Мне наступили на больную мозоль, сделав некий обзорный пост по нескольким фантастическим сериалам.
А так как субботним вечером делать особенно нечего, давайте-ка я сделаю свой, более полный.
Да, будут спойлеры, имейте в виду.
Да, и очень много картинок! Трафик!
Начнём со Stargate
Целое семейство сериалов, начавшихся с одноимённого фильма.
Это во-первых, конечно,
Stargate SG-1
10/10

А так как субботним вечером делать особенно нечего, давайте-ка я сделаю свой, более полный.
Да, будут спойлеры, имейте в виду.
Да, и очень много картинок! Трафик!
Начнём со Stargate
Целое семейство сериалов, начавшихся с одноимённого фильма.
Это во-первых, конечно,
Stargate SG-1
10/10
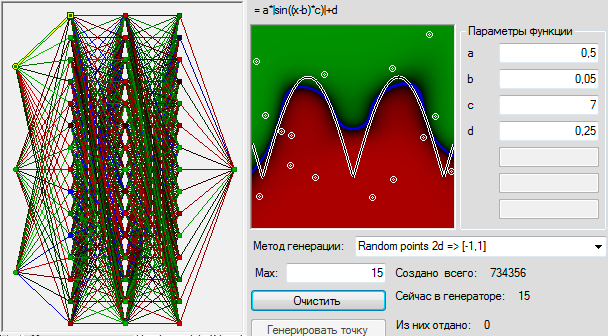 В последнее время на Хабре появилось множество статей о нейронных сетях. Из них очень интересными показались статьи о Перцептроне Розенблатта:
В последнее время на Хабре появилось множество статей о нейронных сетях. Из них очень интересными показались статьи о Перцептроне Розенблатта: