
Решение экзамена в ШАД от 09.06.2018
Автор решения: Лыков Александр, кандидат физико-математических наук.
Условия и видео-решения других лет доступны на сайте: https://shadhelper.notion.site/e363616a9acd4591afdf687ba951d3ea

Пользователь
Решение экзамена в ШАД от 09.06.2018
Автор решения: Лыков Александр, кандидат физико-математических наук.
Условия и видео-решения других лет доступны на сайте: https://shadhelper.notion.site/e363616a9acd4591afdf687ba951d3ea
Data Science является одной из самых востребованных, высокооплачиваемых и перспективных профессий в современном мире. Как следствие, конкуренция за вакансии в этой области очень высока. Если вы ищете работу в качестве Data Science Junior, подготовка к собеседованию — это один из самых важных этапов. В этой статье мы рассмотрим, что нужно изучить к собеседованию на Data Science Junior и что ждут работодатели.

Развитие искусственного интеллекта сейчас переживает бурный рост, и сфера его применения постоянно расширяется, проникая в области, ранее никак не связанные с ИТ.
Хорошим примером такой экспансии является спорт.
Не так давно появился термин Sport tech и количество проектов значительно выросло за последние несколько лет.
Волейбол — перспективное направление в спортивной аналитике. Один из самых массовых видов спорта, распространен в очень многих странах.
Итак, у нас есть видеозапись волейбольной игры. С какой целью она обычно делается? Возможно, чтобы показать друзьям или пересматривать лучшие моменты долгими зимними вечерами. Но наверное, в сыром виде, запись не очень годится для этого. Ведь скорее всего, первые минут десять игроки будут переодеваться и разминаться, а после каждого розыгрыша будет проходить минута‑другая, пока кто‑то сбегает за мячом.
В общем, мы подходим к очевидной цели — избавиться от всего скучного и оставить только самое интересное. Ок, стратегия ясна, переходим к тактике.
Для стороннего зрителя (которым конечно является искуственный интеллект) есть несколько маркеров для привлечения внимания: игроки, мяч, судья, табло. Любой из этих объяектов может быть подвергнут аналитике. Но сегодня мы поговорим о мяче.
Связь зрительского интереса и мяча вполне очевидна: мяч летает — мы смотрим. Нет мяча — некуда смотреть. В общем, понятно, что нам надо вырезать все кадры, где мяч не летает и тогда это можно будет смотреть без зевоты.
Всем привет! Перед началом статьи сразу скажу:
САМЫЙ ВАЖНЫЙ ДИСКЛЕЙМЕР: естественно, покупая смс на чужой номер вы полностью компрометируете безопасность своего аккаунта. Мало ли кто его потом еще купит для получения доступа. Поэтому, помните, что представленный в данной статье способ получения доступа - это только на "поиграться". Не стоит вводить туда свои реальные почты и использовать это в работе, так как полученный доступ может быть в любой момент взломан/прикрыт.
Но да ладно, приступим. Здесь без всякого объяснения того что такое ChatGPT - кому надо тот знает. В этой статье я хочу поделиться путем который вас за 30Р может к этому боту привести. Вдаваться в детали бота я не хочу, это чисто статья для ребят которые хотят без лишних запар пройти путь человека который доступ к боту уже получил :)
Как и многих вокруг, меня удивила новая технология от Open AI. Попытался зайти и зарегистрироваться через гугл, но...

В этом посте рассмотрим в деталях, как непосредственно использовать гугл таблицы в качестве базы данных. Попробуем написать бота, который забирает вопросы квиза с вариантами ответов из гугл таблицы и записывает ответы назад.
В предыдущих статьях мы разобрали много аспектов, связанных с SSL. Теперь пришло время посмотреть на методы, которые используют достаточно очевидное, на первый взгляд, знание - одна и та же картинка похожа, а разные картинки - разные. Это основная идея методов с contrastive подходом. Ниже мы разберём более подробно как эту идею можно использовать при конфигурации фреймворка обучения.
Напомню, что это четвертая статья из цикла про SSL в Computer Vision.

Привет,
Это статья нашего бывшего коллеги, Андрея Лукьяненко, который работал над проектом по созданию медицинского чат-бота. Андрей покинул нашу компанию по собственному желанию (и с большим сожалением для нас), но несмотря на это, мы решили опубликовать его материал. Мы уверены, что эта статья будет полезна всем, кто работает над созданием специализированных чат-ботов.
Итак, передаем слово Андрею Лукьяненко, бывшему техлиду MTS AI.
В последние годы рынок телемедицины (дистанционных медицинских услуг) и в целом медтеха активно растет, и пандемия коронавируса только ускорила его развитие. Такие технологии востребованы, потому что они относительно дешевы, доступны вне зависимости от места проживания пациента и дают возможность самостоятельно выбирать врачей.

Привет Хабр! Меня зовут Олег Сидоршин, я стажер (с марта буду джуном) в Лаборатории машинного обучения Альфа-Банка. До перехода в коммерческую разработку для практики своих навыков я активно участвовал в Kaggle-соревнованиях.
Этот пост — ретроспектива о крупном соревновании по компьютерному зрению Petfinder Pawpularity Prediction, которое проходило в начале 2022 года. Расскажу, как сражался на одном уровне с Nvidia с их холодильниками, что помогло пережить полет с 400+ места на 13, и конечно же, о главных советах и уроках для улучшения качества ваших ML-систем на соревнованиях и в рабочей практике, даже если у вас почти нет бюджета.
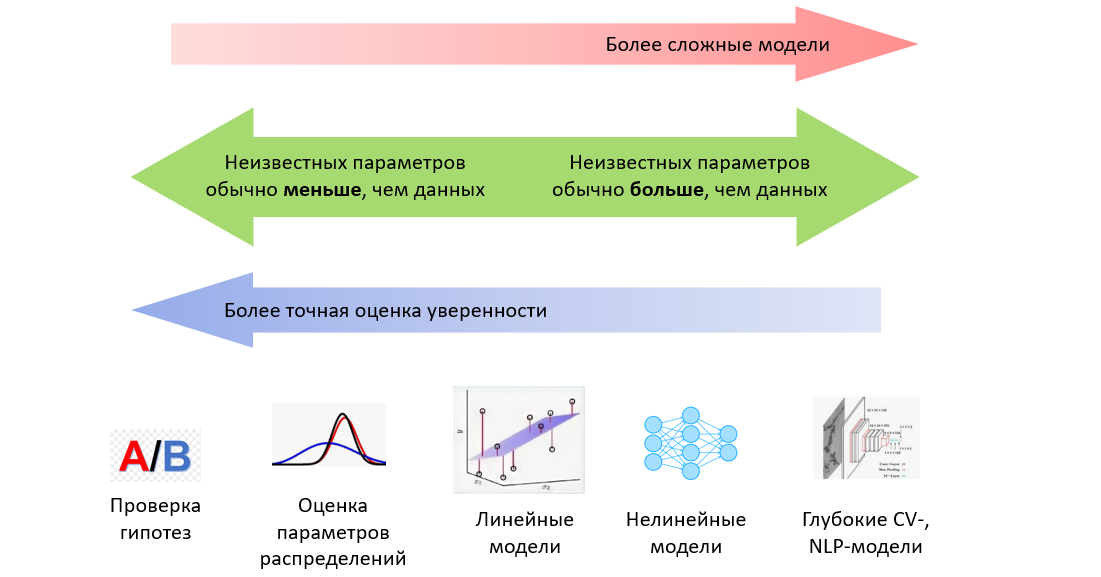
В данной статье мы подробно рассмотрим вероятностную постановку задачи машинного обучения: что такое распределение данных, дискриминативная модель, i.i.d.-гипотеза и метод максимизации правдоподобия, что такое регрессия Пуассона и регрессия с оценкой уверенности, и как нормальное распределение связано с минимизацией среднеквадратичного отклонения.
В следующей части рассмотрим метод максимизации правдоподобия в классификации: в чем роль кроссэнтропии, функций сигмоиды и softmax и как кроссэнтропия связана с "расстоянием" между распределениями вероятностей и почему модель регрессии тоже обучается через минимизацию кроссэнтропии. Затем перейдем от метода максимизации правдоподобия к байесовскому выводу и его различным приближениям.
Данная серия статей не является введением в машинное обучение и предполагает знакомство читателя с основными понятиями. Задача статей - рассмотреть машинное обучение с точки зрения теории вероятностей, что позволит по новому взглянуть на проблему, понять связь машинного обучения со статистикой и лучше понимать формулы из научных статей. Также на описанном материале строятся более сложные темы, такие как вариационные автокодировщики (Kingma and Welling, 2013), нейробайесовские методы (Müller et al., 2021) и даже некоторые теории сознания (Friston et al., 2022).

