
Несколько соображений по поводу параллельных вычислений в R применительно к «enterprise» задачам
3 мин
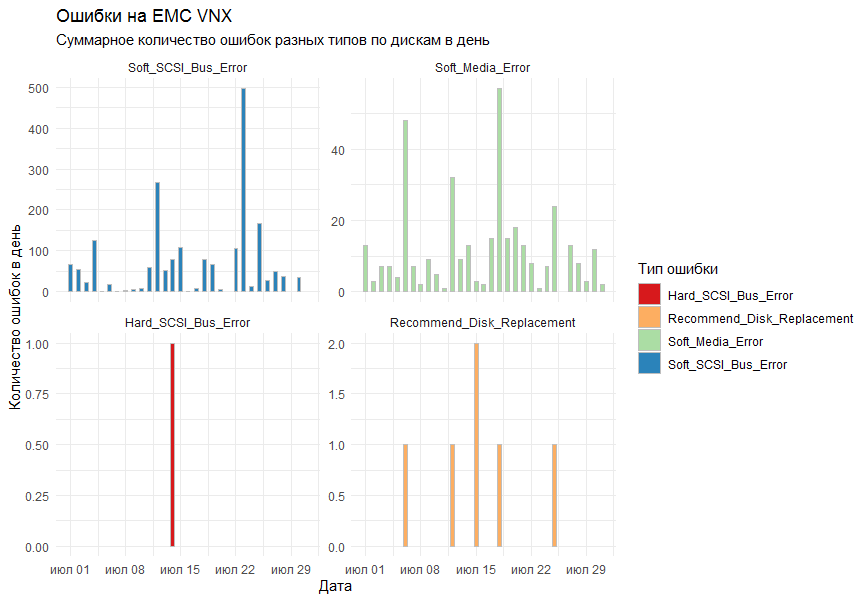
Параллельные или распределенные вычисления — вещь сама по себе весьма нетривиальная. И среда разработки должна поддерживать, и DS специалист должен обладать навыками проведения параллельных вычислений, да и задача должна быть приведена к разделяемому на части виду, если таковой существует. Но при грамотном подходе можно весьма ускорить решение задачи однопоточным R, если у вас под руками есть хотя бы многоядерный процессор (а он есть сейчас почти у всех), с поправкой на теоретическую границу ускорения, определяемую законом Амдала. Однако, в ряде случаев даже его можно обойти.
Является продолжением предыдущих публикаций.












 Это Лесли Лэмпорт — автор основополагающих работ в распределённых вычислениях, а ещё вы его можете знать по буквам La в слове LaTeX — «Lamport TeX». Это он впервые, ещё в 1979 году, ввёл понятие
Это Лесли Лэмпорт — автор основополагающих работ в распределённых вычислениях, а ещё вы его можете знать по буквам La в слове LaTeX — «Lamport TeX». Это он впервые, ещё в 1979 году, ввёл понятие