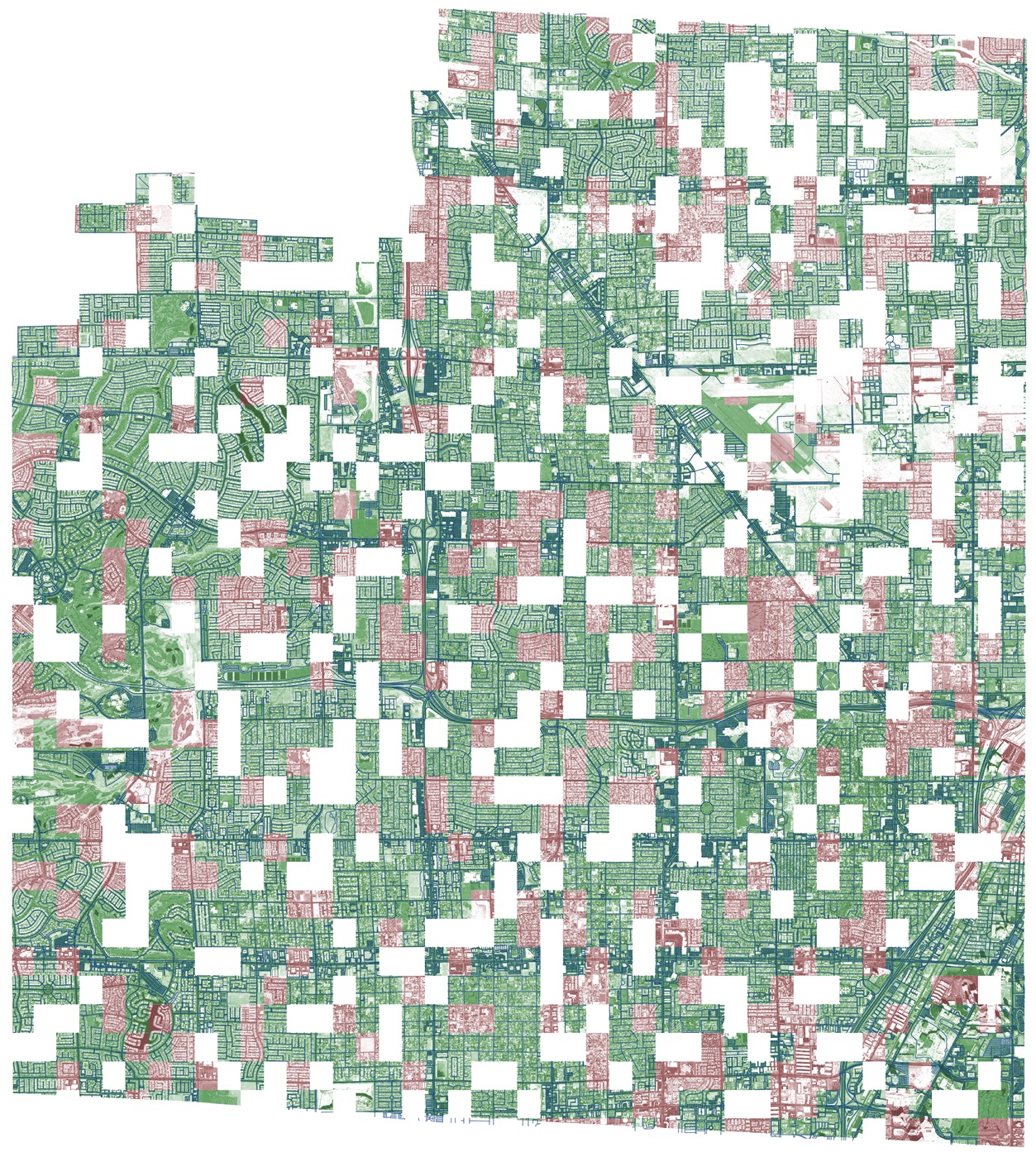

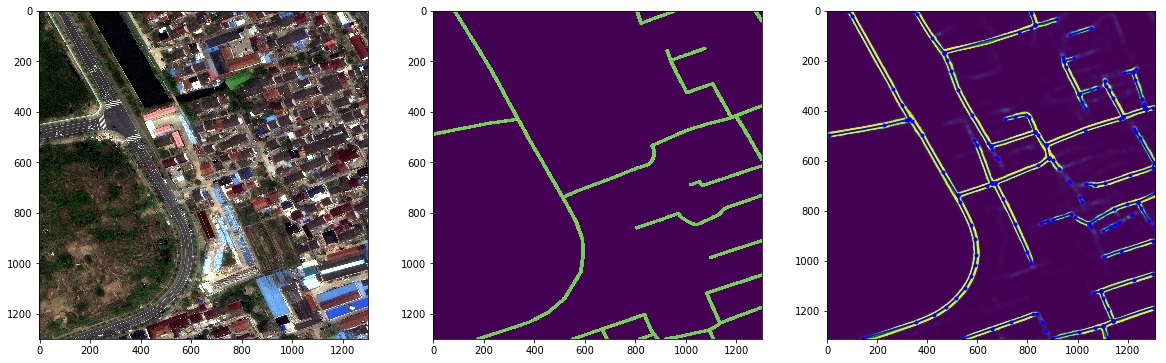

 Если отвлечься от съемки с помощью беспилотных летательных аппаратов (БПЛА) свадеб, торжеств и юбилеев, то становится очевидным, что в арсенале специалистов по картографированию территорий, экологов и военных появился мощный инструмент в работе — промышленные беспилотные аппараты, которые способны решать различные задачи по построению качественной картографической информации, подробных ортофотопланов территорий, лесов, сельскохозяйственных угодий и городских территорий. Учитывая тот факт, что получить качественный фотографический материал для построения 3D моделей местности только с первого взгляда кажется простым делом, в действительности — задача имеет массу всяческих особенностей. Захотелось поделиться собственным опытом организации промышленной аэрофотосъемки, местом расположения граблей, на которые пришлось наступить, а вернее — на которые пришлось налететь. За всеми подробностями прошу под кат.
Если отвлечься от съемки с помощью беспилотных летательных аппаратов (БПЛА) свадеб, торжеств и юбилеев, то становится очевидным, что в арсенале специалистов по картографированию территорий, экологов и военных появился мощный инструмент в работе — промышленные беспилотные аппараты, которые способны решать различные задачи по построению качественной картографической информации, подробных ортофотопланов территорий, лесов, сельскохозяйственных угодий и городских территорий. Учитывая тот факт, что получить качественный фотографический материал для построения 3D моделей местности только с первого взгляда кажется простым делом, в действительности — задача имеет массу всяческих особенностей. Захотелось поделиться собственным опытом организации промышленной аэрофотосъемки, местом расположения граблей, на которые пришлось наступить, а вернее — на которые пришлось налететь. За всеми подробностями прошу под кат. 