Категорически приветствую! В прошлый раз я писал о вероятностном алгоритме определения принадлежности элемента множеству, в этот раз будет про вероятностную оценку похожести. Не надо большого ума, чтобы додуматься до следующего показателя схожести двух множеств А и Б:
То есть, количество элементов в пересечении делённое на количество элементов в объединении. Эта оценка называется коэффициентом Жаккара (Jaccard, поэтому «J»), коэффициент равен нулю, когда множества не имеют общих элементов, и единице, когда множества равны, в остальных случаях значение где-то посередине.
Электронная почта используется для решения широкого круга задач: мы получаем информацию о банковских счетах, обсуждаем рабочие проекты, планируем путешествия и еще много чего, что требует от нас обмена ценной информацией. Таким образом, почта содержит в себе много важных и конфиденциальных данных. И конечно, наша задача — надежно их защищать.
Мы постоянно работаем над системами, которые обеспечивают аккаунтам несколько ступеней защиты и значительно усложняют жизнь злоумышленникам. Но есть одно слабое звено. Это пароль, который можно угадать или, например, украсть на стороннем сервисе. Подробнее о способах кражи паролей и о безопасности почты можно прочесть в посте на эту тему.
Наша задача — защитить ящик пользователя, даже если злоумышленник узнал пароль и может войти в аккаунт. Для этого мы разработали систему машинного обучения, которая анализирует поведение в аккаунте и пытается определить, кто в нем находится — владелец или взломщик.
Прошел примерно год, как меня заинтересовал Rust, язык программирования от Mozilla Research, сосредоточенный на решении трёх задач: безопасность, скорость и параллелизм. Он такой же низкоуровневый, как Си или C++, имеет хорошую систему типов (с обобщениями (generics) и типажами (traits)), дружелюбный компилятор и отличный менеджер пакетов Cargo.
С выпуска Rust 1.0 прошло уже полгода (май 2015): многие библиотеки (пакеты, crates), включая некоторые мои, были опубликованы в центральном регистре crates.io. Вот неплохие практики (еще рановато называть их "лучшими"), которые помогут другим людям находить, использовать и дополнять вашу библиотеку.
Статья написана об использовании алгоритма вычисления расстояния Левенштейна для нечеткого поиска в тексте, без использования вспомогательного словаря.
Расстояние Левенштейна используется для сравнения двух слов или двух строк, чтобы определить их схожесть. Некоторое время назад передо мной встала схожая задача — в заданной строке искать вхождение слов, словосочетаний и формул, похожих на образец.
Примечание переводчика: визит под кат этого поста означает большие объёмы потреблённого трафика. И это иронично, если учесть поднятую тему. Но всё сразу встаёт на свои места, если помнить, что в оригинале это было выступление в прошлом ноябре в Сиднее длиной почти в час. Чтение поста занимает куда меньше времени. В форме видеозаписи (1280×720) речь занимает два гигабайта. Пост же занимает всего лишь 12 МиБ. Рекомендуется просмотр на широких мониторах.
Перед началом тирады я хотел бы обратить внимание на то, что прекрасные сайты бывают любых форм и размеров. И я здесь не собираюсь кого-то пристыживать за количество использованных бит, объём использованных ресурсов и так далее. Я люблю большие сочные галереи изображений, мне нравятся огромные эксперименты на JavaScript, я смотрю онлайн-видео в высоком разрешении, как и все вы. Я считаю, что подобное замечательно.
Выступление совсем не об этом. Я хотел бы поговорить об этом общественном кризисе здоровья, этом ожирении сайтов. Отличные дизайнеры, которые задумываются о вебе как я или даже больше, почему-то делают страницы, которые становятся больше. Речь пойдёт о текстовых в своей основе сайтах, которые по каким-то непостижимым причинам с каждым годом становятся всё больше и больше.
В этой серии статей мы рассматриваем процесс создания масштабируемого сервера для чата в реальном времени, во всех деталях. Цель статьи — показать пример практического применения языка Rust на фоне изучения концепций системного программирования и системных API, шаг за шагом.
Вторая часть является прямым продолжением первой, поэтому если вы ее пропустили (или забыли контекст), то рекомендую сначала ознакомиться с ней. В этой части мы продолжаем реализацию протокола WebSocket.
То, о чем я попытаюсь сейчас рассказать, выглядит как настоящая магия.
Если вы что-то знали о нейронных сетях до этого — забудьте это и не вспоминайте, как страшный сон.
Если вы не знали ничего — вам же легче, полпути уже пройдено.
Если вы на «ты» с байесовской статистикой, читали вот эту и вот эту статьи из Deepmind — не обращайте внимания на предыдущие две строчки и разрешите потом записаться к вам на консультацию по одному богословскому вопросу.
Итак, магия:
Слева — обычная и всем знакомая нейронная сеть, у которой каждая связь между парой нейронов задана каким-то числом (весом). Справа — нейронная сеть, веса которой представлены не числами, а демоническими облаками вероятности, колеблющимися всякий раз, когда дьявол играет в кости со вселенной. Именно ее мы в итоге и хотим получить. И если вы, как и я, озадаченно трясете головой и спрашиваете «а нафига все это нужно» — добро пожаловать под кат.
Понятие «архитектура чистого кода» (Clean Code Architecture) ввел Роберт Мартин в блоге 8light. Смысл понятия в том, чтобы создавать архитектуру, которая не зависела бы от внешнего воздействия. Ваша бизнес-логика не должна быть объединена с фреймворком, базой данных или самим вебом. Подобная независимость даёт ряд преимуществ. К примеру, при разработке вы сможете откладывать какие-то технические решения, например выбор фреймворка, движка/поставщика БД. Также вы сможете легко переключаться между разными реализациями и сравнивать их. Но самое важное преимущество такого подхода — ваши тесты будут выполняться быстрее.
Просто подумайте об этом. Вы действительно хотите пройти роутинг, подгрузить абстрактный уровень базы данных или какое-нибудь ORM-колдовство? Или просто выполнить какой-то код, чтобы проверить (assert) те или иные результаты?
Ранее мы говорили о разработке системы квантовой связи и о том, как из простых студентов готовят продвинутых программистов. Сегодня мы решилие еще раз (1, 2) взглянуть в сторону темы машинного обучения и привести адаптированную (источник) подборку полезных материалов, обсуждавшихся на Stack Overflow и Stack Exchange.
Друзья, мы с радостью продолжаем публикацию интересных материалов, посвященных самым разнообразным аспектам работы с PostgreSQL. Сегодняшний перевод открывает целую серию статей за авторством Hubert Lubaczewski, которые наверняка заинтересуют широкий круг читателей.
Одна из первых вещей, которую слышит новоиспеченный администратор баз данных – «используй EXPLAIN». И при первой же попытке он сталкивается c непостижимым:
Сначала я хотел честно и подробно написать о методах снижения размерности данных — PCA, ICA, NMF, вывалить кучу формул и сказать, какую же важную роль играет SVD во всем этом зоопарке. Потом понял, что получится текст, похожий на вырезки из опусов от Mathgen, поэтому количество формул свел к минимуму, но самое любимое — код и картинки — оставил в полном объеме.
Индикатор кулачкового аналогового компьютера / Wiki
В нашем блоге мы уже рассказывали о разработке системы квантовой связи и о том, как из простых студентов готовят продвинутых программистов. Сегодня мы решили вернуться к теме машинного обучения и привести адаптированную (источник) подборку полезных материалов.
Ежегодная конференция профессиональных веб-разработчиков DevConf проходит с 2010 года. Она состоит из нескольких секций, посвященных самым популярным языкам и технологиям веб-разработки. В 2015 году году компания Badoo взяла на себя важную миссию — записать видео выступлений, чтобы те, кто не смог посетить конференцию, могли посмотреть их в любое время.
Первым делом мы решили выложить видео с самой интересной для нас секции, посвященной нашему любимому языку PHP. Некоторые темы нам настолько близки, что мы постарались рассказать не только о содержании доклада, но и о том, что мы в Badoo делаем и думаем на этот счет. Надеемся, этот формат покажется интересным читателям и даст более широкое представление о теме.
Секция PHP конференции DevConf 2015
В первую очередь хотелось бы отметить доклад Дмитрия Стогова (Zend Technologies) «Релиз PHP 7: что нас ждет в октябре 2015». Не будем мучить вас переводом «чейнджлога» седьмой версии, а скажем просто: смотреть всем, кто имеет хоть какое-то отношение к PHP. Если вы за свою жизнь написали хотя бы строчку кода на PHP, то, скорее всего, уже слышали про сумасшедшую производительность, JIT и spaceship operator. JIT в PHP так и не появился, но оптимизации проведены масштабные. В докладе Дмитрий рассказывает много о внутренней кухне PHP, есть графики производительности разных версий PHP и HHVM на реальных приложениях. Badoo сейчас как раз в процессе перехода на PHP 7, нам пришлось сильно «перекопать» инфраструктуру тестирования и переписать кучу расширений, но мы на финишной прямой и можем подтвердить, что PHP 7 действительно показывает очень серьезный рост производительности. Какой именно получается прирост? Пока секрет. Ждите от нас отдельной статьи на эту тему, когда мы поборем последние косяки, отлавливаемые на продакшн-трафике.
Не задумывались ли вы, почему специалисты/профессионалы в области микроконтроллеров и автоматизации относятся к тем, кто работает с Arduino примерно так, как будто они занимаются чем-то не серьёзным, вроде игры в песочнице?
Примерно так же к ардуино относится и мой кот Вася.
Собственно для этого я и сделал видео, где наглядно, при помощи осциллографа, покажу и расскажу, с моей точки зрения, почему так. Постараюсь высветлить явные плюсы и минусы темы Arduino:
Есть такая конференция ADD (Application Developer Days) на которой любят всякие архитектурные штуки для разработки ПО обсуждать, обычно эти штуки заканчиваются тоже на xDD — DDD, TDD, MDD и т.д.
Вот к примеру на прошлой конференции задались вопросом, а что такое DDD (Domain Driven Design)?
А Николай Гребнев из CUSTIS — встал и ответил.
MIPSfpga — это пакет, который содержит процессорное ядро в исходниках на Verilog, которое можно менять, добавлять новые инструкции, строить многопроцессорные системы, менять одновременно софтвер и хардвер, симулировать на симуляторе верилога, синтезировать для ПЛИС/FPGA и т.д. Его можно в целях эксперимента например запускать с частотой 1 такт в секунду и выводить наружу информацию о состоянии кэша, конвейера, и любых структур внутри процессора. При этом ядро MIPS microAptiv UP внутри MIPSfpga — это то же ядро которое например используется в платформе IoT Samsung Artik 1 и Microchip PIC32MZ, т.е. студенты получают возможность работать с тем же кодом, с которым работают инженеры в Samsung и Microchip.
MIPSfpga не предназначен для введения в предмет с абсолютного нуля. Для его плодотворного использования нужно чтобы студент или исследователь уже знал основы цифровой схемотехники, умел бы программировать на Си и на ассемблере, а также представлял бы концепции микроархитектуры — конвейера, конфликтов конвейера и т.д. Желательно, чтобы до работы с MIPSfpga студент уже бы построил собственный простой процессор с нуля и мог бы сравнивать свой простой процессор с процессором, используемым в промышленности и совместимым с развитой экосистемой разработки.
Под новогодние праздники был выпущен Rust 1.5. Так как близится релиз 1.6, хочу наверстать упущенное, и рассказать о том, что появилось в последней стабильной версии. Существенные изменения затронули Cargo!
Процедурные макросы — одна из наиболее ожидаемых фич Rust. На данный момент процедурные макросы возможно писать только под нестабильную версию компилятора, хотя есть несколько контейнеров, вроде syntex, позволяющие делать ограниченную кодогенерацию в рамках стабильного компилятора. Однако ситуацию это особо не облегчает, поскольку интерфейс к AST остаётся нестабильным, и, хотя авторы syntex стараются идти в ногу с ночными сборками, иногда случаются фейлы из-за изменений в структуре AST.
В этом блог посте один из участников core team — Nick Cameron — поделился своим видением будущего процедурных макросов. Хотя пост полон технических подробностей по внутренностям компилятора, мне показалось, что хабрасообществу может быть интересно заглянуть немного за кулисы разработки Rust.
Фреймворк для процедурных макросов
В этом посте я расскажу, как, по моему мнению, должны выглядеть процедурные макросы. Я уже рассказывал про синтаксис в другом посте, а когда мы опубликуем API для процедурных макросов, то напишу пост и про него. Я уже описывал целый ряд изменений в системе макросов, так что здесь я в чём-то повторюсь (отчасти противореча прошлому посту), но раскрою больше подробностей.

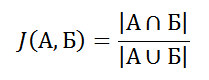







 Сначала я хотел честно и подробно написать о методах снижения размерности данных —
Сначала я хотел честно и подробно написать о методах снижения размерности данных — 

