Обучаемый Telegram чат-бот с ИИ в 30 строчек кода на Python
6 мин
Туториал


Пользователь

Привет, друзья!
Можете ли вы ответить на вопрос о том, в чем заключается разница между requestAnimationFrame и requestIdleCallback?
Если можете, то я завидую глубине ваших знаний. Я не смог, когда меня об этом спросили. Более того, в тот момент я даже не знал о существовании интерфейса requestIdleCallback. Теперь знаю и хочу с вами этими знаниями поделиться.
Сразу уточним, что названные интерфейсы предоставляются браузером и к ECMAScript отношения не имеют.
Что касается поддержки, то с requestAnimationFrame все хорошо, а с requestIdleCallback, в основном из-за Safari, этого современного IE, ситуация хуже.
Рассматриваемые интерфейсы позволяют разработчикам получать доступ к процессу рендеринга страницы. Также они очень тесно связаны с циклом событий (event loop) браузера.

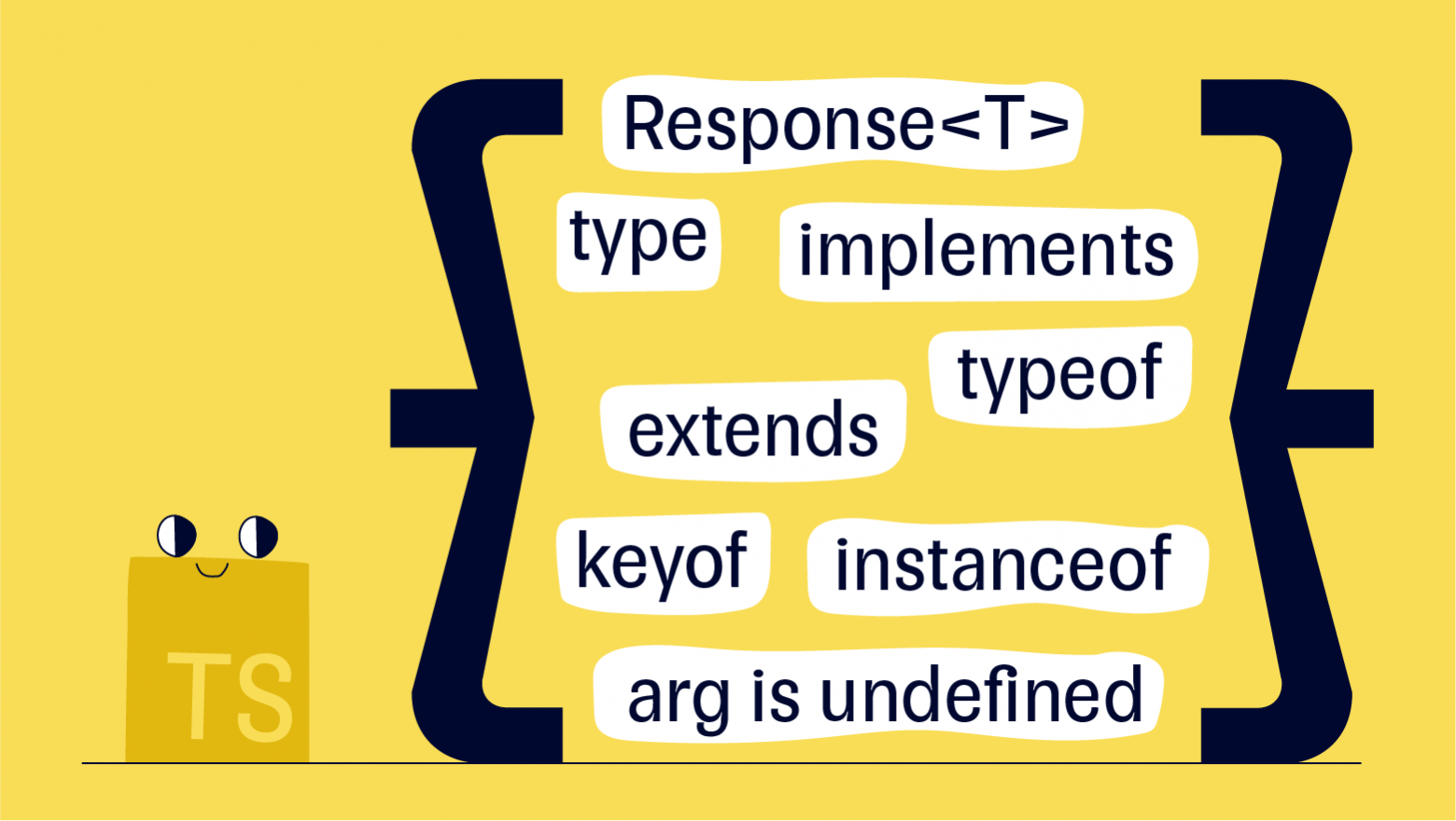
Привет, я Сергей Вахрамов, занимаюсь фронтенд-разработкой на Angular в компании Тинькофф. Во фронтенд-разработку вошел напрямую с тайпскрипта, просто перечитав всю документацию. С того момента и спецификация ECMAScript расширилась, и TypeScript сильно подрос. Казалось бы, почему разработчики могут бояться дженериков, ведь бояться там нечего? Мой опыт общения с джуниор-разработчиками говорит, что во многом ребята не используют обобщенные типы просто потому, что кто-то пустил легенду об их сложности.
Эта статья для тех, кто не использует generic-типы в TypeScript: не знают о них, боятся использовать или используют вместо реальных типов — any.

Одним из факторов, влияющих на надёжность программного обеспечения является способ обрабатывать ошибки, возникающие в процессе выполнения. Создатели Rust не стали повторять популярные методы, а выбрали другой способ, позволяющий описывать и обрабатывать ошибки более явно. В статье мы рассмотрим реализацию данного подхода, а также полезные библиотеки, упрощающие обработку ошибок.



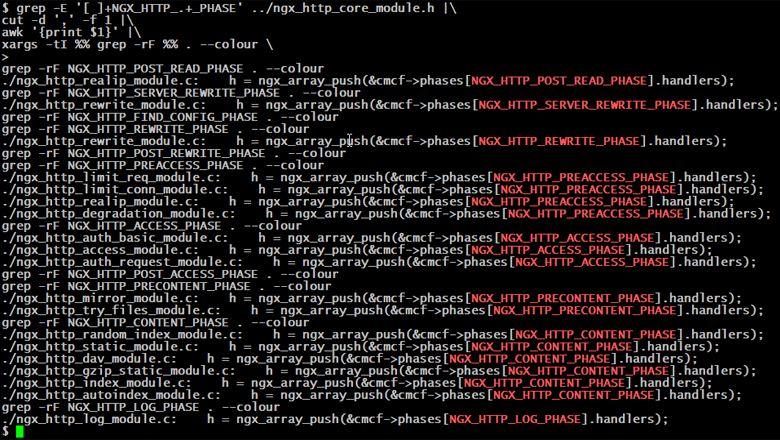
Эта статья родилась случайно. Слоняясь по книжному фестивалю и наблюдая, как дочка пытает консультантов, заставляя их искать Иэна Стюарта, мой глаз зацепился за знакомые буквы на обложке: "Nginx".
Надо же, на полках нашлось целых три книги - не полистать их было бы преступлением. Первая, вторая, третья... Ощущение, будто что-то не так. Ну вроде страниц много, текст связный, но каково содержание? Установка nginx, список переменных и модулей, а дальше docker, ansible. Открываем вторую: wget, лимиты запросов и памяти, балансировка, kubernetes, AWS. Третья: GeoIP, авторизация, потоковое вещание, puppet, Azure. Ребята, а где про то, как вообще работает nginx? На кого рассчитаны ваши книги? На состоявшегося админа, который и так знает архитектуру этого веб-сервера? Да он вроде с базовыми настройками и сам справится. На новичка, который не знает как пользоваться wget? Вы уверены, что ему знание о существовании ngx_http_degradation_module и тем паче "облака" важнее порядка прохождения запроса?
Итак. О чем не пишут в книгах.
