Некоторое время назад, в силу определенных причин, мне пришла в голову мысль о том, чтобы начать изучать какой-нибудь новый язык программирования. В качестве альтернатив для этого начинания я определил два языка: Java и Python. После продолжительного метания между ними и сопутствующих нытья и долбежки головой о стену (у меня с новыми языками всегда так — сомнения, раздумья, проблема выбора и т.д.), я все-таки остановился на Python. Окей, выбор сделан. Что дальше? А дальше я стал искать материал для изучения…

Борис Егоров @JIghtuse
Пользователь
Изобретаем JPEG
28 мин
Туториал

Вы правильно поняли из названия, что это не совсем обычное описание алгоритма JPEG (формат файла я подробно описывал в статье «Декодирование JPEG для чайников»). В первую очередь, выбранный способ подачи материала предполагает, что мы ничего не знаем не только о JPEG, но и о преобразовании Фурье, и кодировании Хаффмана. И вообще, мало что помним из лекций. Просто взяли картинку и стали думать как же ее можно сжать. Поэтому я попытался доступно выразить только суть, но при которой у читателя будет выработано достаточно глубокое и, главное, интуитивное понимание алгоритма. Формулы и математические выкладки — по самому минимуму, только те, которые важны для понимания происходящего.
Знание алгоритма JPEG очень полезно не только для сжатия изображений. В нем используется теория из цифровой обработки сигналов, математического анализа, линейной алгебры, теории информации, в частности, преобразование Фурье, кодирование без потерь и др. Поэтому полученные знания могут пригодиться где угодно.
Если есть желание, то предлагаю пройти те же этапы самостоятельно параллельно со статьей. Проверить, насколько приведенные рассуждения подходят для разных изображений, попытаться внести свои модификации в алгоритм. Это очень интересно. В качестве инструмента могу порекомендовать замечательную связку Python + NumPy + Matplotlib + PIL(Pillow). Почти вся моя работа (в т. ч. графики и анимация), была произведена с помощью них.
Внимание, трафик! Много иллюстраций, графиков и анимаций (~ 10Мб). По иронии судьбы, в статье про JPEG всего 2 изображения с этим форматом из полусотни.
Разработчик на распутье: как векторизовать?!
5 мин

На тему векторизации написано немало интересного. Вот скажем, отличный пост, который много полезного объясняет по работе автовекторизации, очень рекомендовал бы его к прочтению. Мне интересен другой вопрос. Сейчас в руках у разработчиков большое количество способов, чтобы создать «векторный» код – от чистого ассемблера до того же автовекторизатора. На каком же способе остановиться? Как найти баланс между необходимым и достаточным? Об этом и поговорим.
Блокнот с графическим интерфейсом на языке Go
5 мин
Несмотря на то, что язык Go существует уже не один год, информация о том, как создавать приложения с графическим интерфейсом на этом языке, практически отсутствует. Возможно это вызвано тем, что среди официальных библиотек до сих пор нет библиотеки для работы с GUI. Однако это не значит, что мы не можем создать приложение с пользовательским интерфейсом: существуют библиотеки, предоставляющие такую возможность. Приведу их список. Но есть еще несколько библиотек, не указанных в этом списке. Среди них — Walk, название которого расшифровывается как «Windows Application Library Kit». С его помощью я попробую создать небольшое приложение с пользовательским интерфейсом.
PyFence: верификация типов для Python
2 мин

PyFence — самопальная утилита-библиотека, которая позволяет следить за соответствием типов во время отладки вашего проекта. PyFence берет информацию о типах из docstring'ов функций в стандартном формате Sphinx. То есть, если у вас уже есть документация, больше ничего делать для использования PyFence не нужно!
