Каждый раз, когда подводятся финансовые итоги прошедшего года и готовится соответствующая презентация, люди ломают голову, как бы уместить основные цифры на одной диаграмме. Какова бы ни была сфера деятельности организации, подведение итогов, как правило, начинается с анализа основных финансовых показателей, отдельно по каждому из бизнес-направлений:
Специалисты, знакомые с R, могут использовать ggplot2 для программного построения нужной диаграммы, например, такой как здесь. Для примера взяты цифры за 2012 год из годового отчета компании Unilever. Плановые показатели не относятся к публичным данным, поэтому пришлось их выдумать из головы, установив, для определенности, на уровне «прошлый год + 5%».
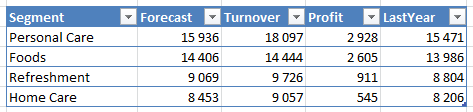
Исходные цифры находятся в Excel и выглядят так (данные в миллионах евро):
Построенная в RStudio диаграмма выглядит следующим образом:

Проверьте диаграмму на интуитивность, и не глядя на цифры, предположите, какому показателю какой элемент диаграммы соответствует, а объяснения будут далее.
- оборот в завершившемся году (фактические цифры);
- установленные ранее планы на завершившийся год (для анализа выполнения);
- оборот годом ранее (для понимания динамики);
- прибыльность.
Специалисты, знакомые с R, могут использовать ggplot2 для программного построения нужной диаграммы, например, такой как здесь. Для примера взяты цифры за 2012 год из годового отчета компании Unilever. Плановые показатели не относятся к публичным данным, поэтому пришлось их выдумать из головы, установив, для определенности, на уровне «прошлый год + 5%».
Исходные цифры находятся в Excel и выглядят так (данные в миллионах евро):
Построенная в RStudio диаграмма выглядит следующим образом:
Проверьте диаграмму на интуитивность, и не глядя на цифры, предположите, какому показателю какой элемент диаграммы соответствует, а объяснения будут далее.
 Эта статья посвящена
Эта статья посвящена  Привет. В этой статье будет рассмотрен способ
Привет. В этой статье будет рассмотрен способ  Привет. В этом посте мы рассмотрим простую модель фильтрации спама с
Привет. В этом посте мы рассмотрим простую модель фильтрации спама с