→ Демо: ссылка
→ Исходники: ссылка
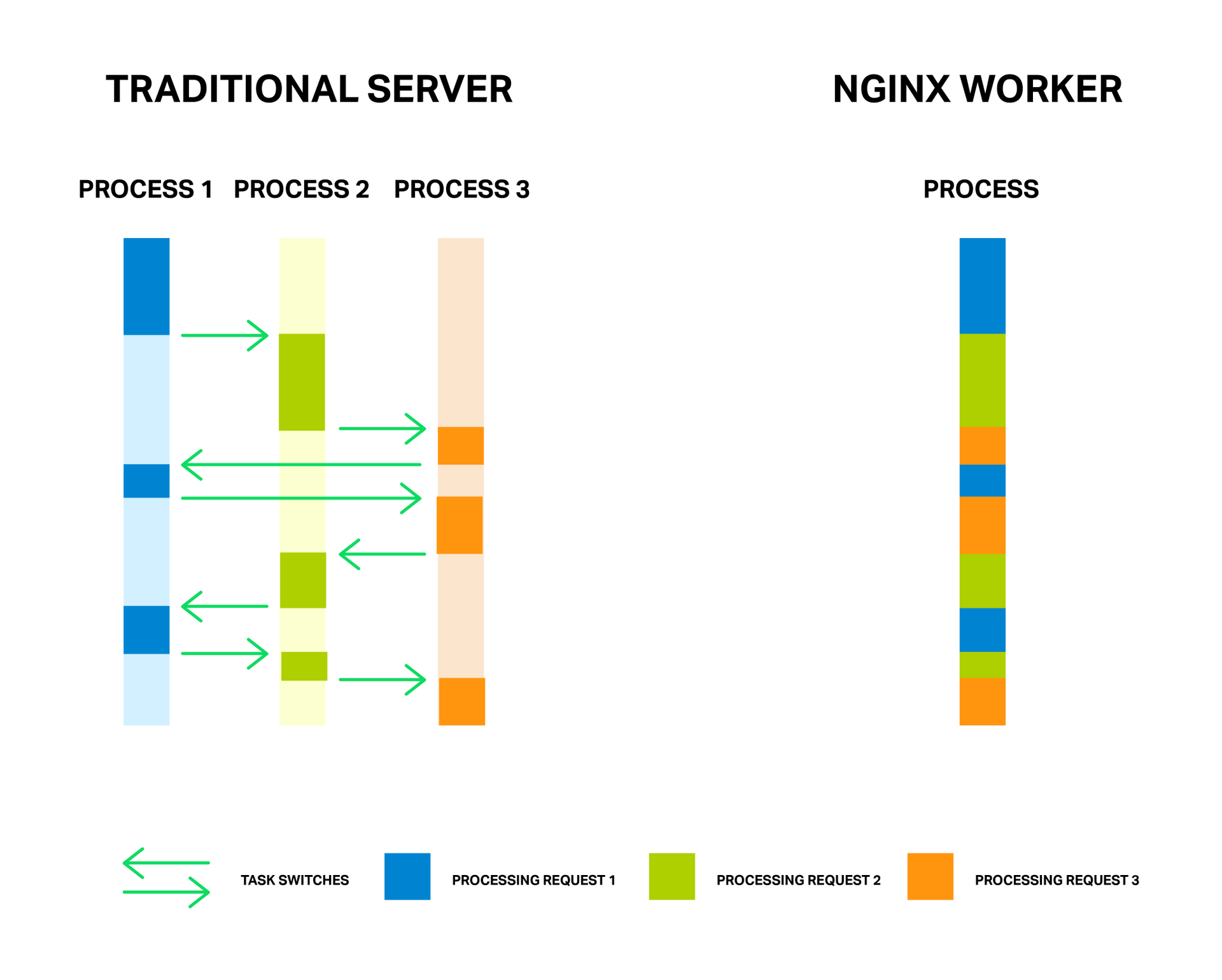
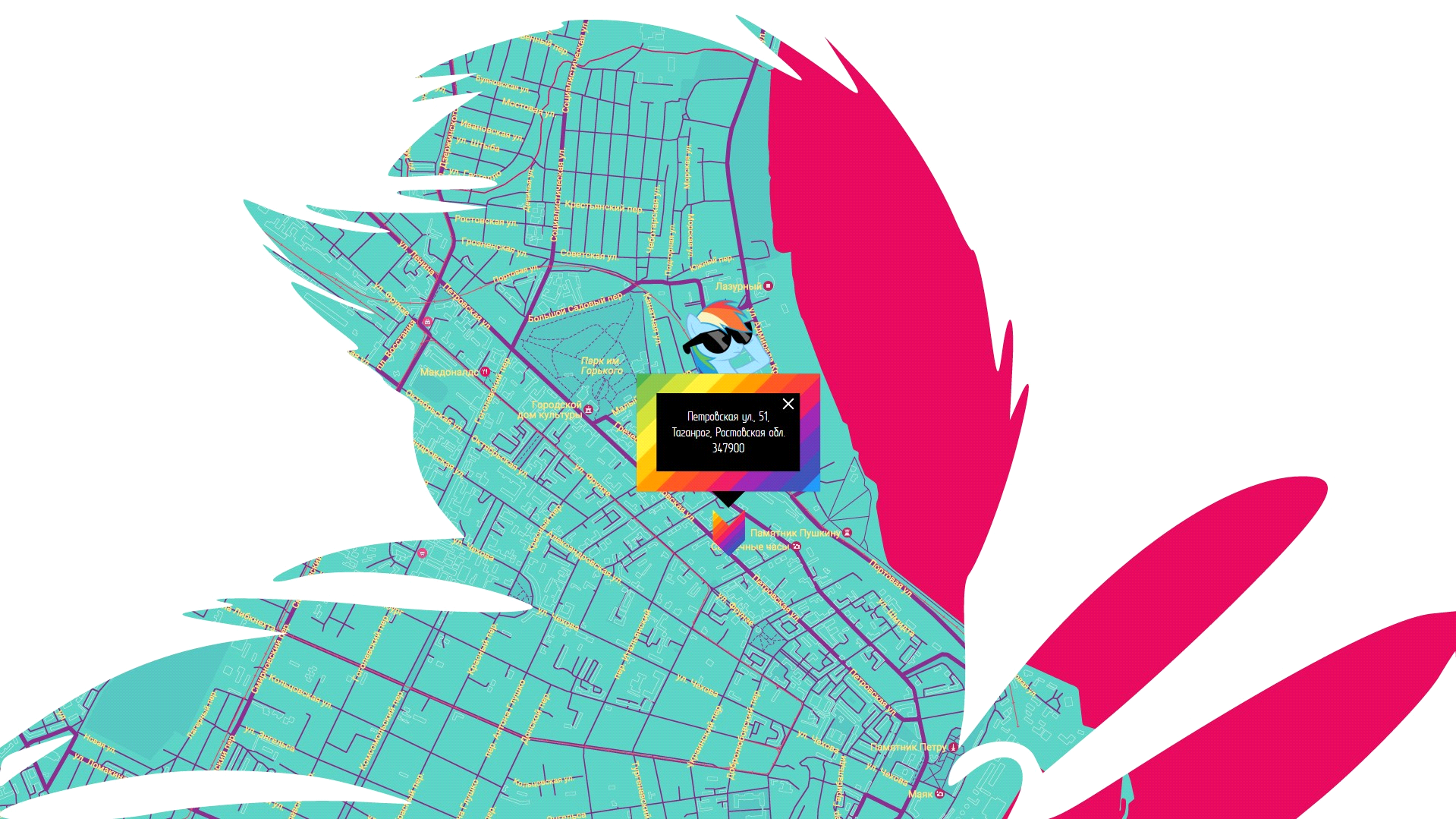
В первый раз столкнувшись с внедрением и кастомизацией Google Maps, я не нашел единой статьи, рассматривающей все необходимые моменты — информацию пришлось искать по крупицам, а что-то выдумывать самому. После чего и было решено написать эту статью, чтобы люди, ранее не работавшие со стилизацией Google Maps, но при этом ограниченные временными рамками (а может, и желанием) для полноценного изучения API, смогли быстро получить необходимую информацию и материалы. Тем более, что и те, кто обладает определенным опытом, смогут почерпнуть для себя из этой статьи какую-нибудь интересную фишку, к примеру — параллакс для элементов информационного окна.
