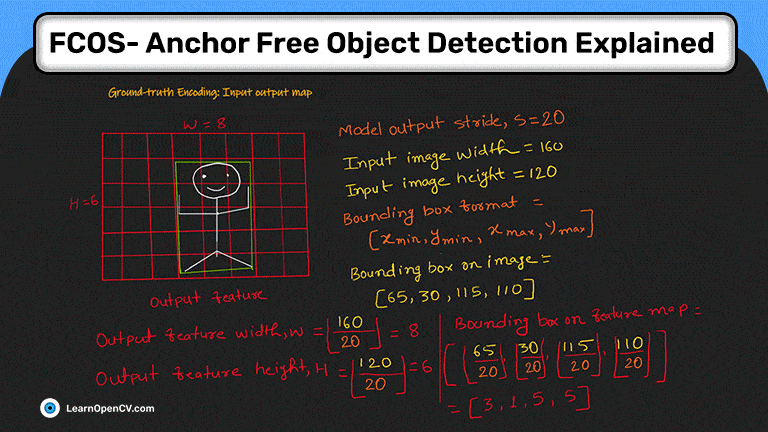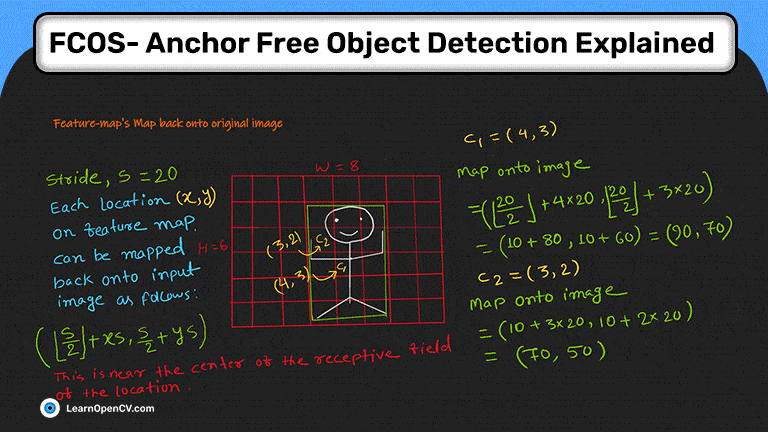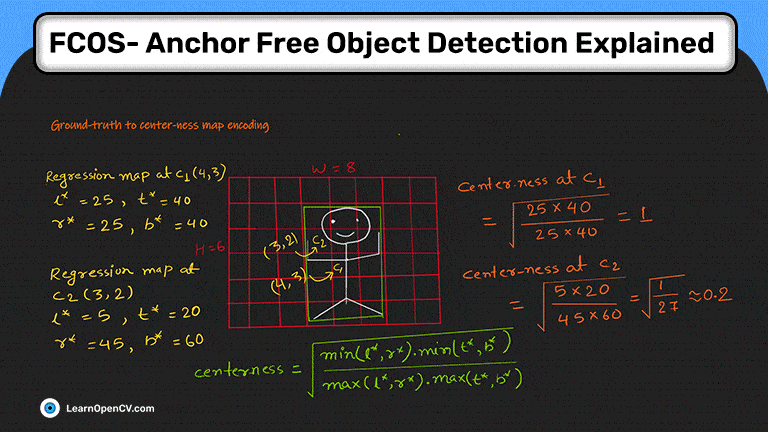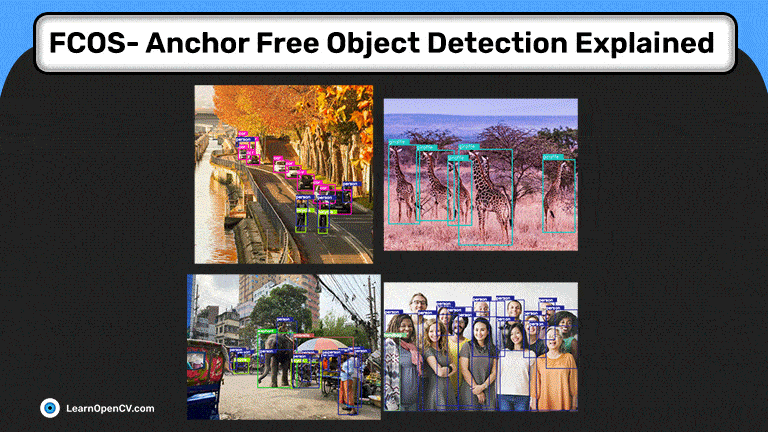
Как я использовал нейросеть для категоризации трехмерных тел

Значимость темы машинного обучения (machine learning) сегодня очевидна. Это огромный домен знаний в Computer Science, которому в России, в частности, посвящают конференции уровня недавней AI Journey. Существует множество способов применения ML в различных областях, среди самых исследованных: распознавание изображений/видео/голоса, процессинг текста. Однако есть и более любопытные задачи, с которыми справляется ML. Например, обучение с подкреплением, что позволяет ИИ играть в игры типа Го, идентификация людей по фотографии, распознавание жестов, движений и поз человека.
Одной из не совсем обычных областей применения машинного обучения можно назвать работу с трехмерными телами. Такая технология активно исследуется за рубежом, а вариантов использования у нее может быть масса. Простой пример: дрон сканирует помещение, в котором находится множество тел. С помощью ML дрон может классифицировать объекты окружения, найти ошибки в пространственном размещении этих тел или же построить 3D-интерьер комнаты со ссылками на онлайн-магазин, где эти предметы можно купить.
Под катом — рассказ о том, как наш сотрудник задействовал машинное обучение для распознавания и классификации трехмерных тел. При этом весь информационный контекст был ограничен геометрией этих тел, то есть исключительно набором вершин и полигонов.