Здравствуйте, хабровчане! Предлагаю вашему вниманию перевод статьи «How a single PostgreSQL config change improved slow query performance by 50x» автора Pavan Patibandla. Она очень сильно мне помогла улучшить производительность PostgreSQL.
В Amplitude наша цель — предоставить простую в использовании интерактивную аналитику продуктов, чтобы каждый мог найти ответы на свои вопросы о продукте. Чтобы обеспечить удобство работы, Amplitude должен быстро предоставить эти ответы. Поэтому, когда один из наших клиентов пожаловался на то, сколько времени потребовалось для загрузки раскрывающегося списка свойств события в пользовательском интерфейсе Amplitude, мы приступили к детальному изучению проблемы.
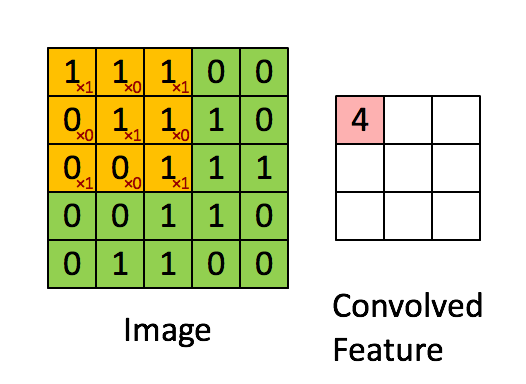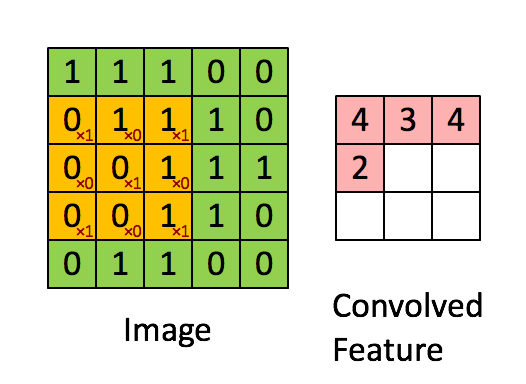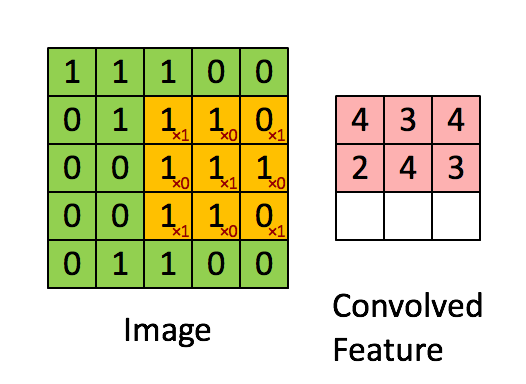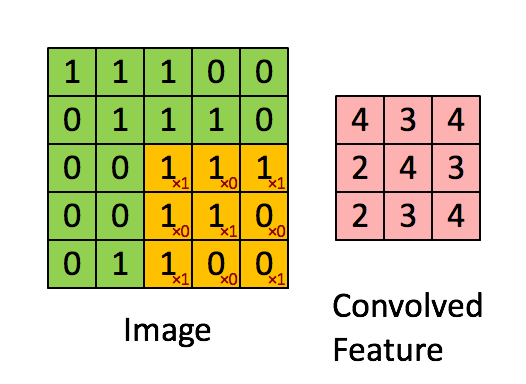
Отслеживая задержку на разных уровнях, мы поняли, что одному конкретному запросу PostgreSQL потребовалось 20 секунд для завершения. Для нас это стало неожиданностью, так как обе таблицы имеют индексы в соединяемом столбце.
Медленный запрос

В Amplitude наша цель — предоставить простую в использовании интерактивную аналитику продуктов, чтобы каждый мог найти ответы на свои вопросы о продукте. Чтобы обеспечить удобство работы, Amplitude должен быстро предоставить эти ответы. Поэтому, когда один из наших клиентов пожаловался на то, сколько времени потребовалось для загрузки раскрывающегося списка свойств события в пользовательском интерфейсе Amplitude, мы приступили к детальному изучению проблемы.
Отслеживая задержку на разных уровнях, мы поняли, что одному конкретному запросу PostgreSQL потребовалось 20 секунд для завершения. Для нас это стало неожиданностью, так как обе таблицы имеют индексы в соединяемом столбце.
Медленный запрос






 В самом сердце информационно-поисковых систем Meltwater и
В самом сердце информационно-поисковых систем Meltwater и