Так называемое машинное обучение не перестает удивлять, однако для математиков причина успеха по-прежнему не совсем понятна.
Как-то пару лет назад за ужином, на который меня пригласили, выдающийся специалист в области дифференциальной геометрии Эудженио Калаби вызвался посвятить меня в тонкости весьма ироничной теории о разнице между приверженцами чистой и прикладной математики. Так, зайдя в своих исследованиях в тупик, сторонники чистой математики нередко сужают проблематику, пытаясь таким образом обойти препятствие. А их коллеги, специализирующиеся на прикладной математике, приходят к выводу, что сложившаяся ситуация указывает на необходимость продолжить изучение математики с целью создания более эффективных инструментов.
Мне всегда нравился такой подход; ведь благодаря ему становится понятно, что прикладные математики всегда сумеют задействовать новые концепции и структуры, которые то и дело появляются в рамках фундаментальной математики. Сегодня, когда на повестке дня стоит вопрос изучения «больших данных» – слишком объемных или сложных блоков информации, которые не удается понять, используя лишь традиционные методы обработки данных – тенденция тем более не утрачивает своей актуальности.

 Это пятая статья из цикла «Теория категорий для программистов». Предыдущие статьи уже публиковались на Хабре в переводе
Это пятая статья из цикла «Теория категорий для программистов». Предыдущие статьи уже публиковались на Хабре в переводе 

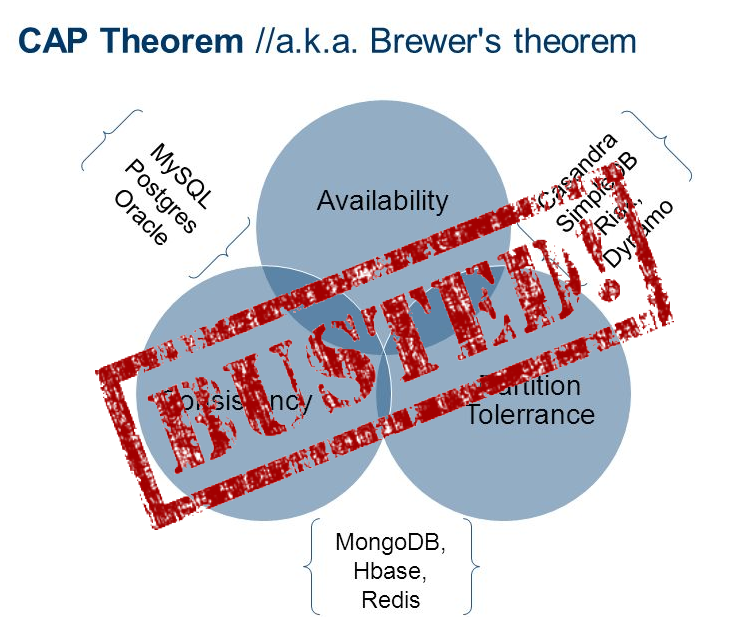
 Реляционные базы данных (РБД) используются повсюду. Они бывают самых разных видов, от маленьких и полезных SQLite до мощных Teradata. Но в то же время существует очень немного статей, объясняющих принцип действия и устройство реляционных баз данных. Да и те, что есть — довольно поверхностные, без особых подробностей. Зато по более «модным» направлениям (большие данные, NoSQL или JS) написано гораздо больше статей, причём куда более глубоких. Вероятно, такая ситуация сложилась из-за того, что реляционные БД — вещь «старая» и слишком скучная, чтобы разбирать её вне университетских программ, исследовательских работ и книг.
Реляционные базы данных (РБД) используются повсюду. Они бывают самых разных видов, от маленьких и полезных SQLite до мощных Teradata. Но в то же время существует очень немного статей, объясняющих принцип действия и устройство реляционных баз данных. Да и те, что есть — довольно поверхностные, без особых подробностей. Зато по более «модным» направлениям (большие данные, NoSQL или JS) написано гораздо больше статей, причём куда более глубоких. Вероятно, такая ситуация сложилась из-за того, что реляционные БД — вещь «старая» и слишком скучная, чтобы разбирать её вне университетских программ, исследовательских работ и книг.