Например, возьмем следующий класс:
Профилировка производительности OpenMP приложений
7 мин
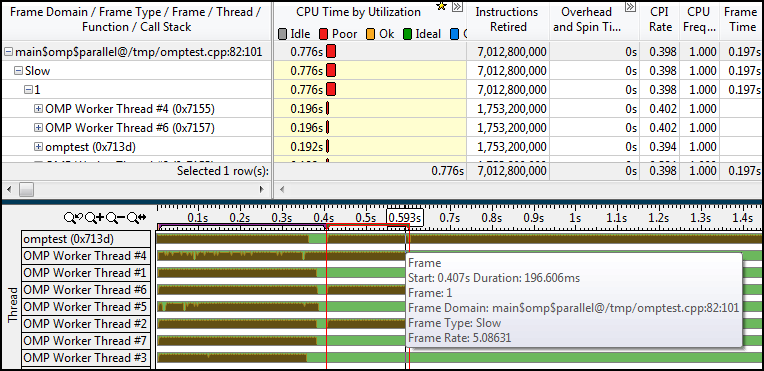
OpenMP – пожалуй, самая распространённая модель параллельного программирования на потоках, на системах с общей памятью. Ценят её за высокоуровневые параллельные конструкции (в сравнении с программированием системных потоков) и поддержку разными производителями компиляторов. Но этот пост не про сам стандарт OpenMP, про него есть много материалов в сети.
Распараллеливают вычисления на OpenMP ради производительности, о чём, собственно, и статья. Точнее, об измерении производительности с помощью Intel VTune Amplifier XE. А именно, как получить информацию о:
- Получении профиля всего OpenMP приложения
- Профиле отдельных параллельных регионов OpenMP (время CPU, горячие функции и т.д.)
- Балансе работы внутри отдельного параллельного региона OpenMP
- Балансе параллельного/последовательного кода
- Уровне гранулярности параллельных задач
- Объектах синхронизации, времени ожидания и передачах управления между потоками
Wireshark — приручение акулы
10 мин
Туториал

Wireshark — это достаточно известный инструмент для захвата и анализа сетевого трафика, фактически стандарт как для образования, так и для траблшутинга.
Wireshark работает с подавляющим большинством известных протоколов, имеет понятный и логичный графический интерфейс на основе GTK+ и мощнейшую систему фильтров.
Кроссплатформенный, работает в таких ОС как Linux, Solaris, FreeBSD, NetBSD, OpenBSD, Mac OS X, и, естественно, Windows. Распространяется под лицензией GNU GPL v2. Доступен бесплатно на сайте wireshark.org.
Установка в системе Windows тривиальна — next, next, next.
Самая свежая на момент написания статьи версия – 1.10.3, она и будет участвовать в обзоре.
Зачем вообще нужны анализаторы пакетов?
Для того чтобы проводить исследования сетевых приложений и протоколов, а также, чтобы находить проблемы в работе сети, и, что важно, выяснять причины этих проблем.
Вполне очевидно, что для того чтобы максимально эффективно использовать снифферы или анализаторы трафика, необходимы хотя бы общие знания и понимания работы сетей и сетевых протоколов.
Так же напомню, что во многих странах использование сниффера без явного на то разрешения приравнивается к преступлению.
Начинаем плаванье
Для начала захвата достаточно выбрать свой сетевой интерфейс и нажать Start.
Путешествие через вычислительный конвейер процессора
16 мин
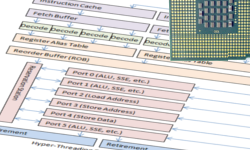 Так как карьера программиста тесно связана с процессором, неплохо бы знать как он работает.
Так как карьера программиста тесно связана с процессором, неплохо бы знать как он работает.Что происходит внутри процессора? Сколько времени уходит на исполнение одной инструкции? Что значит, когда новый процессор имеет 12, или 18, или даже 31-уровневый конвейер?
Программы обычно работают с процессором, как с чёрным ящиком. Инструкции входят и выходят из него по порядку, а внутри совершается некая вычислительная магия.
Программисту полезно знать, что происходит внутри этого ящика, особенно, если он будет заниматься оптимизацией программ. Если вы не знаете какие процессы протекают внутри процессора, как вы сможете оптимизировать под него?
Эта статья рассказывает, как устроен вычислительный конвейер x86 процессора.
