
Пакетный менеджер Homebrew раздаёт 52 миллиона пакетов в месяц. Чтобы это делать, он использует хранилища контейнеров, отлично подходящие для этой задачи. Как это работает?

Пользователь
Пакетный менеджер Homebrew раздаёт 52 миллиона пакетов в месяц. Чтобы это делать, он использует хранилища контейнеров, отлично подходящие для этой задачи. Как это работает?


Проект Docker, запущенный в 2013 году, стал одним из самых популярных инструментов в области контейнеризации. Спустя почти 10 лет Docker активно развивается, однако, не только сама компания Docker Inc привносит улучшения в свой продукт – обычные пользователи тоже вносят свой вклад, создавая различные инструменты, которые совершенствуют взаимодействие с системой Docker.
В статье мы рассмотрим топ-5 полезных утилит, которые упростят работу с Docker.

Как вытащить из большого объёма информации только самое нужное? Современная жизнь движется на высокой скорости, информации много и она часто меняется, за большинством рабочих моментов бывает сложно уследить, поэтому навык задавать вопросы становится всё более важным.
Как этому научиться самому и научить других расскажет Валентина Уржумова, менеджер проектов, бизнес-аналитик, руководитель продукта «B2B-платформа Formix».
Недавно мной, совместно с коллегой, был реализован оператор для Kubernetes’a - Vector Operator. (Вот тут описано как мы пришли к решению, что там нужен свой оператор для Логирования в Kubernetes).
В рамках данной статьи я опишу разные интересные Задачи/Проблемы с которыми мы столкнулись в процессе разработки и как их решили.

В 1999 году каждая уважающая себя компания хотела веб-сайт. Спрос рождает предложение — так появились конструкторы сайтов и CMS.
В 2022 году каждая уважающая себя компания хочет корпоративные приложения для внутреннего использования, в том числе мобильные — для управления персоналом, сбора данных, мониторинга процессов, общения и так далее. Рынок снова дал людям то, что они хотят.

Я знаю многое о велосипедах в Enterprise-разработке. Видел издали, катался на них, собирал сам, но наступают моменты, когда типичные задачи пора перевести на типичные решения. В статье расскажу о 4 self-hosted сервисах, которые освобождают уйму времени на действительно важные вещи.

В двух предыдущих статьях мы рассмотрели различные аспекты правления учетными записями и настройки доступа к файлам. Однако, при настройке доступа всегда можно ошибиться, задав неверные значения. Если администратор выдал недостаточные права, то такая ошибка будет найдена довольно быстро, так как, тот кому этих прав не хватит очень скоро пожалуется админу. Но что делать, если прав в итоге оказалось больше, чем нужно? Многие, конечно, могут сказать, что это вообще не проблема, мол больше не меньше, но на самом деле это ошибочная логика. Как мы увидим в сегодняшней статье, даже безобидные на первый взгляд разрешения могут привести к получению прав root в системе.

Думаете о создании .NET библиотеки, но не знаете, в какую сторону двигаться? Уже разрабатываете нечто подобное, но хочется открыть для себя что-то новое? Ищете варианты расширить автоматизацию? Не знаете, что делать с пользователями?
Надеюсь, данная статья поможет ответить на эти и другие вопросы. На примере своей библиотеки с открытым исходным кодом – DryWetMIDI – рассмотрим различные аспекты создания подобных проектов. И хотя речь будет идти про .NET/C#, уверен, многое применимо и к другим популярным платформам и языкам программирования.

