Как у нейросетей работает внимание? Статья про self-attention и cross-attention
Средний
5 мин

Удивительно, как нейросети похожи на нас. У них тоже есть внимание, и на примере коня на ракете я расскажу, как оно работает!

Пользователь
Удивительно, как нейросети похожи на нас. У них тоже есть внимание, и на примере коня на ракете я расскажу, как оно работает!

Примерно год назад энтузиаст с Kaggle по имени Дарек Клечек провел интересный эксперимент: он собрал все доступные описания (writeups) побеждавших на Kaggle за последние годы решений, пропустил их через LLM и свел по ним общую статистику о том, какие механики и алгоритмы оказываются "наиболее победными". Отчет у парня получился достаточно объемный, интересный, а местами и непредсказуемый. Эта статья – свободный авторский пересказ его эссе. И пусть прологом к ней послужит цитата Дарека:



class. Оно ведь нужно для связи HTML с CSS, правда? Сейчас я расскажу о том, почему настало время отказаться от него. Имена классов — это архаичная система, используемая как неудачный посредник для примитивов UI; ещё хуже то, что они создают ужасные сочетания, приводящие к комбинаторному взрыву странных пограничных случаев. Давайте изучим этот вопрос, начав со скучного урока истории, который вы уже слышали миллион раз.
Привет, Хабр! Я историк, работаю над историко-географическими базами данных в российском генеалогическом сервисе familio.org. В этой статье расскажу как мы сделали карту исторических промыслов Костромской губернии для фестиваля семейной истории в Кинешме. Надеюсь, что материал будет интересен не только любителям исторической географии, но и тем, кто интересуется визуализацией своих данных на карте.
 В WinAPI есть функция CreateRemoteThread, позволяющая запустить новый поток в адресном пространстве другого процесса. Её можно использовать для разнообразных DLL-инъекций как с нехорошими целями (читы в играх, кража паролей, и т. д.), так и для того, чтобы на лету исправить баг в работающей программе, или добавить плагины туда, где они не были предусмотрены.
В WinAPI есть функция CreateRemoteThread, позволяющая запустить новый поток в адресном пространстве другого процесса. Её можно использовать для разнообразных DLL-инъекций как с нехорошими целями (читы в играх, кража паролей, и т. д.), так и для того, чтобы на лету исправить баг в работающей программе, или добавить плагины туда, где они не были предусмотрены.
В целом эта функция обладает сомнительной прикладной полезностью, поэтому не удивительно, что в Linux готового аналога CreateRemoteThread нет. Однако, мне было интересно, как он может быть реализован. Изучение темы вылилось в неплохое приключение.
Я подробно расскажу о том, как с помощью спецификации ELF, некоторого знания архитектуры x86_64 и системных вызовов Linux написать свой маленький кусочек отладчика, способный загрузить и исполнить произвольный код в уже запущенном и работающем процессе.
Для понимания текста потребуются базовые знания о системном программировании под Linux: язык Си, написание и отладка программ на нём, осознание роли машинного кода и памяти в работе компьютера, понятие системных вызовов, знакомство с основными библиотеками, навык чтения документации.


