C/C++ из Python (C API)
7 мин
Туториал

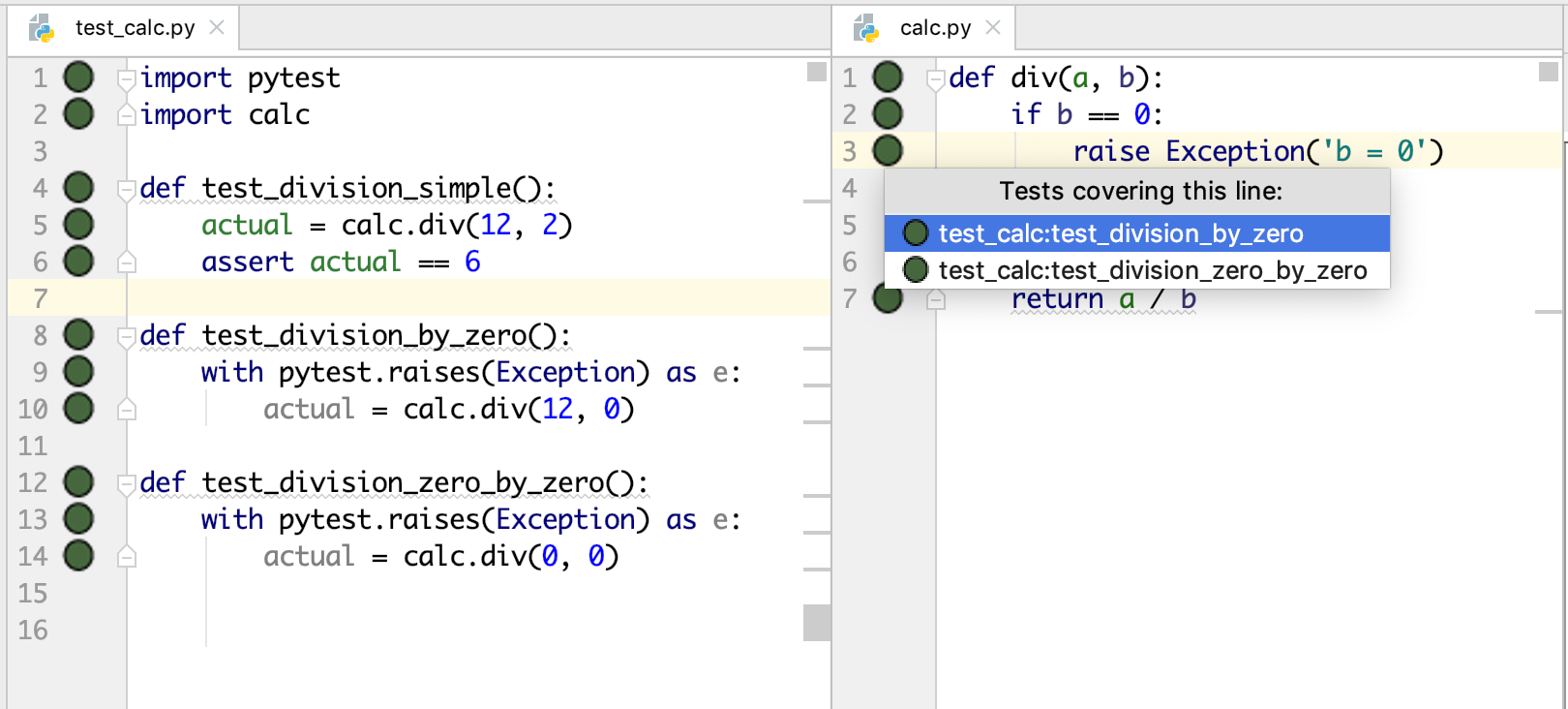
Продолжаем тему как вызывать C/C++ из Python3. Теперь используем C API для создания модуля, на этом примере мы сможем разобраться как работает cffi и прочие библиотеки упрощающие нам жизнь. Потому что на мой взгляд это самый трудный способ.