- Вы работали с Кафкой?
- Нет, только читали.
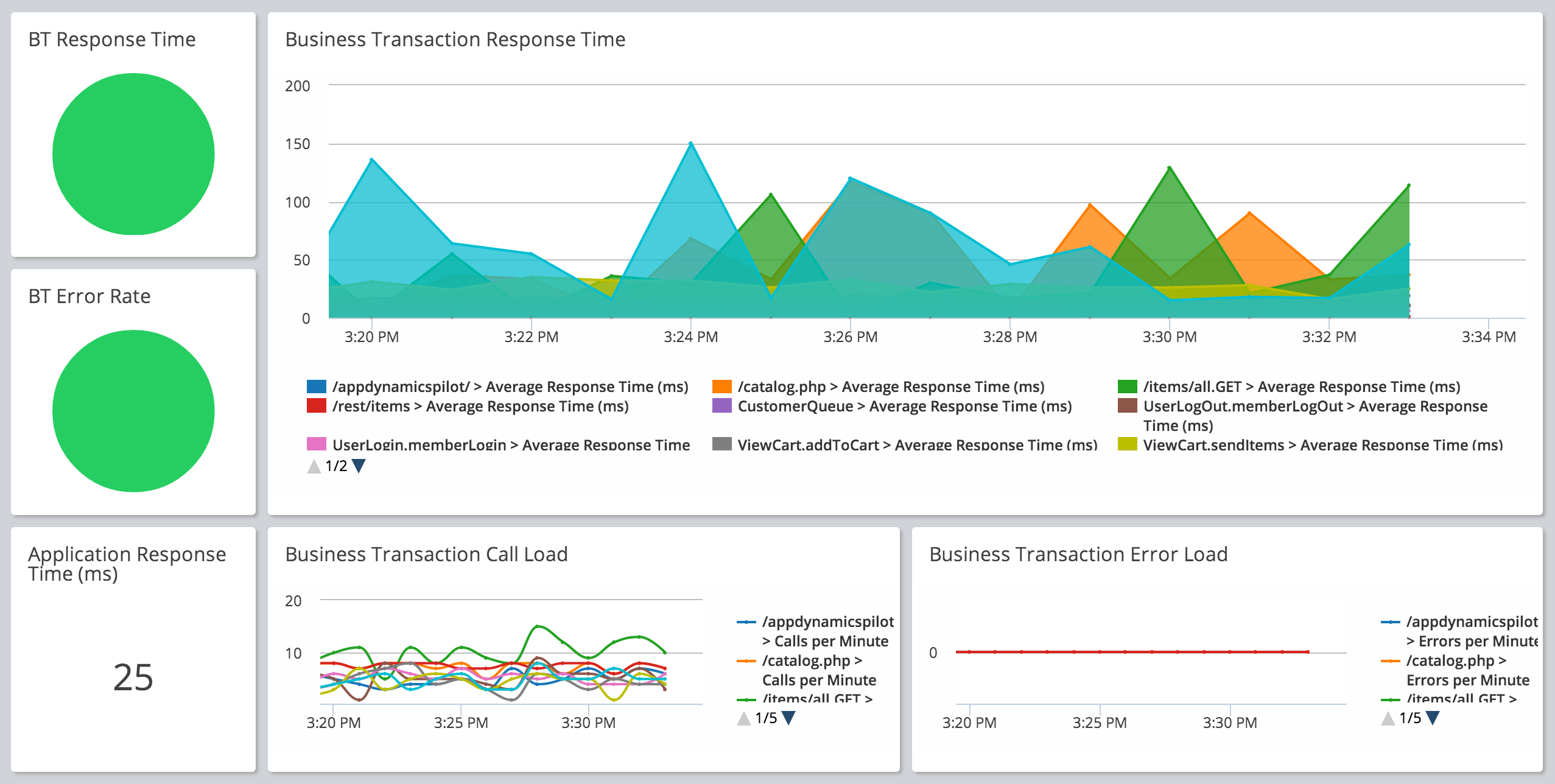
За несколько десятилетий развития ИТ систем разработчики накопили огромный опыт хранения и обработки данных. Различные СУБД позволяют с помощью запросов извлекать нужные данные за определенный период и обрабатывать их так как необходимо. Однако, со временем увеличились вычислительные мощности серверов, пропускная способность каналов связи, и соответственно, возникла необходимость обрабатывать бОльшие объемы данных за единицу времени. И тут выяснилось, что при всем многообразии различных решений для хранения данных, отсутствуют решения для обработки непрерывных потоков больших объемов данных. Для решения этой проблемы стали появляться различные системы, такие как системы обмена сообщениями и агрегирования журналов. Но они не могли в полной мере обеспечить нужную производительность на больших, непрерывных потоках данных.
Для решения этой проблемы в LinkedIn решили создать нужное решение что называется с нуля. Разработчики решили отказаться от хранения больших объемов данных, как в реляционных базах данных, хранилищ пар «ключ/значение», поисковых индексов или кэшей, а рассматривать данные как непрерывно развивающийся и постоянно растущий поток и проектировать информационные системы и архитектуру данных — на этой основе. Так появилось решение Apache Kafka, которое изначально использовалось для обеспечения функционирования работающих в реальном масштабе времени приложений и потоков данных социальной сети. Но сейчас это решение используется во многих крупных компаниях. Посмотрим подробнее как оно устроено.