Возможно, кто-то еще помнит, как писали SMS, а иногда и письма, «транслитом». Но зачем транслитерация сегодня, когда везде уже unicode? К сожалению, унаследованные приложения выходят из эксплуатации намного медленнее, чем хотелось бы. Например, и сегодня используются томографы, не допускающие кириллицу в именах пациентов. При том, что информационная система, используемая тем же отделением, прекрасно кириллицу понимает. И оператору томографа нужно не просто позвать пациента на исследование, но и правильно записать его фамилию в какие-нибудь документы. Похожие ситуации могут встретится в разных местах.
То есть, возникает задача как-то передать текстовые данные в унаследованную систему, чтобы:
Чтобы не было скучно, добавим более подробных требований, связанных с совместимостью и простотой для человека:
Конечно, перечисленное не совсем требования (кроме первых двух), а, скорее, эвристики.
Можно найти много готовых вариантов транслитерации кириллицы в латиницу. Но среди них не нашлось ничего, что бы удовлетворяло всем требованиям в приемлемой степени. То использует диакритические символы, как стандарты, то выбрасывает буквы (обычно «Ъ»), то предлагают необратимые (щ —> shch) или фонетически дикие (ш —> w) варианты замены, или имеют другие фатальные недостатки.
Значит, делаем свой велосипед. Собственно, нужно составить таблицу соответствия, и описать алгоритм преобразования туда и обратно.
То есть, возникает задача как-то передать текстовые данные в унаследованную систему, чтобы:
- человек — оператор унаследованной системы смог прочесть полученный текст «по звучанию»
- при необходимости можно было бы однозначно восстановить исходный кириллический текст
Чтобы не было скучно, добавим более подробных требований, связанных с совместимостью и простотой для человека:
- использовать только буквы в узком смысле, без знаков препинания и диакритических элементов (это заодно позволит сохранить регистр)
- каждую исходную букву преобразовывать независимо от остальных (без сложностей вроде «в начале / в конце слова» и т.п.)
- замены как можно более короткие, в идеале одно-буквенные
- правила обратного преобразованния как можно проще, например, замены должны соответствовать условию Фано
- близкие по звучанию замены, в представлении «обычного человека» — на практике это некая смесь из латыни, английской, французской, немецкой и, иногда, испанской фонетики
Конечно, перечисленное не совсем требования (кроме первых двух), а, скорее, эвристики.
Можно найти много готовых вариантов транслитерации кириллицы в латиницу. Но среди них не нашлось ничего, что бы удовлетворяло всем требованиям в приемлемой степени. То использует диакритические символы, как стандарты, то выбрасывает буквы (обычно «Ъ»), то предлагают необратимые (щ —> shch) или фонетически дикие (ш —> w) варианты замены, или имеют другие фатальные недостатки.
Значит, делаем свой велосипед. Собственно, нужно составить таблицу соответствия, и описать алгоритм преобразования туда и обратно.







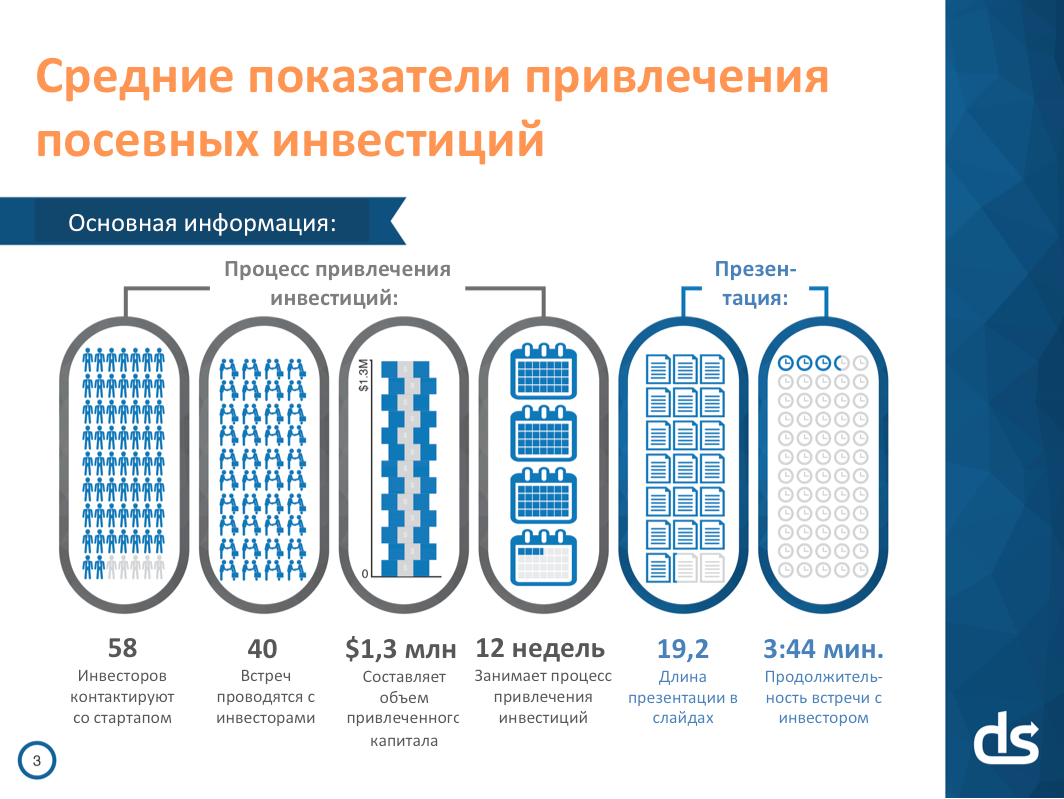
 В последние несколько лет MongoDB приобрела огромную популярность среди разработчиков. То и дело в интернете появляются всякие статьи, как очередной молодой популярный проект выкинул на свалку истории привычные РСУБД, взял в качестве основной базы данных MongoDB, выстроил инфраструктуру вокруг неё, и как все после этого стало прекрасно. Даже появляются новые фреймворки и библиотеки, которые строят свою архитектуру целиком на Mongo (
В последние несколько лет MongoDB приобрела огромную популярность среди разработчиков. То и дело в интернете появляются всякие статьи, как очередной молодой популярный проект выкинул на свалку истории привычные РСУБД, взял в качестве основной базы данных MongoDB, выстроил инфраструктуру вокруг неё, и как все после этого стало прекрасно. Даже появляются новые фреймворки и библиотеки, которые строят свою архитектуру целиком на Mongo (