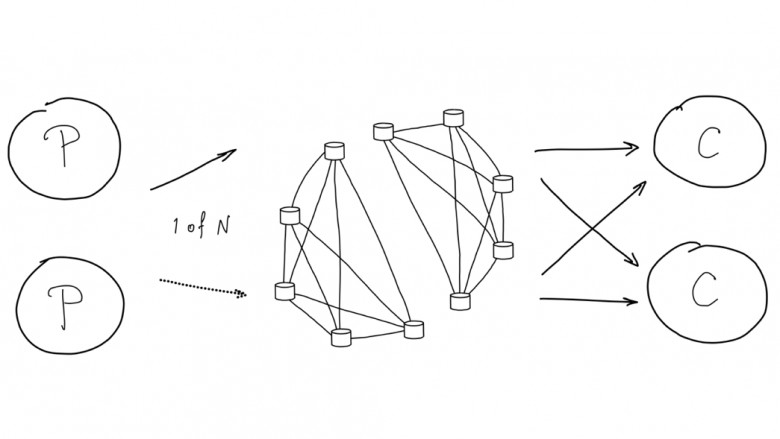
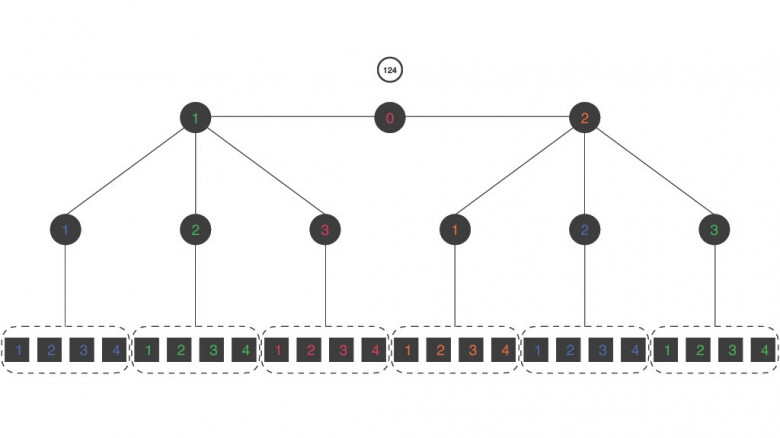
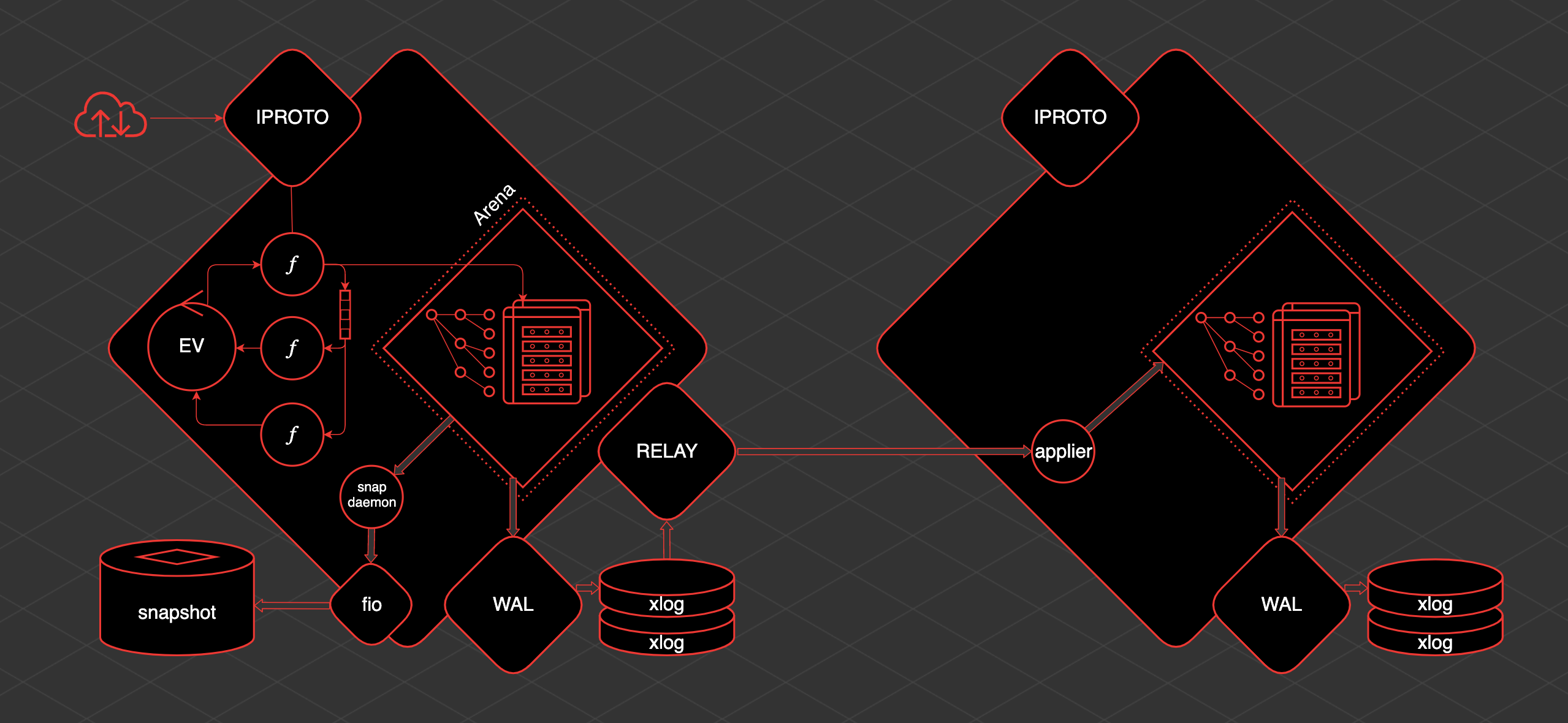
Доклад будет посвящен Tarantool. Я всегда рассказывал про use case, про что-то такое, что видит пользователь. Сегодня буду больше рассказывать про внутренности.
Когда я первый раз увидел Tarantool, когда я узнал его бенчмарки, какая у него производительность, то мне это не то, чтобы показалось подозрительным, потому что все-таки я уже до этого программировал больше чем 10 лет и примерно понимал, что можно выжать из железа при оптимальном программировании, при оптимальном коде. Но все равно мне это показалось подозрительным — как так получается, что он такой быстрый? Т.е., условно, если все базы данных могут работать со скоростью в лучшем случае в десятки тысяч запросов в секунду, а Tarantool —
до сотен тысяч и вплоть до миллиона.
Поэтому, прежде чем начать применять его в продакшне, в Почте mail.ru и в Облаке, я все очень внимательно изучил и выяснил, как Tarantool устроен внутри, и что его делает таким оптимальным. И я подозреваю, что, наверное, у других пользователей Tarantool тоже есть такое же подозрение — что-то он какой-то слишком быстрый, и как-то это подозрительно…