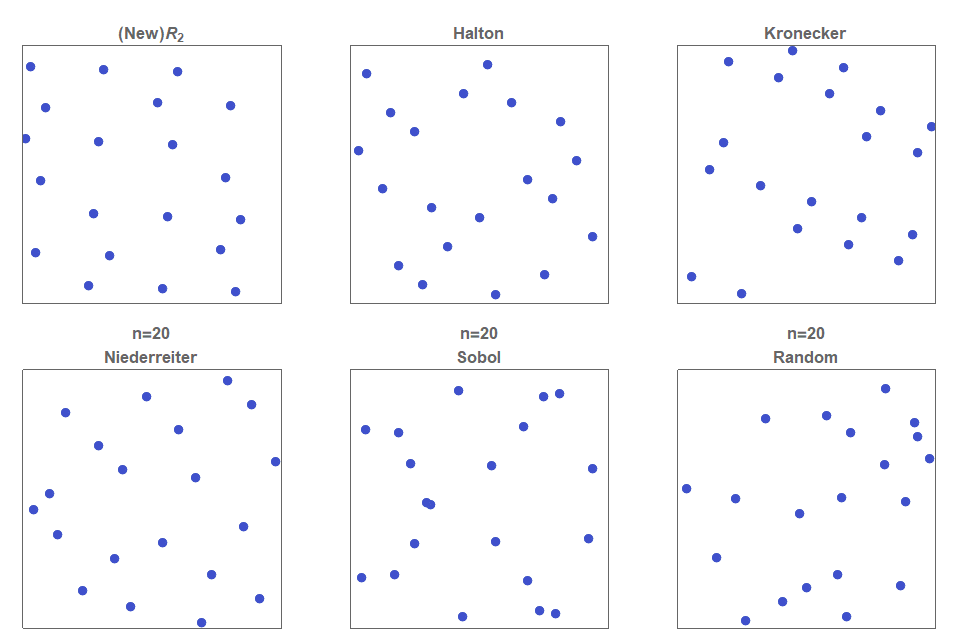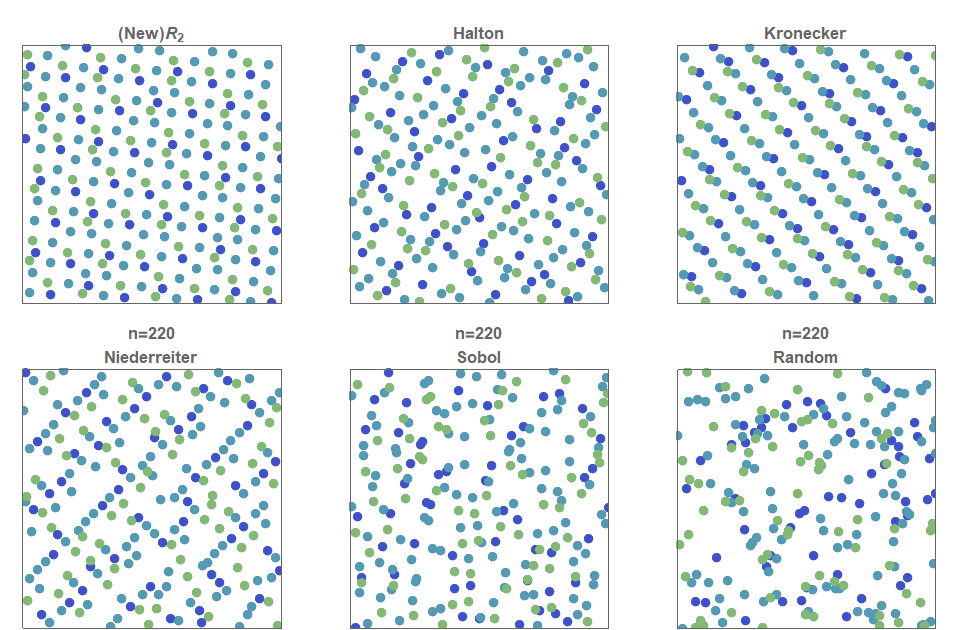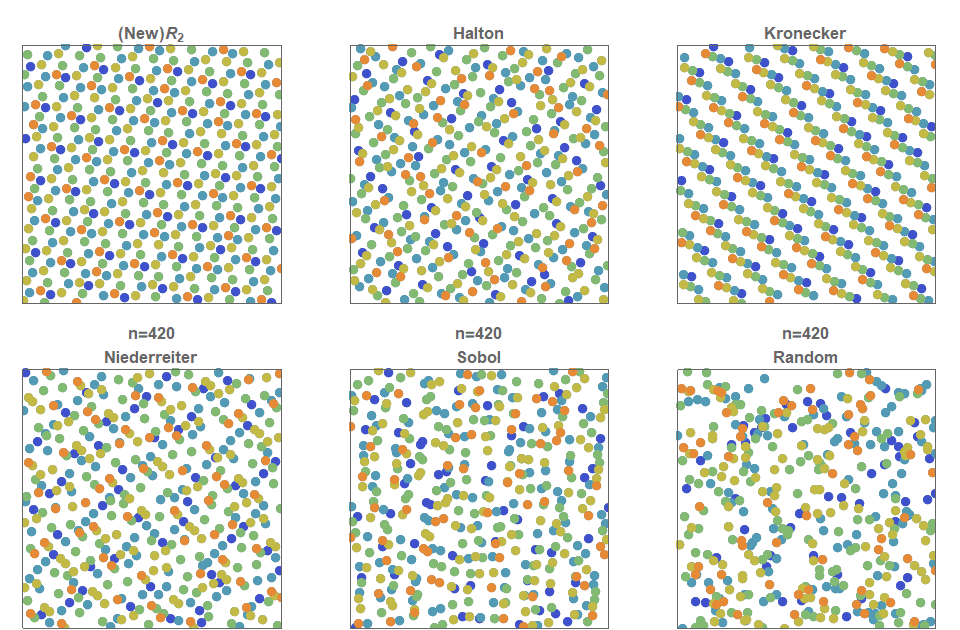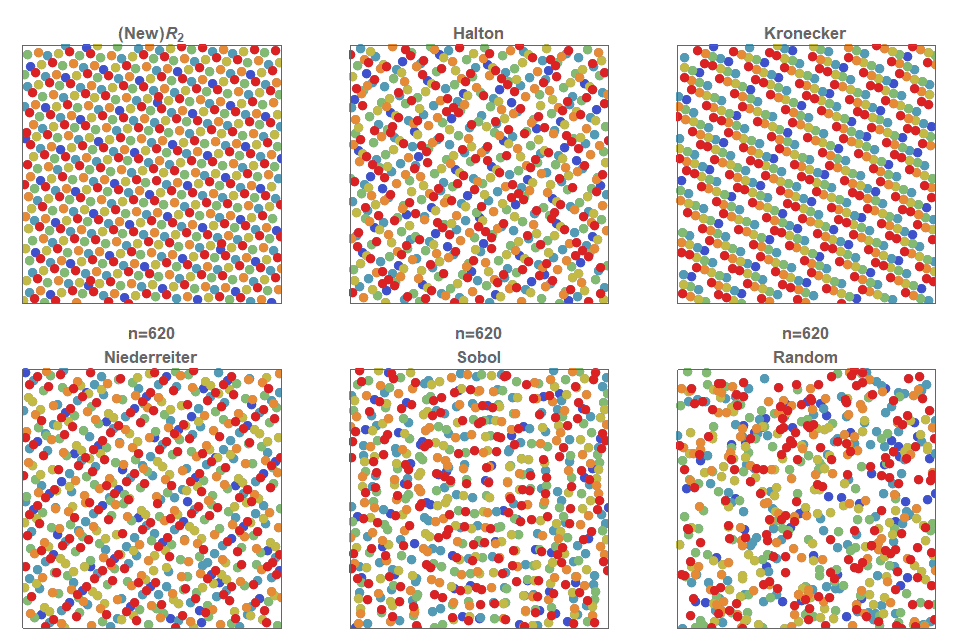