(здесь и дальше мы говорим только о NGX_HTTP_)

Сегодня мы с вами рассмотрим свойства CSS Grid (далее также — Грид), позволяющие создавать адаптивные или отзывчивые макеты веб-страниц. Я постараюсь кратко, но полно объяснить, как работает каждое свойство.
CSS Grid?
Грид — это макет для сайта (его схема, проект).
Грид-модель позволяет размещать контент сайта (располагать его определенным образом, позиционировать). Она позволяет создавать структуры, необходимые для обеспечения отзывчивости сайтов на различных устройствах. Это означает, что сайт будет одинаково хорошо смотреться на компьютере, телефоне и планшете.
Вот простой пример макета сайта, созданного с помощью Грида.
Представьте человека, который изучает алгоритмы. Чтобы понять как они работают, приходится разбираться в их коде и представлять, как компьютер будет его выполнять. Это странно — почему мы должны учиться думать как компьютер, вместо того, чтобы заставить его помогать нам? Какая-то сильная технозависимость.
На мой взгляд, потеть должна машина, а человек учиться, не выворачивая мозги наизнанку. Поэтому я подумал, а почему бы не визуализировать работу алгоритмов? Визуализации помогли бы не закапываться в код, а наглядно показали бы как работают алгоритмы и позволили бы понять их. Что у меня получилось — читайте в этой статье.
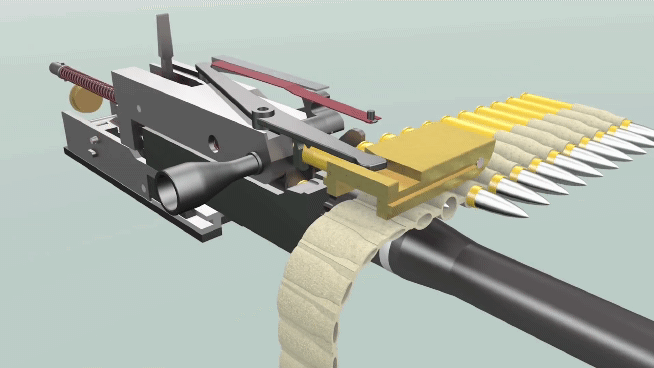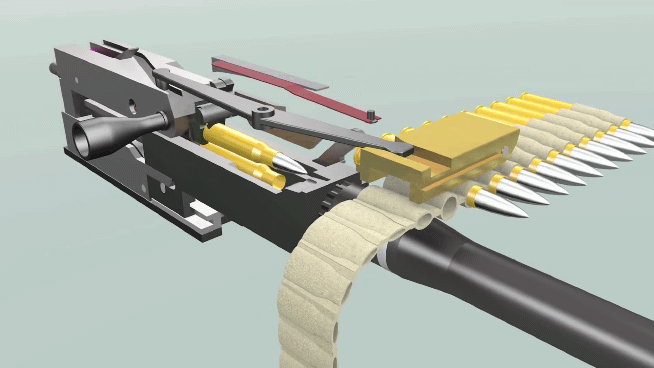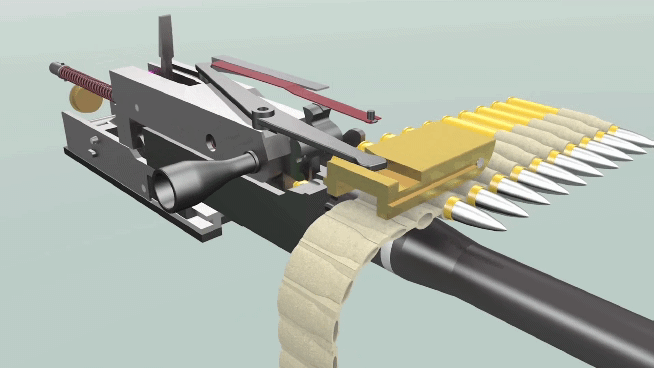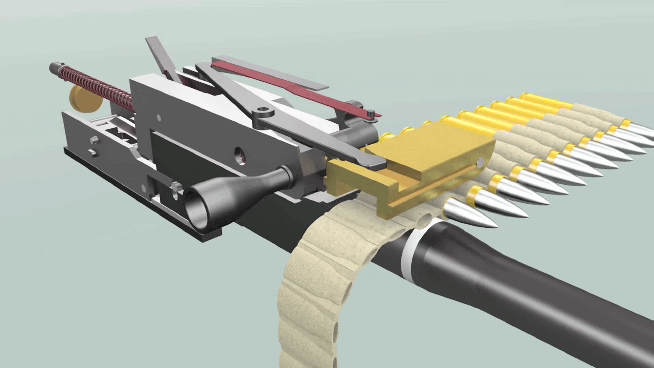
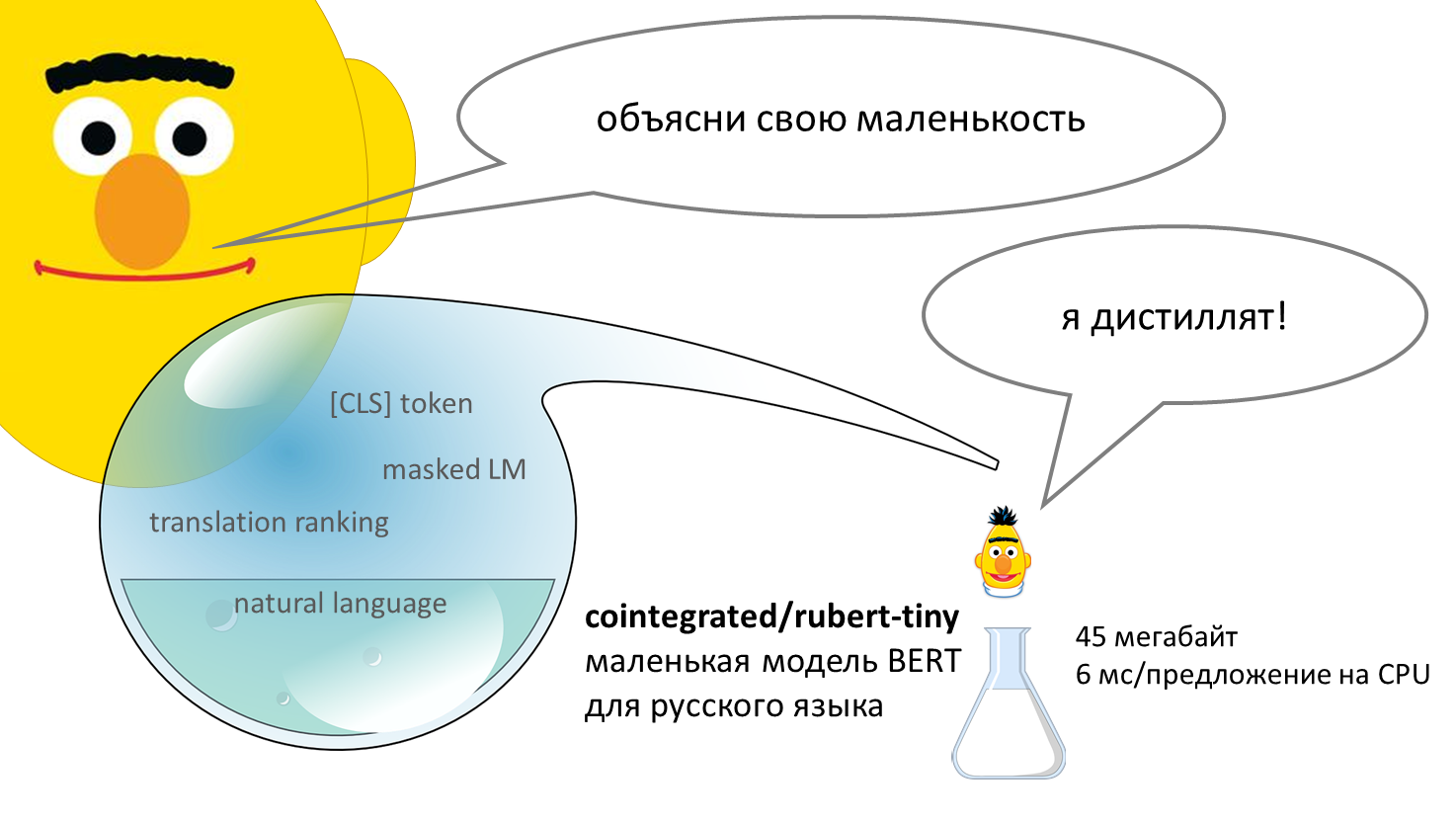
BERT – нейросеть, способная неплохо понимать смысл текстов на человеческом языке. Впервые появившись в 2018 году, эта модель совершила переворот в компьютерной лингвистике. Базовая версия модели долго предобучается, читая миллионы текстов и постепенно осваивая язык, а потом её можно дообучить на собственной прикладной задаче, например, классификации комментариев или выделении в тексте имён, названий и адресов. Стандартная версия BERT довольно толстая: весит больше 600 мегабайт, обрабатывает предложение около 120 миллисекунд (на CPU). В этом посте я предлагаю уменьшенную версию BERT для русского языка – 45 мегабайт, 6 миллисекунд на предложение. Она была получена в результате дистилляции нескольких больших моделей. Уже есть tinybert для английского от Хуавея, есть моя уменьшалка FastText'а, а вот маленький (англо-)русский BERT, кажется, появился впервые. Но насколько он хорош?
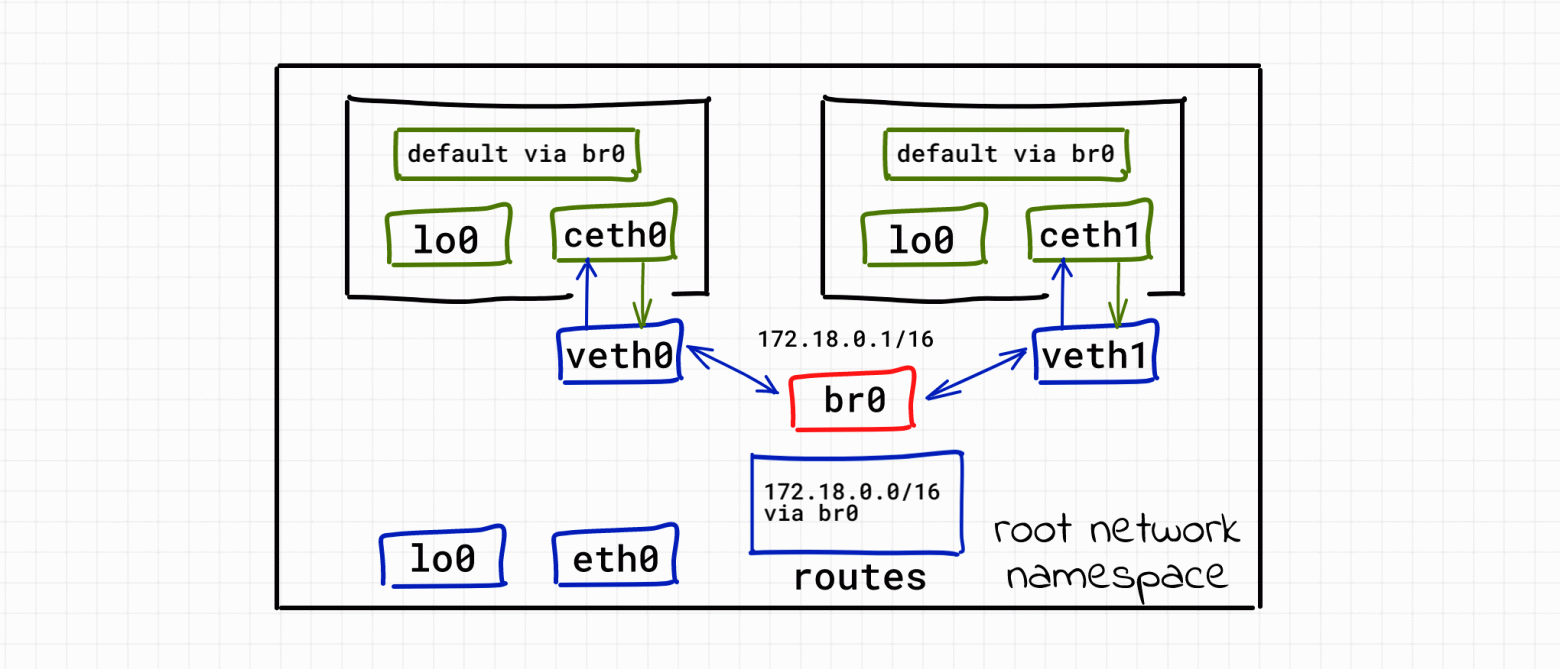
Работа с контейнерами многим кажется волшебством, пришло время разобраться как работает сеть Docker. Мы покажем на примерах, что это совсем не сложно. Нам потребуется немного сетевой магии и никакого кода...
