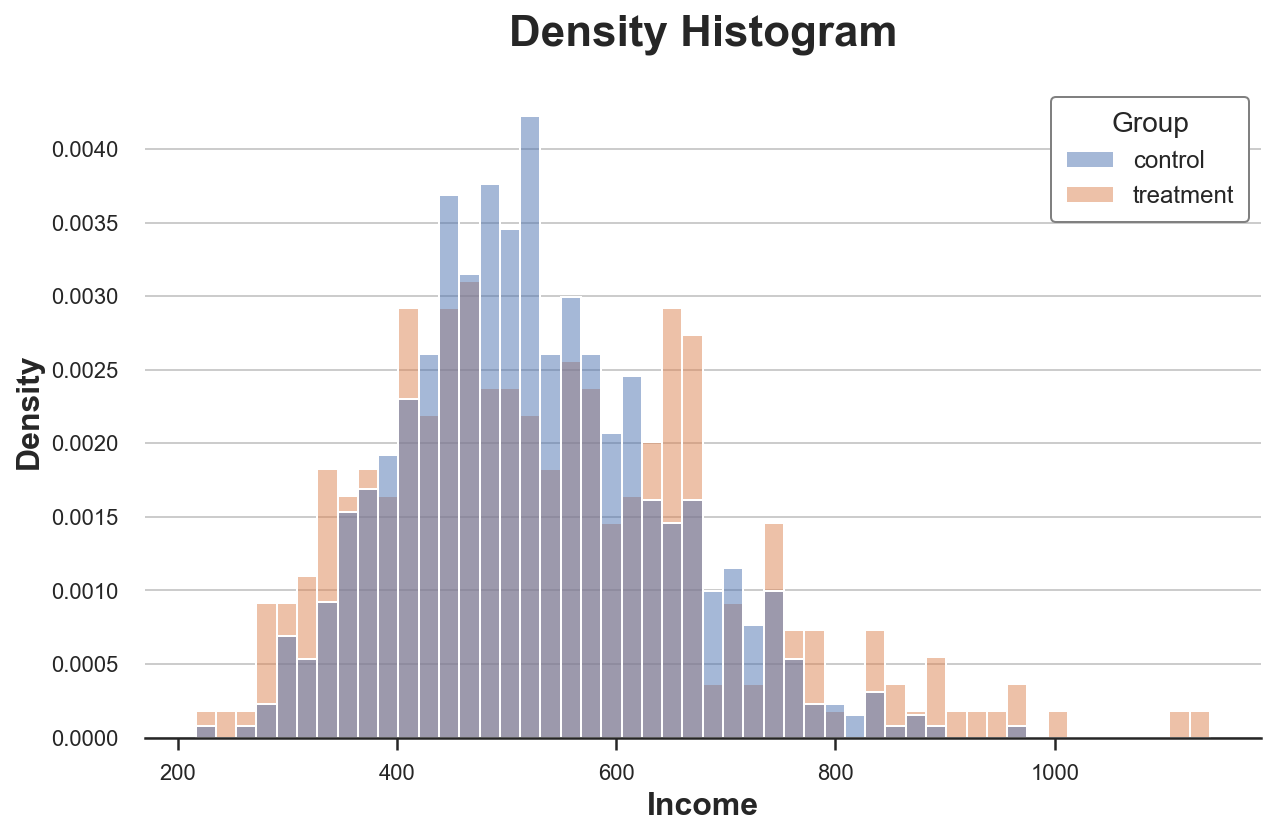
В подробном лонгриде к старту курса по анализу данных вы найдёте авторские визуализации, пояснения и комментарии об искусстве сравнивать распределения и делать выводы.

Data Science в Tinkoff
В подробном лонгриде к старту курса по анализу данных вы найдёте авторские визуализации, пояснения и комментарии об искусстве сравнивать распределения и делать выводы.

