Доброго времени суток, Хабр. Решил поделиться своим знанием, как можно быстро загрузить большое количество файлов в Google Colab с Google Drive.
Всем известно, что Google Colab отличная бесплатная платформа для обучения и экспериментов над Нейронными Сетями.
На платформе Google Colab Вам бесплатно предоставят мощную видеокарту на которой вы сможете поэкспериментировать с обучением своей нейросети на протяжении примерно 12 часов.
Затем сеанс прервется, но на следующий день от Google можно опять будет получить видеокарту и продолжить свои эксперименты.
Нейронным сетям требуется очень много данных для обучения, особенно если речь идет о нейросетях работающих с изображениями.
Для обучения таких нейросетей необходимо загрузить в обучающую и валидационную выборки тысячи и сотни изображений. К сожалению, если эти изображения загружать непосредственно из вашего Google Drive, это занимает неприлично долгое время — десятки минут или даже часы. Ведь каждое обращение за файлом в Google Drive и получение от него ответа с содержимым файла происходит последовательно и не быстро.
Обидно тратить время доступа к бесплатной видеокарте на загрузку данных, да и не разумно это.
А мы люди разумные, поэтому мы один раз обратимся к Google Drive считаем наши данные запакованные заранее в zip архив, распакуем полученный zip архив в память Google Colab и считаем свои данные со скоростью в сотни раз большей чем с Google Drive последовательно по одному файлу.
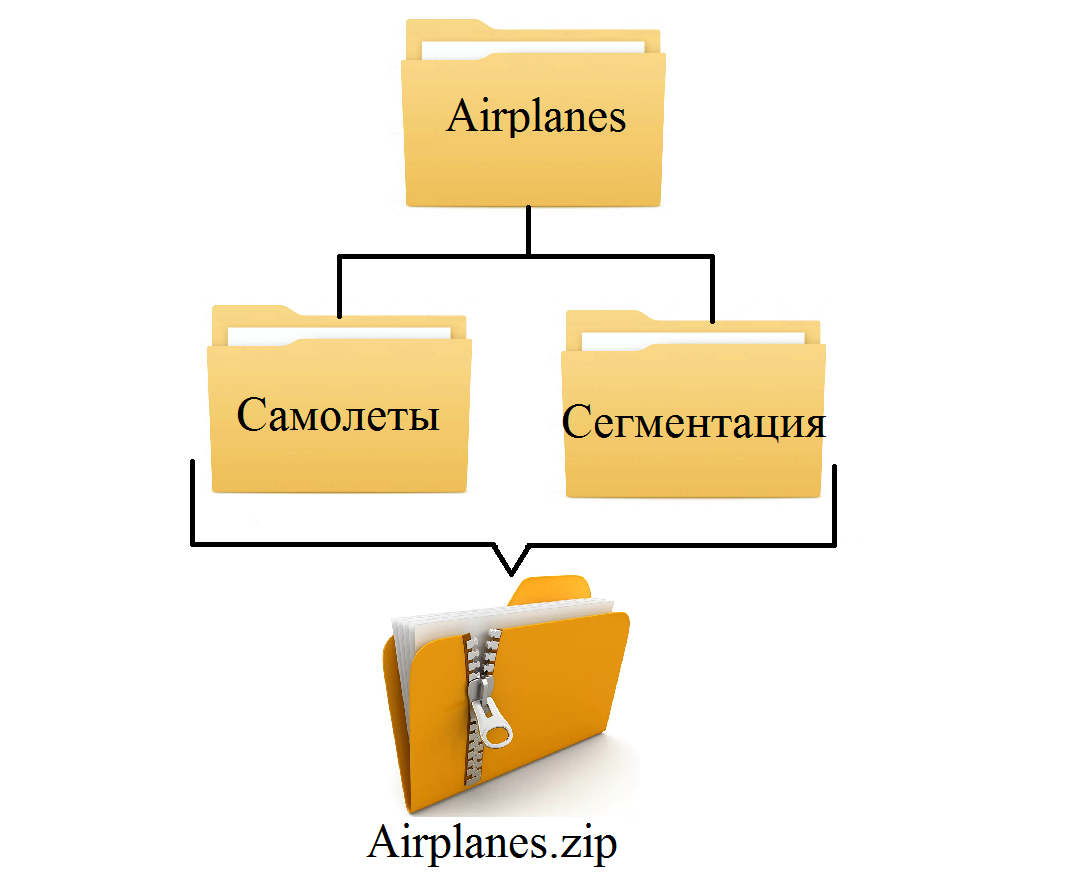
Для эксперимента со скорость загрузки данных в Colab я взял имеющуюся у меня базу «Airplanes» для сегментационной нейросети.
В этой базе есть папка с изображениями «самолеты» и папка «сегментация», где хранятся маски изображений самолетов из вышеназванной папки.
В каждой папке по 1005 изображений 1920*1080.
В общей сложности нам предстоит загрузить 2010 файлов.
Я заранее загрузил к себе на Google Drive как саму базу с изображениями, так и ее zip архив.
Структура Обучающей Базы: