Весной мы запустили платформу Диалоги, которая позволяет создавать навыки для Алисы и распознавать голосовые запросы пользователей. Изначально разработчикам навыков приходилось разбирать запросы самостоятельно. К примеру, находить адрес в тексте. Теперь эту часть работы платформа берёт на себя.
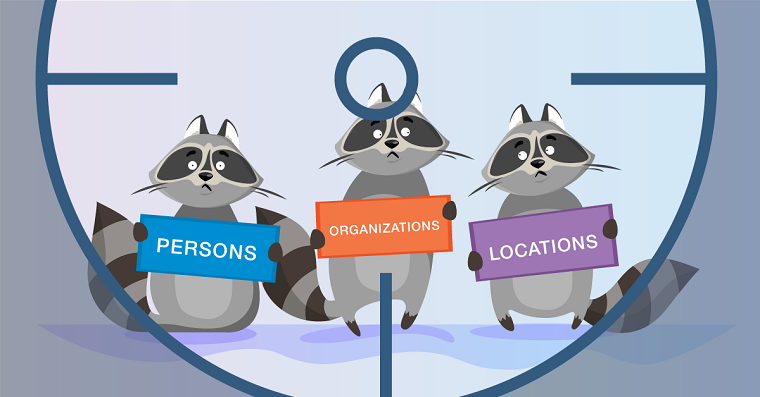
Сегодня мы расскажем читателям Хабра о распознавании именованных сущностей (Named-entity recognition; NER) и новых возможностях для разработчиков навыков.

Мы верим, что будущее за голосовыми интерфейсами. Уже сейчас во многих случаях пользователи предпочитают использовать голос, а не экранную клавиатуру. Например, при управлении автомобилем. Или для поиска быстрых ответов на простые вопросы. Или для игры в «города» лёжа на диване. Но чтобы таких сценариев становилось всё больше, простого распознавания голоса в текст недостаточно.
Сегодня мы расскажем читателям Хабра о распознавании именованных сущностей (Named-entity recognition; NER) и новых возможностях для разработчиков навыков.
Мы верим, что будущее за голосовыми интерфейсами. Уже сейчас во многих случаях пользователи предпочитают использовать голос, а не экранную клавиатуру. Например, при управлении автомобилем. Или для поиска быстрых ответов на простые вопросы. Или для игры в «города» лёжа на диване. Но чтобы таких сценариев становилось всё больше, простого распознавания голоса в текст недостаточно.