В сентябре я устроился на должность поискового дата-саентиста и с тех пор часть моих обязанностей заключается в работе с Solr — опенсорсным поисковым движком на основе Lucene. Я знал основы работы поискового движка, но мне хотелось понять его ещё лучше. Поэтому я закатал рукава и решил создать его с нуля.
Давайте поговорим о целях. Слышали когда-нибудь о «кризисе сложности обнаружения маленьких веб-сайтов»? Проблема в том. что маленькие веб-сайты наподобие моего невозможно найти при помощи Google или любого другого поискового движка. Какова же моя миссия? Сделать эти крошечные веб-сайты снова великими. Я верю в возвращение славы этих малышей вдали от SEO-безумия Google.
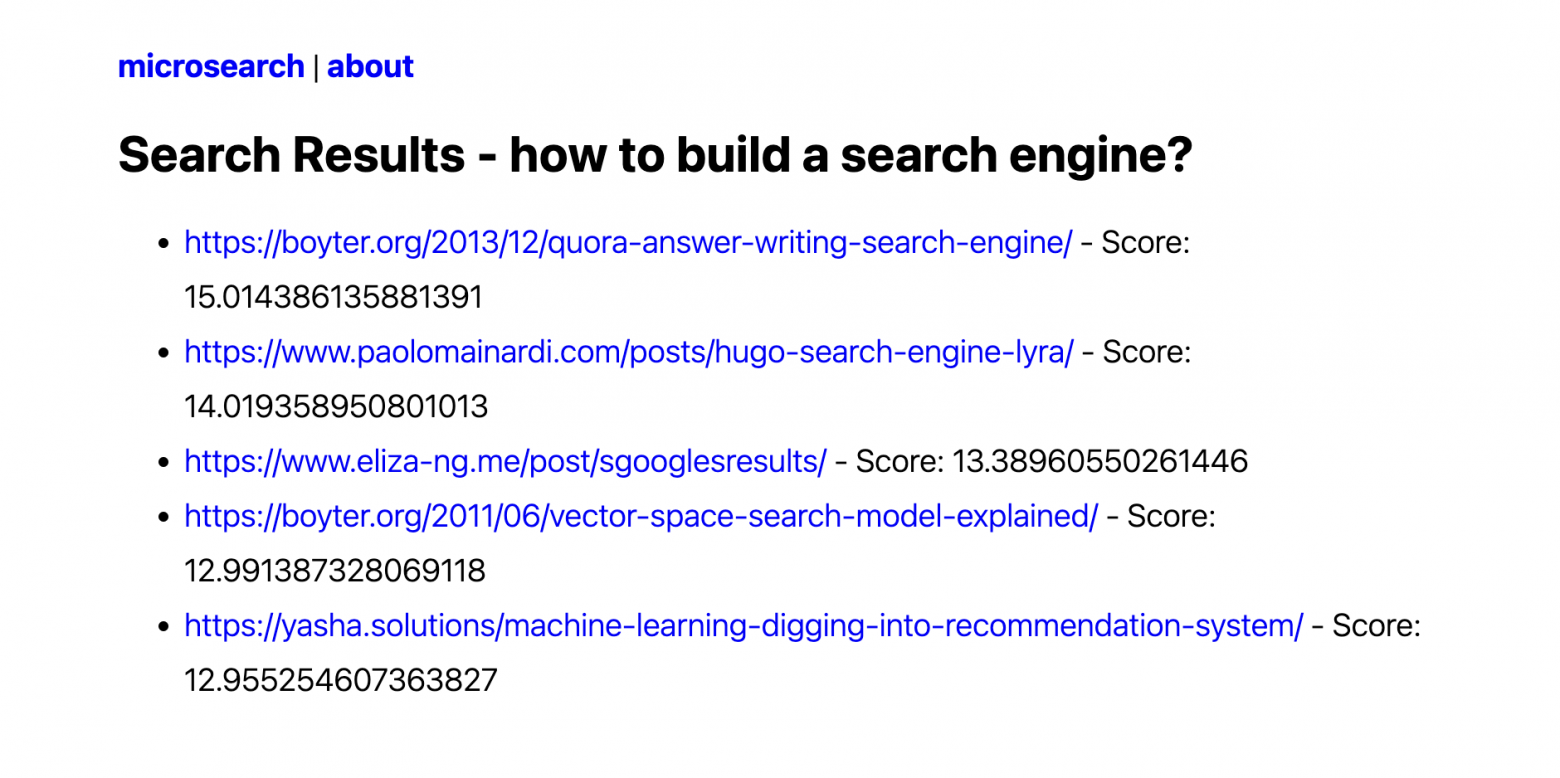
В этом посте я подробно расскажу о процессе создания поискового движка с нуля на Python. Как обычно, весь написанный мной код можно найти в моём GitHub (репозиторий microsearch). Эта реализация не будет притворяться готовым к продакшену поисковым движком, это лишь полезный пример, демонстрирующий внутреннюю работу поискового движка.
Кроме того, мне стоит признаться, что в заголовке поста я слегка преувеличил. Да, поисковый движок действительно реализован примерно в 80 строках Python, но я ещё и писал вспомогательный код (краулер данных, API, HTML-шаблоны и так далее), из-за которого весь проект становится немного больше. Однако я считаю, что интересная часть проекта находится в поисковом движке, который состоит из менее чем 80 строк.
P.S. Написав этот пост и microsearch, я осознал, что пару лет назад нечто похожее написал Барт де Гёде. Моя реализация очень похожа на работу Барта, но я считаю что кое-что улучшил, в частности: (1) мой краулер асинхронный, что сильно ускоряет работу, (2) я реализовал пользовательский интерфейс, позволяющий взаимодействовать с поисковым движком.