Это tutorial по библиотеке TensorFlow. Рассмотрим её немного глубже, чем в статьях про распознавание рукописных цифр. Это tutorial по методам оптимизации. Совсем без математики здесь не обойтись. Ничего страшного, если вы её совершенно забыли. Вспомним. Не будет никаких формальных доказательств и сложных выводов, только необходимый минимум для интуитивного понимания. Для начала небольшая предыстория о том, чем этот алгоритм может быть полезен при оптимизации нейронной сети.

Полгода назад друг попросил показать, как на Python сделать нейросеть. Его компания выпускает приборы для геофизических измерений. Несколько различных зондов в процессе бурения измеряют набор сигналов, связаных с параметрами окружающей скважину среды. В некоторых сложных случаях точно вычислить параметры среды по сигналам долго даже на мощном компьютере, а необходимо интерпретировать результаты измерений в полевых условиях. Возникла идея посчитать на кластере несколько сот тысяч случаев, и на них натренировать нейронную сеть. Так как нейросеть работает очень быстро, её можно использовать для определения параметров, согласующихся с измеренными сигналами, прямо в процессе бурения. Детали есть в статье:
Kushnir, D., Velker, N., Bondarenko, A., Dyatlov, G., & Dashevsky, Y. (2018, October 29). Real-Time Simulation of Deep Azimuthal Resistivity Tool in 2D Fault Model Using Neural Networks (Russian). Society of Petroleum Engineers. doi:10.2118/192573-RU
Одним вечером я показал, как keras реализовать простую нейронную сеть, и друг на работе запустил обучение на насчитанных данных. Через пару дней обсудили результат. С моей точки зрения он выглядел перспективно, но друг сказал, что нужны вычисления с точностью прибора. И если средняя квадратичная ошибка (mean squared error) получилась в районе 1, то нужна была 1е-3. На 3 порядка меньше. В тысячу раз.



 Это пятая статья из цикла «Теория категорий для программистов». Предыдущие статьи уже публиковались на Хабре в переводе Monnoroch:
Это пятая статья из цикла «Теория категорий для программистов». Предыдущие статьи уже публиковались на Хабре в переводе Monnoroch: