Здравствуйте, уважаемые читатели. Сегодня мы хотели бы предложить вам перевод статьи о неизменяемости в современном JavaScript. Подробнее о различных возможностях ES6 рекомендуем почитать в вышедшей у нас замечательной книге Кайла Симпсона "ES6 и не только".

Пользователь
Головоломки TCP
15 мин
Перевод
Говорят, что нельзя полностью понять систему, пока не поймёшь её сбои. Ещё будучи студентом я ради забавы написал реализацию TCP, а потом несколько лет проработал в IT, но до сих пор продолжаю глубже и глубже изучать работу TCP — и его ошибки. Самое удивительное, что некоторые из этих ошибок проявляются в базовых вещах. И они неочевидны. В этой статье я преподнесу их как головоломки, в стиле Car Talk или старых головоломок Java. Как и любые другие хорошие головоломки, их очень просто воспроизвести, но решения обычно удивляют. И вместо того, чтобы фокусировать наше внимание на загадочных подробностях, эти головоломки помогают изучить некоторые глубинные принципы работы TCP.
Теория категорий на JavaScript. Часть 1. Категория множеств
35 мин
Туториал

Абстракция – это одна из основных техник в ИТ. Любой язык программирования или моделирования, любая парадигма программирования (процедурная, функциональная, ООП, …) дают ответ на вопрос, как и от чего нужно абстрагироваться. Причём, адепты каждого подхода предлагают какой-то свой вариант абстракции.
Если вы хотите увидеть истинную, универсальную абстракцию, то
Также немного говорится про классы, примеси и смеси в JavaScript.
Примеры из статьи можно посмотреть тут.
Ученые выяснили, как человеческий мозг адаптируется ко лжи
4 мин

Команда исследователей из Университетского колледжа Лондона установила опытным путем, что самая маленькая ложь может привести к неконтролируемым последствиям. Когда вы немного приукрашиваете правду ради собственной выгоды, рано или поздно приходится придумывать новую ложь, чтобы поддержать предыдущую. Со временем вырастает целая паутина, которая в первую очередь вредит ее создателю. Ученые представили первые эмпирические доказательства того, как одна корыстная ложь накладывается на другую и показали, как и почему это происходит в наших головах.
Javascript-паноптикум
7 мин
За время, что мне довелось писать на Javascript, у меня сложился образ, что js и его спецификация это шкатулка с потайным дном. Иногда кажется, что ничего секретного в ней нет, как вдруг магия стучит в ваш дом: шкатулка раскрывается, оттуда выскакивают черти, по-домашнему исполняют блюз и резво скрываются обратно в шкатулке. Позднее вы узнаете причину: стол повело и шкатулку наклонило на 5 градусов, что вызвало чертей. С тех пор вы не знаете, это фича шкатулки, или лучше все-таки покрепче замотать её изолентой. И так до следующего раза, пока шкатулка не подарит новую историю.
И если записывать каждую такую историю, может получиться небольшая статья, которой я и хочу поделиться.
Любой сайт может получить информацию о том, в каких популярных сервисах вы авторизированы
3 мин
Разработчик Робин Линус на своей странице на GitHub Pages (визит по следующей ссылке небезопасен и его не рекомендуется выполнять с рабочего места, так как кроме видимой части сервисов страница проверяет, залогинены ли вы на сайтах для взрослых, а это останется в логах файрволла как попытка перехода прим.) продемонстрировал, как сайты могут снимать с вас «медийный отпечаток», то есть вести учет того, в каких популярных сервисах залогинены посетители даже без какой-либо авторизации на посещаемой странице.
Для автора публикации «медийный отпечаток» выглядит следующим образом и является абсолютно верным:

И это весьма неприятно.
Для автора публикации «медийный отпечаток» выглядит следующим образом и является абсолютно верным:
И это весьма неприятно.
Ограничения (сonstraints) PostgreSQL: exclude, частичный unique, отложенные ограничения и др
4 мин
 Целостность данных легко нарушить. Бывает так, что в поле price попадает значение 0 из-за ошибки в коде приложения (периодически всплывают новости, как в том или ином инет-магазине продавали товары по 0 долларов). Или бывает, что удалили юзера из таблицы, но какие-то данные о нем остались в других таблицах, и эти данные вылезли в каком-то интерфейсе.
Целостность данных легко нарушить. Бывает так, что в поле price попадает значение 0 из-за ошибки в коде приложения (периодически всплывают новости, как в том или ином инет-магазине продавали товары по 0 долларов). Или бывает, что удалили юзера из таблицы, но какие-то данные о нем остались в других таблицах, и эти данные вылезли в каком-то интерфейсе.PostgreSQL, как и любая другая СУБД, умеет делать некоторые проверки при вставке/изменении данных, и этим обязательно нужно уметь пользоваться. Давайте посмотрим, что мы можем проверять:
1. Кастомный подтип через ключевое слово DOMAIN
Мониторинг Postgresql: запросы
6 мин
 В 2008 году в списке рассылки pgsql-hackers началось обсуждение расширения по сбору статистики по запросам. Начиная с версии 8.4 расширение pg_stat_statements входит в состав постгреса и позволяет получать различную статистику о запросах, которые обрабатывает сервер.
В 2008 году в списке рассылки pgsql-hackers началось обсуждение расширения по сбору статистики по запросам. Начиная с версии 8.4 расширение pg_stat_statements входит в состав постгреса и позволяет получать различную статистику о запросах, которые обрабатывает сервер.
Обычно это расширение используется администраторами баз данных в качестве источника данных для отчетов (эти данные на самом деле являются суммой показателей с момента сброса счетчиков). Но на основе этой статистики можно сделать мониторинг запросов — посмотреть на статистику во времени. Это оказывается крайне полезно для поиска причин различных проблем и в целом для понимания, что происходит на сервере БД.
Я расскажу, какие метрики по запросам собирает наш агент, как мы их группируем, визуализируем, так же расскажу о некоторых граблях, по которым мы прошли.
JSON-сериализатор на быстрых шаблонах
37 мин

В чем проблема текстовых форматов обмена данными? Они медленные. И не просто медленные, а чудовищно медленные. Да, они избыточны, по сравнению с бинарными протоколами и, по идее, текстовый сериализатор должен быть медленнее примерно на столько же, на сколько он избыточен. Но на практике получается, что текстовые сериализаторы иной раз на порядки уступают бинарным аналогам.
Я не буду рассуждать о преимуществах JSON перед бинарными форматами — у каждого формата есть своя область применения, в которой он хорош. Но зачастую мы вынуждены отказываться от чего-то удобного в пользу не очень комфортного в силу катастрофической неэффективности первого. Разработчики отказываются от JSON, даже если он прекрасно подходит для решения задачи, только из-за того, что он оказывается узким местом в системе. Конечно же, виноват не JSON сам по себе, а реализации соответствующих библиотек.
В этой статье я расскажу не только о проблемах парсеров текстовых форматов вообще и JSON в частности, но и о нашей библиотеке, которую мы используем уже много лет в самых высоконагруженных проектах. Она настолько нас устраивает и в плане быстродействия, и в плане удобства использования, что порой отказываемся от бинарного формата там, где бы он больше подошел. Конечно же, я имею в виду некие пограничные условия, без претензий на все случаи жизни.
Математик оптимизировал решето Эратосфена, чтобы искать простые числа с меньшим расходом памяти
4 мин

38-летний перуанский математик Харальд Хельфготт три года назад доказал тернарную гипотезу Гольдбаха, а сейчас сумел оптимизировать компьютерный алгоритм для расчёта решета Эратосфена. Фото: Matías Loewy
В III в. до нашей эры древнегреческий математик, астроном, географ, филолог и поэт Эратосфен Киренский придумал гениальный способ поиска простых чисел. Очень эффективный и быстрый метод, который используется до сих пор, получил название решето Эратосфена.
Суть понятна из названия. Решето Эратосфена означает поиск простых чисел методом исключения. Берём список чисел, исключаем из него все составные числа — и получаем список простых чисел, словно просеяв список через решето.
Разгугленный Chromium
4 мин
Даже если у вас нет аккаунта в Google, свободный браузер Chromium всё равно в фоновом режиме обменивается данными с серверами Google. Это довольно странно, ведь люди устанавливают Chromium вместо Chrome именно для того, чтобы получить чистую программу без коммерческой привязки. Тем не менее, при сборке Chromium в нормальном режиме всё равно скачиваются и устаналиваются бинарные блобы от Google.
Проект ungoogled-chromium — это набор конфигурационных флагов, патчей и специальных скриптов, чтобы удалить интеграцию с Google, улучшить настройки безопасности и управления.
Проект ungoogled-chromium — это набор конфигурационных флагов, патчей и специальных скриптов, чтобы удалить интеграцию с Google, улучшить настройки безопасности и управления.
Правильные многогранники. Часть 1.1 Символ Шлефли
13 мин
Туториал
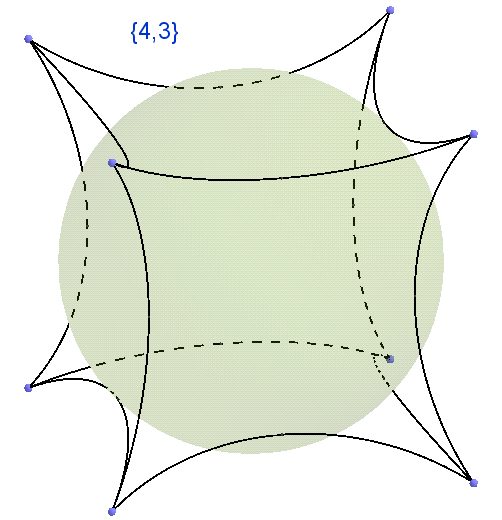 Хабрахабр, уважаемые коллеги! Когда смотрю на соты, то думаю не о пчёлах, а о Символе Шлефли. Прочитав эту статью, вы уже не сможете смотреть на мир по старому, вы поймёте, что между сотами и правильными многогранниками есть прямая связь.
Хабрахабр, уважаемые коллеги! Когда смотрю на соты, то думаю не о пчёлах, а о Символе Шлефли. Прочитав эту статью, вы уже не сможете смотреть на мир по старому, вы поймёте, что между сотами и правильными многогранниками есть прямая связь. По опыту разъяснения друзьям вывода правильных многогранников в четырёхмерном пространстве и пространствах высших размерностей, оказывается, что мало кто знает, что такое Символ Шлефли, поэтому решил посвятить этому отдельную статью с картинками, без аналитических вычислений, которые делаются у меня в других, соседних, статьях, при непосредственном выводе многогранников. В данной статье моя задача дать образно-интуитивное понимание термина Символ Шлефли, поэтому я не буду тратить ваше внимание на строгие определения и формулировки, которые можно почитать в википедии. Понятие Символа Шлефли будем осваивать от лёгкого к трудному. Самое простое на плоскости.
Контрибьютим в PostgreSQL: примеры реальных патчей, часть 1 из N
4 мин
Туториал
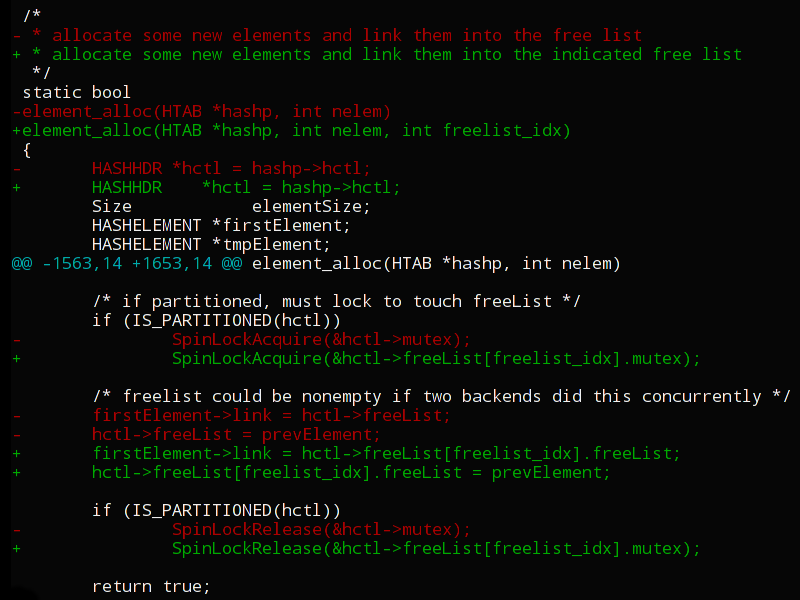
Ранее в статье Становимся контрибьютером в PostgreSQL был подробно рассмотрен процесс разработки PostgreSQL и используемые при этом инструменты, были предложены некоторые идеи для первого патча и рассказано, куда и как эти патчи нужно посылать. Также были приведены ссылки на дополнительные источники информации касательно внутреннего устройства РСУБД.
Теперь же мы рассмотрим примеры реальных патчей, принятых в PostgreSQL за последнее время. Какие-то из этих патчей были написаны непосредственно мной, при разработке других я активно участвовал в качестве ревьювера. Это сравнительно небольшие патчи. На момент написания этих строк я занимаюсь разработкой PostgreSQL менее года, и ранее разработкой СУБД я не занимался (ровно как и разработкой на языке C за деньги). Поэтому есть основания полагать, что данные патчи будут интересны новичкам, желающим начать участвовать в разработке открытых проектов, притом не обязательно именно PostgreSQL. Чтобы не писать лонгридов, статья разбита на части.
Заинтересовавшихся прошу проследовать под кат.
Примеры реальных патчей в PostgreSQL: часть 2 из N
7 мин
Туториал

В предыдущих статьях мы рассмотрели процесс разработки PostgreSQL, а также примеры некоторых реальных патчей, принятых в эту РСУБД за последнее время. При этом рассмотренные патчи были, прямо скажем, какие-то «несерьезные» — исправление опечаток, исправление простейших косяков, найденных при помощи статического анализа, и прочее в таком духе.
Сегодня мы рассмотрим примеры уже более серьезных патчей, устраняющих узкие места в коде, исправляющих достаточно серьезные баги, относительно крупные рефакторинги, и так далее. Как и ранее, основная цель статьи — не столько осветить изменения, принятые в PostgreSQL 9.6, сколько показать, что разработка open source проектов, в частности PostgreSQL, это интересно и не так сложно, как вам это может казаться.
Если эта тема вам интересна, прошу под кат.
Введение в futures-rs: асинхронщина на Rust [перевод]
18 мин
Туториал

Этот документ поможет вам изучить контейнер для языка программирования Rust — futures, который обеспечивает реализацию futures и потоков с нулевой стоимостью. Futures доступны во многих других языках программирования, таких как C++, Java, и Scala, и контейнер futures черпает вдохновение из библиотек этих языков. Однако он отличается эргономичностью, а также придерживается философии абстракций с нулевой стоимостью, присущей Rust, а именно: для создания и композиции futures не требуется выделений памяти, а для Task, управляющего ими, нужна только одна аллокация. Futures должны стать основой асинхронного компонуемого высокопроизводительного ввода/вывода в Rust, и ранние замеры производительности показывают, что простой HTTP сервер, построенный на futures, действительно быстр.
Жаргон функционального программирования
10 мин
Перевод

У функционального программирования много преимуществ, и его популярность постоянно растет. Но, как и у любой парадигмы программирования, у ФП есть свой жаргон. Мы решили сделать небольшой словарь для всех, кто знакомится с ФП.
В примерах используется JavaScript ES2015). (Почему JavaScript?)
Работа над материалом продолжается; присылайте свои пулл-реквесты в оригинальный репозиторий на английском языке.
В документе используются термины из спецификации Fantasy Land spec по мере необходимости.
Arity (арность)
Количество аргументов функции. От слов унарный, бинарный, тернарный (unary, binary, ternary) и так далее. Это необычное слово, потому что состоит из двух суффиксов: "-ary" и "-ity.". Сложение, к примеру, принимает два аргумента, поэтому это бинарная функция, или функция, у которой арность равна двум. Иногда используют термин "диадный" (dyadic), если предпочитают греческие корни вместо латинских. Функция, которая принимает произвольное количество аргументов называется, соответственно, вариативной (variadic). Но бинарная функция может принимать два и только два аргумента, без учета каррирования или частичного применения.
Вы не любите триггеры?
4 мин
Вы не любите кошек? Да вы просто не умеете их готовить! (с) Альф
 При проектировании достаточно объёмных реляционных баз данных часто принимается решение об отступлении от нормальной формы — «денормализации».
При проектировании достаточно объёмных реляционных баз данных часто принимается решение об отступлении от нормальной формы — «денормализации». Причины могут быть разными. От попытки ускорения доступа к определённым данным, ограничений используемой платформы/фреймворка/средств разработки и до недостатка квалификации разработчика/проектировщика БД.
Впрочем, строго говоря, ссылка на ограничения фреймфорка и т.п. — по сути попытка оправдать недостаток квалификации.
Денормализованные данные — слабое звено, через которое легко можно привести нашу базу в неконсистентное (нецелостное) состояние.
Что с этим делать?
Три принципа производительности в JavaScript, делающие Bluebird быстрым
7 мин
Перевод
Компания Reaktor поделилась в своём блоге принципами и примерами оптимизации JavaScript-кода, применёнными в библиотеке промисов Bluebird, созданной их сотрудником Petka Antonov (Петкой Антоновым).
Пишем, собираем и запускаем HelloWorld для Android в блокноте. Java 8 и Android N
11 мин
Туториал

Два с половиной года назад я опубликовал статью Пишем, собираем и запускаем HelloWorld для Android в блокноте. Она стала пользоваться огромной популярностью и набрала около 80 000 просмотров. С появлением новых инструментов, таких как Jack ToolChain, возникла необходимость переиздания и обновления статьи.
Когда я начал изучать Android, захотелось полностью написать и скомпилировать Android-приложение вручную — без использования IDE. Однако эта задача оказалась непростой и заняла у меня довольно много времени. Но как оказалось — такой подход принёс большую пользу и прояснил многие тонкости, которые скрывают IDE.
Используя только блокнот, мы напишем совсем маленькое учебное Android-приложение. А затем скомпилируем его, соберём и запустим на устройстве — и всё через командную строку. Заинтересовало? Тогда прошу.
Принципы и приёмы обработки очередей
16 мин

Принципы и приёмы обработки очередей
Константин Осипов (Mail.ru)
Как вы считаете, какова стоимость очередей с приоритетами? То есть если кто-то лезет вне очереди, то как посчитать стоимость для всей системы в этой ситуации, чему она пропорциональна? Времени обслуживания клиента — например, 5 минут стоит его обслужить? Она пропорциональна количеству ожидающих, потому что время ожидания для каждого из них увеличится.
Для начала о себе — я занимаюсь разработкой СУБД Tarantool в Mail.ru. Этот доклад будет об обработке очередей. У нас много очередей внутри системы, фактически вся база данных построена как система массового обслуживания.
В основном речь будет идти о проблемах балансировки нагрузки, но перед этим я хотел бы поговорить о том, зачем нужны очереди и как они появились именно в компьютерных системах, чего они позволяют добиться.