В этой статье мы рассмотрим два способа поиска с помощью регулярных выражений. Один широко распространён и используется в стандартных интерпретаторах многих языков. Второй мало где применяется, в основном в реализациях awk и grep. Оба подхода сильно различаются по своей производительности:
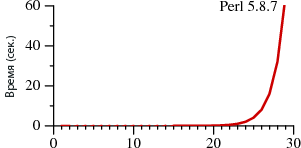
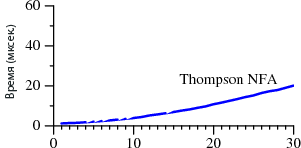
В первом случае поиск занимает A?
nA
n времени, во втором — A
n.
Степени обозначают повторяемость строк, то есть A?
3A
3 — это то же самое, что и A?A?A?AAA. Графики отражают время, требуемое для поиска через регулярные выражения.
Обратите внимание, что в Perl для поиска строки из 29 символов требуется более 60 секунд. А при втором методе — 20
микросекунд. Это не ошибка. При поиске 29-символьной строки Thompson NFA работает примерно в миллион раз быстрее. Если нужно найти 100-символьную строку, то Thompson NFA справится менее чем за 200 микросекунд, а Perl понадобится более 10
15 лет. Причём он взят лишь для примера, во многих других языках наблюдается та же картина — в Python, PHP, Ruby и т. д. Ниже мы рассмотрим этот вопрос более детально.
Наверняка вам трудно поверить приведённым данным. Если вы работали с Perl, то вряд ли подмечали за ним низкую производительность при работе с регулярными выражениями. Дело в том, что в большинстве случаев Perl обращается с ними достаточно быстро. Однако, как следует из графика, можно столкнуться с так называемыми патологическими регулярными выражениями, на которых Perl начинает буксовать. В то же время у Thompson NFA такой проблемы нет.
Возникает логичный вопрос: а почему бы в Perl не использовать метод Thompson NFA? Это возможно и следует делать, и об этом пойдёт далее речь.




 Изложенный ниже материал не претендует на эксклюзивность. Однако мне пришлось собирать его по крупицам из разных источников, что-то проверяя экспериментально. После этого родилась идея систематизировать полученные знания и опыт, изложив все в одной заметке.
Изложенный ниже материал не претендует на эксклюзивность. Однако мне пришлось собирать его по крупицам из разных источников, что-то проверяя экспериментально. После этого родилась идея систематизировать полученные знания и опыт, изложив все в одной заметке.
 Эта статья не для матёрых укротителей Python’а, для которых распутать этот клубок змей — детская забава, а скорее поверхностный обзор многопоточных возможностей для недавно подсевших на питон.
Эта статья не для матёрых укротителей Python’а, для которых распутать этот клубок змей — детская забава, а скорее поверхностный обзор многопоточных возможностей для недавно подсевших на питон. 



