Книга «System Design. Машинное обучение. Подготовка к сложному интервью»
10 мин
 Привет, Хаброжители!
Привет, Хаброжители!Собеседования по проектированию систем машинного обучения — самые сложные. Если нужно подготовиться к такому, книга создана специально для вас.
Также она поможет всем, кто интересуется проектированием систем МО, будь то новички или опытные инженеры.
Что внутри?
- О чем на самом деле спрашивают на собеседовании по System Design в МО и почему (инсайдерская информация!).
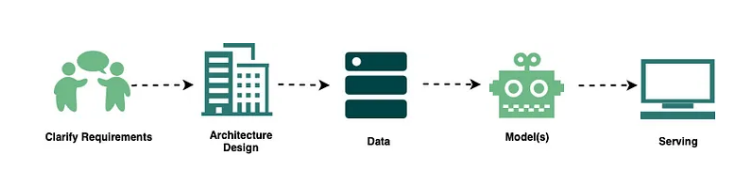
- 7 основных шагов для решения любой задачи МО, предлагаемой на собеседовании.
- 10 вопросов из реальных собеседований по System Design в МО с подробным разбором ответов.
- 211 диаграмм, которые наглядно объясняют, как работают различные системы.