Надежность (reliability) программного продукта всегда является одним из приоритетов компании. Особенно это актуально для ПО, превратившегося в ежедневный инструмент для своих пользователей. Они рассчитывают на заявленный функционал, поэтому любая невозможность его использования подрывает доверие, а следовательно, и желание им пользоваться.
В этой статье пойдет речь о главных инструментах Site Reliability Engineering (SRE) и о том, как они влияют на повышение надежности систем.
 Хорошего настроения, Хаброжители!
Хорошего настроения, Хаброжители!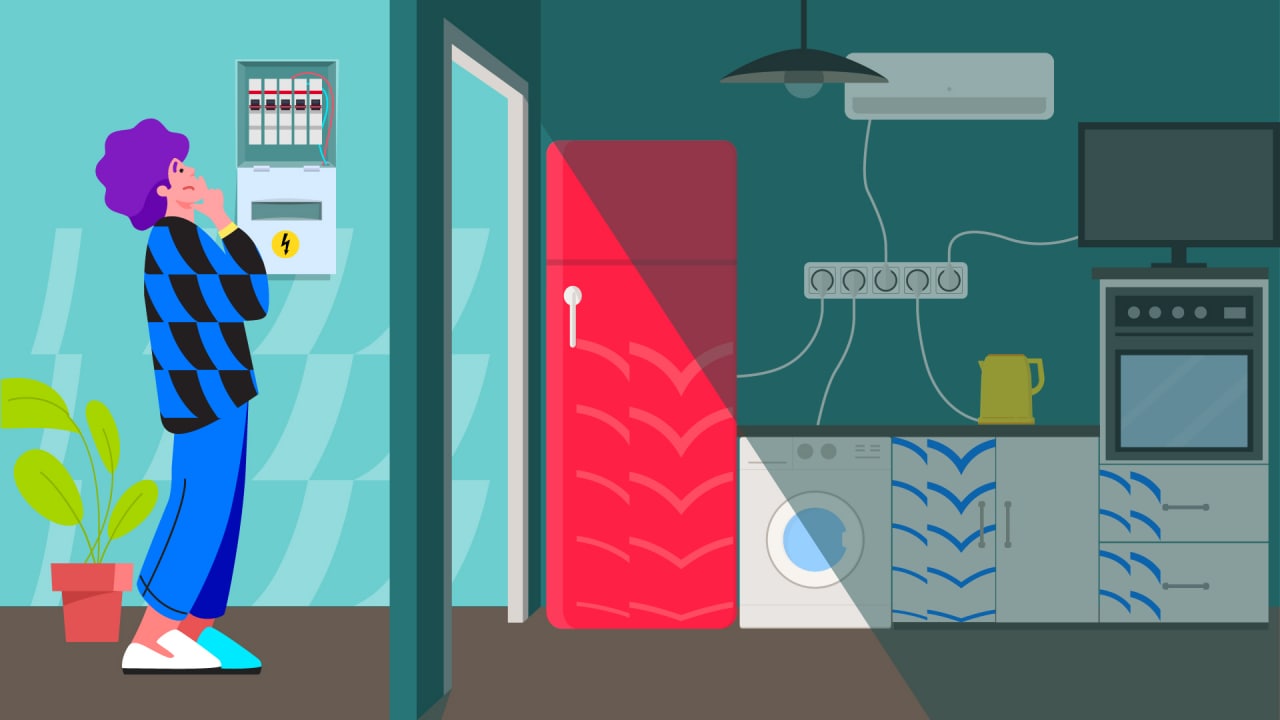
Если спросить начинающего докладчика, чего он больше всего боится перед выступлением, он, может быть, назовёт дотошного и даже скандального слушателя, или скажет, что самое страшное — это забыть слова.
Если же спросить слушателя, окажется, что для него самое страшное — это скучный доклад. Начинающий докладчик, беспокоясь за второстепенные вещи, упускает из виду главное — доклад должен быть интересным. Именно об этом надо заботиться в первую очередь.
Я организую встречи Московского клуба программистов. Наши участники регулярно делают внутренние доклады, и регулярно участвуют в больших конференциях. Вот уже несколько лет я помогаю готовить и репетировать технические доклады и, конечно, становлюсь первой жертвой скучных докладов.
Я отвечаю за подготовку и репетицию докладов в Московском клубе программистов. Не всем нашим докладчикам нужна помощь, но если нужна, помогать им буду я. За последние шесть лет мне довелось прослушать несколько десятков докладов. На самом деле я не знаю, сколько их было — никогда не считал — но, возможно, их уже больше ста.
Доклады были разными. Я хотел, чтобы они были захватывающими и полезными, так что мне пришлось разобраться в том, как сделать интересный доклад. Оказалось, что эти знания востребованы и среди программистов — начинающих докладчиков, и среди деврелов. В конце концов я решился написать статью на эту тему.
Материала оказалось много и статьи получилось две. Эта первая — о том, как придумать тему доклада.