В этой статье мы рассмотрим:
1. Внедрение Google Maps на сайт
- Добавление через вставку iframe в разметку
- Добавление через API
2. Кастомизация маркера
- Инициализация маркера
- Анимация маркера
- Изображение маркера
3. Кастомизация информационного окна
- Добавление информационного окна
- Открытие информационного окна
- Кастомизация элементов информационного окна
- Параллакс-эффект для элементов в информационном окне
4. Кастомизация карты
- Изменение цвета объектов карты
- Кастомизация элементов управления
- Маска для карты



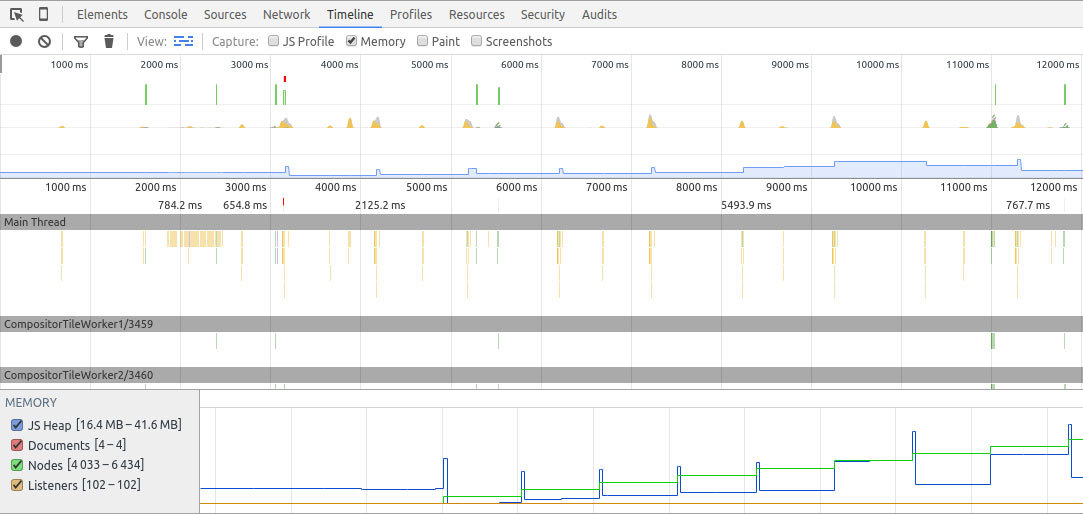







 Началось все с того, что я оптимизировал отдачу ошибки
Началось все с того, что я оптимизировал отдачу ошибки