TCP(syn-flood)-netmap-generator производительностью 1,5 mpps
14 мин
Дано:
Задача:
Необходимо на данном оборудовании и ОС создать нагрузочную вилку в виде tcp(syn)-генератора трафика производительностью не менее 500kpps.
Решение:
# pciconf -lv | grep -i device | grep -i network
device = I350 Gigabit Network Connection
# dmesg | grep CPU:
CPU: Intel(R) Core(TM)2 Duo CPU E7300 @ 2.66GHz (2666.69-MHz K8-class CPU)
# uname -orp
FreeBSD 9.1-RELEASE amd64
Задача:
Необходимо на данном оборудовании и ОС создать нагрузочную вилку в виде tcp(syn)-генератора трафика производительностью не менее 500kpps.
Решение:
Полиморфизм без виртуальных функций
15 мин
Перевод
В этой статье представлен паттерн, который может быть использован для обеспечения динамического связывания без использования виртуальных функций для вызова перегруженных методов для объектов неоднородного контейнера при его обходе.
Подмена обработчика системного вызова
6 мин
Всем доброго времени суток! Я студентка-второкурсница технического ВУЗа. Пару месяцев назад пришла пора выбирать себе тему курсового проекта. Темы типа калькулятора меня не устраивали. Поэтому я поинтересовалась, есть ли что-нибудь более интересное, и получила утвердительный ответ. «Подмена обработчика системного вызова» — вот моя тема.
Обработчик прерываний (или процедура обслуживания прерываний) — специальная процедура, вызываемая по прерыванию для выполнения его обработки. Эти обработчики вызываются либо по аппаратному прерыванию, либо соответствующей инструкцией в программе, и обычно предназначены для взаимодействия с устройствами или для осуществления вызова функций операционной системы (wiki).
Главная цель, пожалуй, наглядно на рабочей системе посмотреть как оно работает, а не «грызть» сухую теорию. Ну, или как раньше программисты пытались «делать многозадачность» в DOS, переопределяя обработчик событий таймера.
Введение
Обработчик прерываний (или процедура обслуживания прерываний) — специальная процедура, вызываемая по прерыванию для выполнения его обработки. Эти обработчики вызываются либо по аппаратному прерыванию, либо соответствующей инструкцией в программе, и обычно предназначены для взаимодействия с устройствами или для осуществления вызова функций операционной системы (wiki).
Зачем?
Главная цель, пожалуй, наглядно на рабочей системе посмотреть как оно работает, а не «грызть» сухую теорию. Ну, или как раньше программисты пытались «делать многозадачность» в DOS, переопределяя обработчик событий таймера.
Изучаем С используя GDB
6 мин
Туториал
Перевод статьи Аллана О’Доннелла Learning C with GDB.
Исходя из особенностей таких высокоуровневых языков, как Ruby, Scheme или Haskell, изучение C может быть сложной задачей. В придачу к преодолению таких низкоуровневых особенностей C, как ручное управление памятью и указатели, вы еще должны обходиться без REPL. Как только Вы привыкнете к исследовательскому программированию в REPL, иметь дело с циклом написал-скомпилировал-запустил будет для Вас небольшим разочарованием.
Недавно мне пришло в голову, что я мог бы использовать GDB как псевдо-REPL для C. Я поэкспериментировал, используя GDB как инструмент для изучения языка, а не просто для отладки, и оказалось, что это очень весело.
Исходя из особенностей таких высокоуровневых языков, как Ruby, Scheme или Haskell, изучение C может быть сложной задачей. В придачу к преодолению таких низкоуровневых особенностей C, как ручное управление памятью и указатели, вы еще должны обходиться без REPL. Как только Вы привыкнете к исследовательскому программированию в REPL, иметь дело с циклом написал-скомпилировал-запустил будет для Вас небольшим разочарованием.
Недавно мне пришло в голову, что я мог бы использовать GDB как псевдо-REPL для C. Я поэкспериментировал, используя GDB как инструмент для изучения языка, а не просто для отладки, и оказалось, что это очень весело.
Шесть загадок по С++
5 мин
В очередной раз наступив на досадные необязательные грабли, я решил систематизировать свои знания о них. Если вы какое-то время разрабатываете на C++, то можете и не найти здесь ничего нового, но кому-то приведенный в статье материал точно поможет. Если бы я знал это лет пять назад, то однозначно сэкономил бы несколько безвозвратно потерянных дней жизни и нервных клеток.
Чтобы было интереснее, материал представлю в виде простых задачек. Сразу подчеркну, что я не считаю приведенные примеры просчетами языка. Во многом появляется смысл и логика, если вопрос обдумать. Это скорее случаи, когда может отказать интуиция, особенно если голова забита чем-нибудь еще. Есть и пара примеров вида «Ну чего этому компилятору надо, только что то же самое работало!»
И последнее замечание. Это не будут задачи на внимательность типа «Тут я поставил точку с запятой сразу после for — а никто и не заметил». Проблемы не в опечатках. Все необходимые библиотеки можно считать подключенными — не относящийся к описываемой ситуации код я опускал, чтобы не загромождать статью.
Чтобы было интереснее, материал представлю в виде простых задачек. Сразу подчеркну, что я не считаю приведенные примеры просчетами языка. Во многом появляется смысл и логика, если вопрос обдумать. Это скорее случаи, когда может отказать интуиция, особенно если голова забита чем-нибудь еще. Есть и пара примеров вида «Ну чего этому компилятору надо, только что то же самое работало!»
И последнее замечание. Это не будут задачи на внимательность типа «Тут я поставил точку с запятой сразу после for — а никто и не заметил». Проблемы не в опечатках. Все необходимые библиотеки можно считать подключенными — не относящийся к описываемой ситуации код я опускал, чтобы не загромождать статью.
Qt: шаблон для корректной работы с потоками — более качественная реализация
7 мин
В своей предыдущей статье я затронул тему грамотной реализации потоков в Qt и предложил свой вариант. В комментариях мне подсказали более верное направление. Попробовал сделать — получилось и вправду легко и красиво! Я хотел было исправить старую статью, но Хабр повис — и все потерялось. В итоге я решил написать новую версию.
Linux Voice — новый журнал о Linux и OpenSource
1 мин
Недавно на Indiegogo трое бывших авторов и редакторов довольно известного журнала Linux Format запустили кампанию по сбору средств на «совершенно другой журнал» о Linux и OpenSource.
Межпроцедурный анализ и оптимизации (I)
14 мин
Одной из самых интересных и важных компонент современного оптимизирующего компилятора является межпроцедурный анализ и оптимизации. Хороший стиль программирования и необходимость разделения работы между разработчиками диктует необходимость разбиения большого проекта на отдельные модули, в которых основные утилиты реализованы как «черные ящики» для всех основных пользователей. Детали реализации, в лучшем случае, известны паре-тройке конкретных разработчиков, ну а иногда, за давностью лет, и вообще никому неизвестны. (А что поделаешь – специализация, глобализация). Ваш код, зачастую, содержит вызовы внешних функций, тела которых определены во внешних файлах или библиотеках и ваши знания о этих функциях минимальны. Ну и помимо этого при разработке больших проектов плодятся всякие глобальные переменные, с помощью которых компоненты большого проекта обмениваются ценной информацией, и для того, чтобы разобраться в работе вашей части кода в случае каких-то проблем, бывает необходимо перелопатить массу кода. Очевидно, что все это сильно осложняет и работу оптимизирующего компилятора. Какие негативные эффекты порождает модульность и есть ли в компиляторе специальные средства для их преодоления – тема для большого разговора. Сейчас я попытаюсь начать такой разговор. Я расскажу о некоторых интересных особенностях работы оптимизирующего компилятора на примере работы компилятора Intel. Ориентироваться буду на OS Windows, поэтому опции компилятора привожу характерные для этой платформы. Ну и чтобы облегчить себе жизнь, я иногда буду использовать аббревиатуры IPA для межпроцедурного анализа и IPO для межпроцедурных оптимизаций. А начну я с рассказа о моделях межпроцедурного анализа и графе вызовов.
