
Представляю вашему вниманию вторую лекцию из семи прочитанных лауреатом нобелевской премии профессором Ричардом Фейнманом в Корнелльском университете в 1964г, которая называлась «Связь математики и физики».

Я убежден, что не существует популярной науки, есть только популярная ее интерпретация. И это не самый мною любимый жанр, сейчас я практически не читаю научно популярных книг, наука не заслуживает того чтобы скользить вечно по поверхности. Однако какие-то книги я все-таки читал и вам советую, много и восхитительно писали: Бор с Эйнштейном (любой популярный текст, особенно советую их переписку), Паули (переписка), Гейзенберг «Часть и целое» (это уже больше философия в стиле Витгенштейна), сам Витгенштейн, Куайн «Две догмы эмпиризма», Дэвид Дойч «Структура реальности» (с оговорками- совершенно замечательная вещь), по квантовой механике опять же Фейнман «КЭД — удивительное свойство света и вещества», по логике — Хофштадтер GEB (Гедель, Эшер, Бах) — книга моего детства, по биохимии Франк-Каменецкий «Самая главная молекула» — замечательная книга про ДНК, конечно советую Джеймса Уотсона «Двойная спираль. Воспоминания об открытии структуры ДНК».
И еще масса книг, которые я не вспомнил, от всех этих книг захватывает дух, но к сожалению на полках в книжных магазинах они растворились в бестолковом шуме какой-то сомнительной около научной литературы. И я не очень понимаю что собственно читают сейчас люди интересующиеся наукой.
Я убежден, что не существует популярной науки, есть только популярная ее интерпретация. И это не самый мною любимый жанр, сейчас я практически не читаю научно популярных книг, наука не заслуживает того чтобы скользить вечно по поверхности. Однако какие-то книги я все-таки читал и вам советую, много и восхитительно писали: Бор с Эйнштейном (любой популярный текст, особенно советую их переписку), Паули (переписка), Гейзенберг «Часть и целое» (это уже больше философия в стиле Витгенштейна), сам Витгенштейн, Куайн «Две догмы эмпиризма», Дэвид Дойч «Структура реальности» (с оговорками- совершенно замечательная вещь), по квантовой механике опять же Фейнман «КЭД — удивительное свойство света и вещества», по логике — Хофштадтер GEB (Гедель, Эшер, Бах) — книга моего детства, по биохимии Франк-Каменецкий «Самая главная молекула» — замечательная книга про ДНК, конечно советую Джеймса Уотсона «Двойная спираль. Воспоминания об открытии структуры ДНК».
И еще масса книг, которые я не вспомнил, от всех этих книг захватывает дух, но к сожалению на полках в книжных магазинах они растворились в бестолковом шуме какой-то сомнительной около научной литературы. И я не очень понимаю что собственно читают сейчас люди интересующиеся наукой.

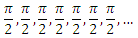
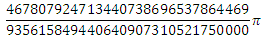
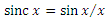 (ну и 1 при x = 0, хотя неважно). Тогда каждый член ряда — это значение следующего интеграла в цепочке:
(ну и 1 при x = 0, хотя неважно). Тогда каждый член ряда — это значение следующего интеграла в цепочке: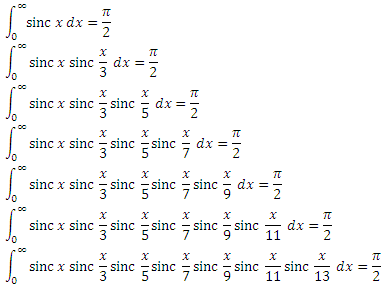




 Здравствуйте, коллеги! Это блог открытой русскоговорящей
Здравствуйте, коллеги! Это блог открытой русскоговорящей 









{kind=link}