С чего началась наша компания? В первую очередь, конечно, с людей и с идеи. Как это обычно бывает, правильные люди абсолютно случайно познакомились друг с другом, и вот я здесь, сижу и пишу этот пост =) Была, однако, и ещё одна очень важная составляющая - данные...
Любой ML-проект начинается с анализа ландшафта доступных данных - что мы можем скачать, выгрузить, разметить, купить. За четыре года наша культура работы с данными, инструментарий, подходы, процесс разметки претерпели очень большие изменения. Сейчас у нас накоплено почти 100 терабайт медицинских исследований, но количество данных абсолютно не важно, если они плохого качества, и их неудобно изучать, понимать и использовать. Недавно я делал обзорный доклад про разные аспекты качества медицинских данных, а вот наше выступление про технические аспекты пути к качеству. Сегодня же я хочу поговорить об очень интересной концепции (или даже философии), которая в последнее время на слуху, но, судя по разным постам в интернете, её суть понятна далеко не всем. Это Data Mesh.
Впервые я столкнулся с этим понятием в докладе Леруа Мерлен на митапе LeanDS. Доклад любопытный, но суть дата меш мне из него была понятна не до конца, так что недавно я взялся за чтение книги от авторки этой концепции и термина - Data Mesh: Devlivering Data-Driven Value at Scale.
Книга мне очень понравилась - она концептуальная, почти не затрагивает конкретные инструменты и способы реализации, но раскрывает суть идеи целиком и полностью. Полный конспект я могу скинуть в комментариях, если кого-то заинтересует, а в этом посте я поговорю об основных принципах, моей интерпретации и самых интересных моментах для нашей компании.

Terraform за 15 дней (AWS/Yandex). День 1
Мы от простого к сложному, поднимем небольшую инфраструктуру на aws и Яндекс (актуальность последнего я думаю объяснять не нужно). Так что по итогу вы сможете сказать: “Я изучал terraform от простого к сложному”.
Я постараюсь добавить все необходимые ссылки на документации и доп. источники, так что вы сможете дополнить необходимые знания, но данный курс (если это можно так назвать) скорее рассчитан на тех, кто в общем знаком с облачными технологиями. Это не пособие по terraform. Цель - помочь новичкам в данном вопросе начать изучать IaC и облака в целом. Некий quick start в terraform.


Поскольку Airflow — это на 100% код, знание основ Python - это все, что нужно, чтобы начать писать DAG. Однако написание эффективных, безопасных и масштабируемых DAG требует учета некоторых моментов, специфичных для Airflow. В этом разделе мы рассмотрим некоторые передовые методы разработки DAG, которые максимально используют возможности Airflow.
В целом, большинство лучших практик, которые мы здесь рассматриваем, относятся к одной из двух категорий:

Операторы являются основными строительными блоками DAG Airflow. Это классы, которые содержат логику выполнения единичной работы.
Вы можете использовать операторы в Airflow, создав их экземпляры в задачах. Задача определяет работу, выполняемую оператором в контексте DAG.
Чтобы просмотреть и выполнить поиск по всем доступным операторам в Airflow, посетите Astronomer Registry. Ниже приведены примеры операторов, которые часто используются в проектах Airflow.
Туториалы делятся на две больших категории: либо "как нарисовать сову", либо подробно расписанные тысячи шагов в формате "напиши туториал для дурака - и только дурак захочет его читать".
Как какой из двух категорий относится эта статья — решать вам.
В этой статье вы увидите пошаговое создание cloud-native микросервиса на Amazon AWS, пригодное для "чтения с листа". Чтобы понять, что здесь происходит, не нужно разворачивать проект - достаточно обладать живым воображением и прочитать текст по диагонали. Если же вы всё-таки захотите повторить шаги, вам будут жизненно нужны знания вида, как создавать классы в IDE и что такое Spring.
Вначале мы напишем пару простых микросервисов на Spring Boot, докеризуем их, зальём в AWS, настроим красивые доменные имена и HTTPS, прикрутим логирование и мониторинг, Prometheus и Grafana. Это небольшое путешествие по всем кругам ада, из которого вы не вернетесь прежним.
Текст написан на основе текстов и демо-проекта microservice-customer за авторством @kamaruzzaman. Если вы потеряли нить повествования, всегда можно зайти на GitHub и найти весь код в пригодном для запуска виде. Если захочется закопаться в тему, то бро Дима Чуйко (@Teapot) написал вам ещё две части статьи "Микросервисы: от CRUD до Native Image" (раз, два).
Последняя важная оговорка. В этом гайде будут использоваться технологии Amazon и обычные дистрибутивы OpenJDK. Автор осознает, что мы живём в России, и возможно, вместо Amazon куда лучше подойдет что-то вроде SberCloud или MTS Cloud, а вместо обычного OpenJDK - Axiom JDK с сертификацией по ФСТЭК. Особенности российских технологий - тема для отдельной статьи. Если вы захотите таковую после чтения этого гайда - отметьтесь в комментариях.