Пожалуй, самый простой и понятный разбор основ Теории игр, из всех, которые я встречал, с демонстрацией результатов нескольких наиболее популярных игр на питоновских библиотеках nashpy и axelrod.
Это перевод сразу двух статей Mythili Krishnan , аналитика с medium.com
Дочитавших до конца и желающих быстро испытать пару стратегий, ждет небольшой бонус...
+ поучаствуйте в опросе, что вы вообще думаете о теории игр?

Нынче никого не удивишь достижениями искусственного интеллекта машинного обучения (ML) в самых разных областях. При этом доверчивые граждане редко задают два вопроса: (i) а какая собственно цена экспериментов и финальной системы и (ii) имеет ли сделанное хоть какую-то целесообразность? Самым важным компонентом такой цены являются как ни странно цена на железо и зарплаты людей. В случае если это все крутится в облаке, нужно еще умножать стоимость железа в 2-3 раза (маржа посредника).
И тут мы неизбежно приходим к тому, что несмотря на то, что теперь даже в официальные билды PyTorch добавляют бета-поддержку ROCm, Nvidia де-факто в этом цикле обновления железа (и скорее всего следующем) остается монополистом. Понятно, что есть TPU от Google и мифические IPU от Graphcore, но реальной альтернативы не в облаке пока нет и не предвидится (первая версия CUDA вышла аж 13 лет назад!).
Что делать и какие опции есть, когда зачем-то хочется собрать свой "суперкомпьютер", но при этом не хочется платить маржу, заложенную в продукты для ультра-богатых [мысленно вставить комментарий про госдолг США, майнинг, крах Бреттон-Вудсткой системы, цены на здравоохранение в странах ОЭСР]? Чтобы попасть в топ-500 суперкомпьютеров достаточно купить DGX Superpod, в котором от 20 до 100 с лишним видеокарт. Из своей практики — де-факто серьезное машинное обучение сейчас подразумевает карточки Nvidia в количестве примерно 8-20 штук (понятно что карточки бывают разные).

Беспилотные автомобили, продвинутые голосовые ассистенты, рекомендательные системы – это только малая часть тех классных продуктов, которые создаются с помощью инженеров по машинному обучению и, думаю, не для кого не секрет, что за кулисами сего чуда стоит математика. Именно она играет главную роль в понимании алгоритмов машинного и глубокого обучения.
Машинное обучение держится на трёх основных столпах:
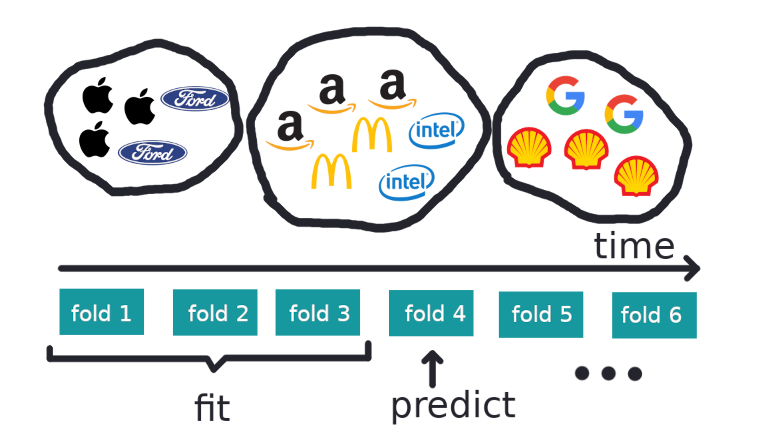
В последнее время все больше людей приходит к тому, чтобы не держать деньги под матрасом, а куда-то их инвестировать в надежде сохранить и преумножить свой капитал. Вариант с матрасом плох тем, что с повышением цен на товары и услуги(инфляция) покупательная способность денег падает и через какое-то время купить на них можно значительно меньше, чем раньше. Есть много вариантов, куда вложить деньги(недвижимость, банковский вклад, ценные металлы), но в последнее время популярным становится инвестирование в акции. Только у брокера Тинькофф Инвестиции за несколько лет число клиентов превысило 3.5 млн. В статье я постараюсь описать свой подход к выбору бумаг и поделюсь инструментами, которые для этого разрабатываю.

