Протокол QUIC (название расшифровывается как Quick UDP Internet Connections) — совершенно новый способ передачи информации в интернете, построенный поверх протокола UDP, вместо общепринятого ранее использования TCP. Некоторые люди называют его (в шутку)
TCP/2. Переход к UDP — наиболее интересная и мощная особенность протокола, из которой следуют некоторые другие особенности.
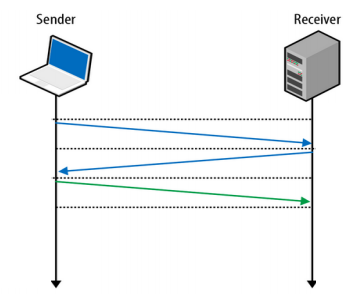
Сегодняшний Web построен на протоколе TCP, который был выбран за его надёжность и гарантированность доставки пакетов. Для открытия TCP-соединения используется так называемое «трёхкратное рукопожатие». Это означает дополнительные циклы отправки-приёма сообщений для каждого нового соединения, что увеличивает задержки.
Если вы захотите установить защищённое TLS-соединение, придётся переслать ещё больше пакетов.
Некоторые инновации, вроде
TCP Fast Open, улучшат некоторые аспекты ситуации, но эта технология пока не очень широко распространена.
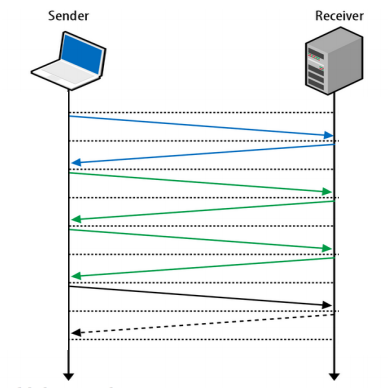
Протокол UDP, с другой стороны, построен на идее «отправить пакет и забыть о нём». Сообщение, отправленное по UDP, будет доставлено получателю (не гарантированно, с некоторой вероятностью успеха). Яркое преимущество здесь в меньшем времени установки соединения, такой же яркий недостаток — негарантированность доставки или порядка прихода пакетов получателю. Это означает, что для обеспечения надёжности придётся построить некоторый механизм поверх UDP, который гарантирует доставку пакетов.
И здесь на сцену выходит QUIC от Google.










 Всем привет! Это уже третий выпуск дайджеста на Хабрахабр о новостях из мира Python. В сегодняшнем выпуске вы найдёте интересные материалы, касающиеся машинного обучения, популярных фреймворков, внутреннего устройства языка и много другого. Присылайте свои актуальные материалы, а также любые замечания и предложения, которые будут добавлены в ближайший дайджест.
Всем привет! Это уже третий выпуск дайджеста на Хабрахабр о новостях из мира Python. В сегодняшнем выпуске вы найдёте интересные материалы, касающиеся машинного обучения, популярных фреймворков, внутреннего устройства языка и много другого. Присылайте свои актуальные материалы, а также любые замечания и предложения, которые будут добавлены в ближайший дайджест.
 Недавно мне довелось разобраться и устранить несколько утечек памяти в популярном фреймворке Торнадо. Не беда, если вы никогда его не использовали, потому что описанное будет мало связано с ним. Рассказать я хочу о методах, которые я использовал для поиска и устранения утечек.
Недавно мне довелось разобраться и устранить несколько утечек памяти в популярном фреймворке Торнадо. Не беда, если вы никогда его не использовали, потому что описанное будет мало связано с ним. Рассказать я хочу о методах, которые я использовал для поиска и устранения утечек.