Повесть о настоящем Интернете
13 мин
Туториал
Abstract: Рассказ про устройство Интернета, как «сети сетей» в виде текста для чтения, без двоичной системы счисления и нюансов BGP. Большая часть расказа будет не про процесс общения ноутбука с точкой доступа, а о том, что происходит после того, как данные пройдут «шлюз по умолчанию». Предупреждаю, букв много.
Маленький провокативный вброс: ни один из читателей этой статьи к Интернету не подключен. Все подключены к сети своего провайдера, и не более. Подключение к Интернету дорогое, его сложно делать, вам потребуется очень крутое оборудование, несколько договоров с несколькими операторами связи и квалифицированные сотрудники. Простому домашнему пользователю это никак и никогда не светит. Не говоря уже о том, что в Интернете может быть не больше 4 миллиардов подключившихся (а до недавнего времени было даже «не более 65536») [1]. Даже если весь Интернет перейдёт на ipv6, это число не поменяется.
Вот число подключившихся к Интернету [2]:
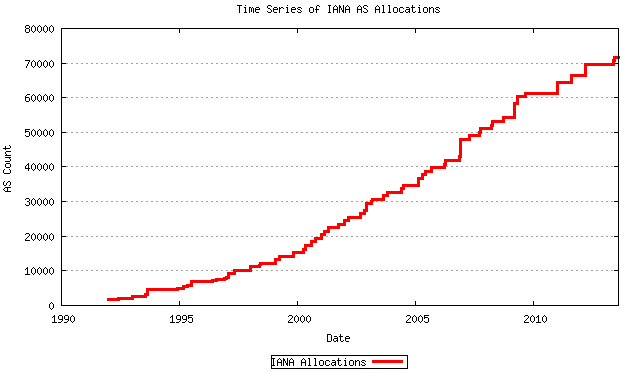
По оси Y — число в штуках. Штуках, штуках. И вас в этом числе не посчитали.
Почему?
Дело в том, что Internet — это, если переводить буквально, «межсетье». Сеть Сетей. И участниками Интернета являются не пользователи (их компьютеры, планшеты, микроволновки с wifi и т.д.), а сети. Сети и только сети участвуют в работе Интернета. Интернет — это то, что связывает разные сети между друг другом.
Вступление
Маленький провокативный вброс: ни один из читателей этой статьи к Интернету не подключен. Все подключены к сети своего провайдера, и не более. Подключение к Интернету дорогое, его сложно делать, вам потребуется очень крутое оборудование, несколько договоров с несколькими операторами связи и квалифицированные сотрудники. Простому домашнему пользователю это никак и никогда не светит. Не говоря уже о том, что в Интернете может быть не больше 4 миллиардов подключившихся (а до недавнего времени было даже «не более 65536») [1]. Даже если весь Интернет перейдёт на ipv6, это число не поменяется.
Вот число подключившихся к Интернету [2]:
По оси Y — число в штуках. Штуках, штуках. И вас в этом числе не посчитали.
Почему?
Дело в том, что Internet — это, если переводить буквально, «межсетье». Сеть Сетей. И участниками Интернета являются не пользователи (их компьютеры, планшеты, микроволновки с wifi и т.д.), а сети. Сети и только сети участвуют в работе Интернета. Интернет — это то, что связывает разные сети между друг другом.
Хозяйка из настоящего — интегрированная графика (Intel GPU) 2013 или «миелофон у меня!»
7 мин

В феврале, когда многие еще раздумывали о том, не пора ли выкинуть новогоднюю елку, я решила, что уже пора познакомить читателей хабры с тем, что их ждет летом, и создала пост Гостья из будущего, рассказывающий про интегрированную графику (GPU) на тот момент готовящихся к выходу процессоров Intel под кодовым названием Haswell.