Технологический прогресс не стоит на месте, особенно если это касается области IT. Еще в 2014 году, когда Google открыл исходный код проекта Kubernetes, который вобрал в себя лучшее из Borg и Omega - внутренних систем Google, его мало кто знал и использовал. Но прошло 7 лет и K8S (он же Kubernetes) стал успешным open-source проектом, который используется по всему миру. В большинстве компаний инфраструктура построена на K8S - от маленьких проектов до огромных кластеров и облаков, которые обеспечивают бесперебойную доступность сервисов. Давайте коснемся Kubernetes и расскажем, как им пользоваться на практике. Но сначала надо спросить, а что такое этот ваш Kubernetes и для чего он собственно нужен. Подойдет ли он для ваших проектов.
Мы рассмотрели ранее в цикле статей про SSL основные подходы к обучению моделей без разметки. Пока что за скобками остались методы, основанные на кластеризации, и настало время это исправить. В статье рассмотрим основные подходы как учитывать весь датасет при обучениии и пытаться растащить его в пространстве эмбеддингов.
Напомню, что это пятая статья из цикла про SSL в Computer Vision.

Любой, кто хоть раз обучал нейронки, знает, что принято на каждой эпохе шаффлить датасет, чтобы не повторялся порядок батчей. А зачем это делать? Обычно это объясняют тем, что шаффлинг улучшает генерализацию сетей, делает точнее эстимейт градиента на батчах и уменьшает вероятность застревания SGD в локальных минимумах. Здесь можно посмотреть визуализацию поведения градиентов батчей с шаффлингом и без шаффлинга. Ну и самый простой и традиционный для ML аргумент - наши эксперименты подтверждают, что отключение шаффлинга действительно ухудшает метрики, так что проверяйте, не забагован ли ваш трейн-луп ? Еще больше полезной информации в нашем telegram-канале Варим ML


Прим. Wunder Fund: короткая статья о том, как эмбеддинги могут помочь при работе с категориальными признаками и сетками. А если вы и так умеете в сетки — то мы скоро открываем набор рисерчеров и будем рады с вами пообщаться, stay tuned.
Создание эмбеддингов признаков (feature embeddings) — это один из важнейших этапов подготовки табличных данных, используемых для обучения нейросетевых моделей. Об этом подходе к подготовке данных, к сожалению, редко говорят в сферах, не связанных с обработкой естественных языков. И, как следствие, его почти полностью обходят стороной при работе со структурированными наборами данных. Но то, что его, при работе с такими данными, не применяют, ведёт к значительному ухудшению точности моделей. Это стало причиной появления заблуждения, которое заключается в том, что алгоритмы градиентного бустинга, вроде того, что реализован в библиотеке XGBoost, это всегда — наилучший выбор для решения задач, предусматривающих работу со структурированными наборами данных. Нейросетевые методы моделирования, улучшенные за счёт эмбеддингов, часто дают лучшие результаты, чем методы, основанные на градиентном бустинге. Более того — обе группы методов показывают серьёзные улучшения при использовании эмбеддингов, извлечённых из существующих моделей.
Эта статья направлена на поиск ответов на следующие вопросы:
1. Что такое эмбеддинги признаков?
2. Как они используются при работе со структурированными данными?
3. Если использование эмбеддингов — это столь мощная методика — почему она недостаточно широко распространена?
4. Как создавать эмбеддинги?
5. Как использовать существующие эмбеддинги для улучшения других моделей?
В этой статье вы найдете материалы очных курсов «Deep Learning in NLP», которые запускались командой DeepPavlov в 2018-2019 годах и которые являлись частичной адаптацией Stanford NLP course — cs224n. Статья будет полезна любым специалистам, погружающимися в обработку текста с помощью машинного обучения. Благодарю физтехов, разрабатывающих открытую библиотеку для разговорного искусственного интеллекта в МФТИ, и Moryshka за разрешение осветить эту тему на Хабре в нашем ods-блоге.
