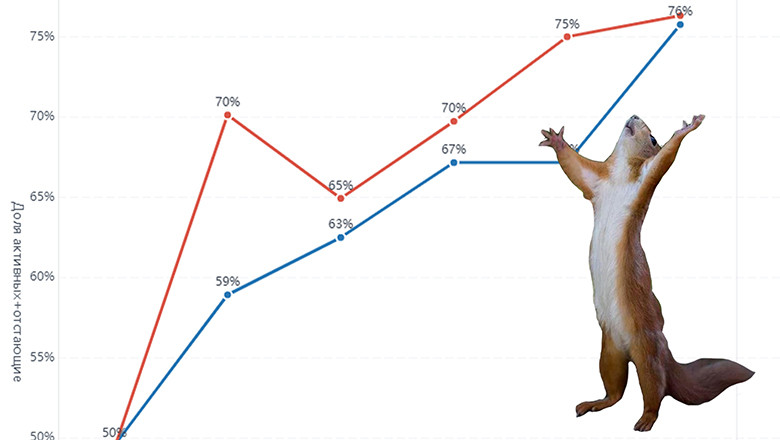
Приветствуем всех читателей! Сегодня команда Ad-Hoc аналитики X5 Tech приоткроет дверь в увлекательный мир A/B-тестирования Causal Inference. С момента написания предыдущей статьи прошло уже 4 года. За это время наш подход к оценке инициатив значительно эволюционировал. Мы собирали бизнес-кейсы, изучали научную литературу, экспериментировали с реальными данными и в итоге пришли не только к другой модели для оценки эффекта, но и изменили методологию в целом.