В этой статье мы ответим на следующие вопросы:
• Как виртуализировать сетевые ресурсы, чтобы контейнеры думали, что у каждого из них есть выделенный сетевой стек?
• Как превратить контейнеры в дружелюбных соседей, не дать им мешать друг другу и научить хорошо общаться?
• Как настроить сетевой доступ из контейнера во внешний мир (например, в Интернет)?
• Как получить доступ к контейнерам, работающим на сервере, из внешнего мира (публикация портов)?


Заслуженно распространена точка зрения, что типичный разработчик высокоуровневого прикладного ПО настолько свыкся с доступностью системных ресурсов и мягкостью требований реального времени, что ожидать от него оптимизации кода в угоду снижения ресурсоёмкости приложения можно лишь в крайних случаях, когда этого прямо требуют интересы бизнеса. Это и логично, ведь в задачах прикладной автоматизации самым дорогим ресурсом остаётся ресурс человеческий. Более того, снижение когнитивных затрат на возню с байтами оставляет внимание разработчика свободным для задач первоочередной важности, таких как обеспечение функциональной корректности программы.
Редко когда речь заходит об обратной проблеме, имеющей место в куда более узких кругах разработчиков встраиваемых систем, включая системы повышенной отказоустойчивости. Есть основания полагать, что ранний опыт использования MCS51/AVR/PIC оказывается настолько психически травмирующим, что многие страдальцы затем продолжают считать байты на протяжении всей карьеры, даже когда объективных причин для этого не осталось. Это, конечно, не относится к случаям, где жёсткие ценовые ограничения задают потолок ресурсов вычислительной платформы (микроконтроллера). Но это справедливо в случаях, где цена вычислительной платформы в серии незначительна по сравнению со стоимостью изделия в целом и стоимостью разработки и верификации его нетривиального ПО, как это бывает на транспорте и сложной промышленной автоматизации. Именно о последней категории систем этот пост.
В этой подборке представлены полезные малоизвестные консольные Linux утилиты. В списке не представлены Pentest утилиты, так как у них есть своя подборка.
Осторожно много скриншотов. Добавил до ката утилиту binenv.
binenv — cамая интересная утилита для установки новых популярных программ в linux, но которых нет в пакетном менеджере.

Привет, Хабр!
В прошлой статье меня знатно разбомбили в комментариях, где-то за дело, где-то я считаю, что нет. Так или иначе, я выжил, и у меня есть чем с вами поделиться >:)
Напомню, что в той статье я рассказывал, каким я вижу идеальное собеседование и что я нашёл компанию, которая так и делает - и я туда прошёл, хотя это был адский отбор. Я, довольный как слон, везде отметил, что я не ищу работу, отовсюду удалился и стал работать работу.
Как вы думаете, что делают рекрутеры, когда видят "Alexandr, NOT OPEN FOR WORK"? Правильно, пишут "Алексей, рассматриваете вариант работать в X?" Я обычно игнорирую это, но тут мне предложили попытать счастья с Яндекс.Лавкой, и я не смог пройти мимо - интересно было, смогу ли я устроиться куда-нибудь, когда введут великий российский файерволл. К тому же за последние 3 года я проходил только два интервью, и мне показалось, что я не в теме, что нынче требуется индустрии. Блин, я оказался и вправду не в теме. И вы, скорей всего, тоже - об этом и статья.