А сейчас, когда интегрированная графика Intel уже не гостья из будущего, а хозяйка из настоящего, и один из таких GPU находится в ультрабуке, на котором я пишу эти строки, можно, не ограничивась рамками секретности, рассказать про
Linux Kernel EFI Boot Stub или «Сам себе загрузчик»
10 мин

Введение
Прочитав недавнюю статью Загрузка ОС Linux без загрузчика, понял две вещи: многим интересна «новинка», датируемая аж 2011 годом; автор не описал самого основного, без чего, собственно, и работать ничего не будет в некоторых случаях. Также была ещё одна статья, но либо она уже устарела, либо там опять таки много лишнего и недосказанного одновременно.
А конкретно, был упущен основной момент — сборочная опция ядра CONFIG_EFI_STUB. Так как в последних версиях U(lu/ku/edu/*etc*)buntu эта опция по умолчанию уже включена, никаких подозрений у автора не появилось.
Насколько мне известно, на текущий момент она включена в дистрибутивах указанных версий и выше: Arch Linux, Fedora 17, OpenSUSE 12.2 и Ubuntu 12.10. В комментах ещё упомянули, что Debian с ядром 2.6 умеет, но это не более, чем бэкпорт с последних версий. На этих дистрибутивах пересобирать вообще ничего не нужно! А ведь на других CONFIG_EFI_STUB, скорее всего, либо вообще отсутствует, т. к. опция доступна только с ядра версии 3.3.0 и выше, либо выключена по умолчанию. Соответственно, всё, описанное ниже, справедливо для ядра, собранного с опцией CONFIG_EFI_STUB.
Итак, что же такое Linux Kernel EFI Boot Stub?
Общая информация
А ни что иное, как… «exe-файл»!
Введение в анализ сложности алгоритмов (часть 3)
6 мин
Туториал
Перевод
От переводчика: данный текст даётся с незначительными сокращениями по причине местами излишней «разжёванности» материала. Автор абсолютно справедливо предупреждает, что отдельные темы могут показаться читателю чересчур простыми или общеизвестными. Тем не менее, лично мне этот текст помог упорядочить имеющиеся знания по анализу сложности алгоритмов. Надеюсь, что он окажется полезен и кому-то ещё.
Из-за большого объёма оригинальной статьи я разбила её на части, которых в общей сложности будет четыре.
Я (как всегда) буду крайне признательна за любые замечания в личку по улучшению качества перевода.
Опубликовано ранее:
Часть 1
Часть 2

Если вы знаете, что такое логарифмы, то можете спокойно пропустить этот раздел. Глава предназначается тем, кто незнаком с данным понятием или пользуется им настолько редко, что уже забыл что там к чему. Логарифмы важны, поскольку они очень часто встречаются при анализе сложности. Логарифм — это операция, которая при применении её к числу делает его гораздо меньше (подобно взятию квадратного корня). Итак, первая вещь, которую вы должны запомнить: логарифм возвращает число, меньшее, чем оригинал. На рисунке справа зелёный график — линейная функция
Из-за большого объёма оригинальной статьи я разбила её на части, которых в общей сложности будет четыре.
Я (как всегда) буду крайне признательна за любые замечания в личку по улучшению качества перевода.
Опубликовано ранее:
Часть 1
Часть 2
Логарифмы
Если вы знаете, что такое логарифмы, то можете спокойно пропустить этот раздел. Глава предназначается тем, кто незнаком с данным понятием или пользуется им настолько редко, что уже забыл что там к чему. Логарифмы важны, поскольку они очень часто встречаются при анализе сложности. Логарифм — это операция, которая при применении её к числу делает его гораздо меньше (подобно взятию квадратного корня). Итак, первая вещь, которую вы должны запомнить: логарифм возвращает число, меньшее, чем оригинал. На рисунке справа зелёный график — линейная функция
f(n) = n, красный — f(n) = sqrt(n), а наименее быстро возрастающий — f(n) = log(n). Далее: подобно тому, как взятие квадратного корня является операцией, обратной возведению в квадрат, логарифм — обратная операция возведению чего-либо в степень.