Мы школа онлайн-образования, которая уже три года делает курсы по Data Science и разработке. Одна из наших целей – собрать коммьюнити классных специалистов и делиться крутыми и неочевидными знаниями. Так был рождён Симулятор ML – место, в котором начинающие и опытные специалисты решают задачи разной сложности, разрабатывают проекты в командах, осваивают новые инструменты, развивают продуктовое мышление и постоянно растут в профессии.
А, как это свойственно коммьюнити, горящему идеей, студенты и авторы хотят делиться своими инсайтами и открытиями, которые дадут свежий взгляд на устоявшиеся практики. Сегодня хотим поделиться статьей автора Симулятора ML Богдана Печёнкина о том, как лучше использовать анализ ошибок для разработки ML систем.
Сейчас существенная часть машинного обучения основана на решающих деревьях и их ансамблях, таких как CatBoost и XGBoost, но при этом не все имеют представление о том, как устроены эти алгоритмы "изнутри".
Данный обзор охватывает сразу несколько тем. Мы начнем с устройства решающего дерева и градиентного бустинга, затем подробно поговорим об XGBoost и CatBoost. Среди основных особенностей алгоритма CatBoost:
• Упорядоченное target-кодирование категориальных признаков
• Использование решающих таблиц
• Разделение ветвей по комбинациям признаков
• Упорядоченный бустинг
• Возможность работы с текстовыми признаками
• Возможность обучения на GPU
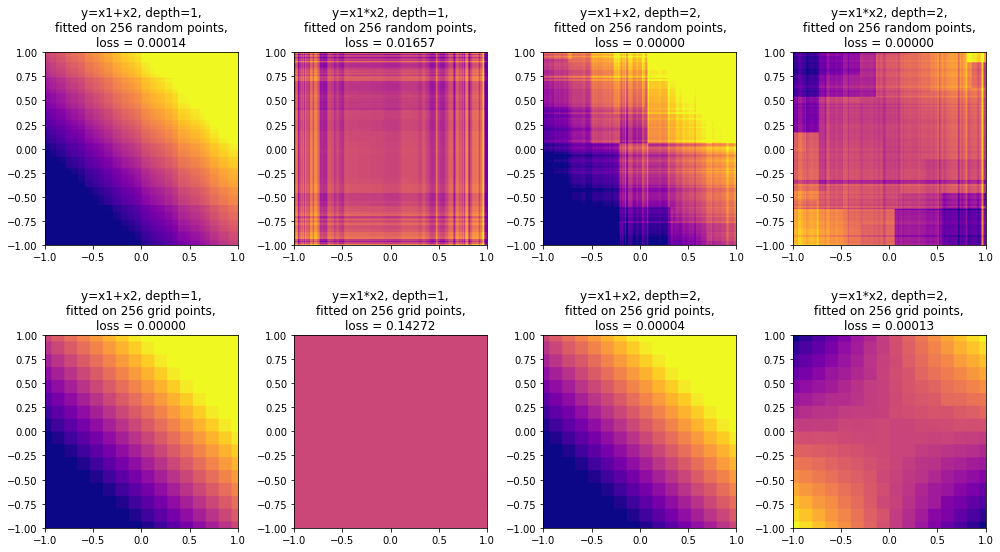
В конце обзора поговорим о методах интерпретации решающих деревьев (MDI, SHAP) и о выразительной способности решающих деревьев. Удивительно, но ансамбли деревьев ограниченной глубины, в том числе CatBoost, не являются универсальными аппроксиматорами: в данном обзоре приведено собственное исследование этого вопроса с доказательством (и экспериментальным подтверждением) того, что ансамбль деревьев глубины N не способен сколь угодно точно аппроксимировать функцию  . Поговорим также о выводах, которые можно из этого сделать.
. Поговорим также о выводах, которые можно из этого сделать.
Привет, чемпион!
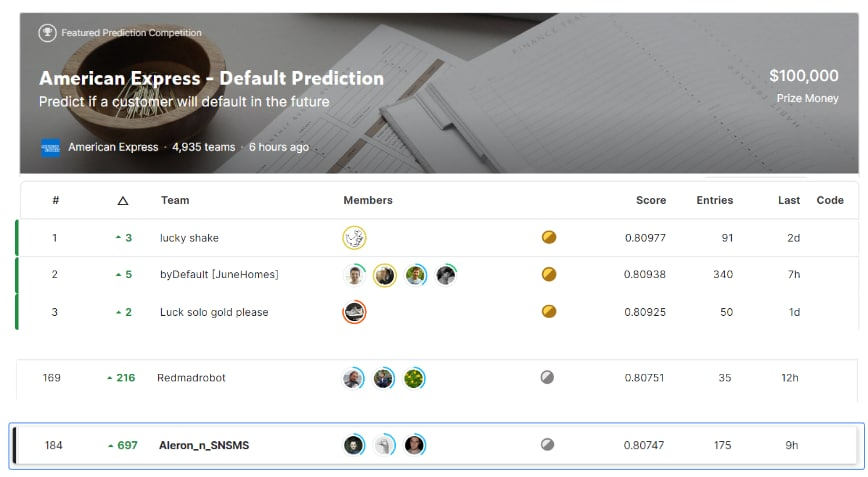
Летом прошел чемпионат на Kaggle - "American Express - Default Prediction", требовалось предсказывать - выйдет ли пользователь в дефолт или нет. Табличное соревнование в 5К участников с очень плотным лидербордом.
Вот ведь парадокс, все умеют решать табличные соревнования, все знают, что бустинги "стреляют" точнее всех, но почему-то все равно не все могут забраться в топ лидерборда. В чем проблема?! Мы с командой все-таки смогли забрать серебро? и сейчас я расскажу, как можно было выиграть медаль в этом чемпионате.

Optuna — это фреймворк для для автоматизированного поиска оптимальных гиперпараметров для моделей машинного обучения. Она подбирает оптимальные гиперпараметры методом проб и ошибок.
В данной статье представлен обзор фреймворка Optuna, рассмотрены ее основные возможности, базовые примеры использования.

Здесь будет рассказано о главных отличиях самого старого и базового алгоритма снижения размерности - PCA от его популярных современных коллег - UMAP и t-SNE. Предполагается, что читатель уже предварительно что-то слышал про эти алгоритмы, поэтому подробного объяснения каждого из них в отдельности приведено не будет. Вместо этого будут объяснены самые важные для практики свойства этих алгоритмов и то, на какие связанные с ними подводные камни можно налететь при неосторожности. Все особенности будут описаны на примерах, с минимумом теории; те пытливые умы, что почувствуют в процессе чтения жажду математической строгости, смогут удовлетворить её в литературе, ссылки на которую будут даны по ходу дела и в конце статьи.
Оптимизация фонда оплаты труда (далее - ФОТ) в долгосрочной перспективе вредит компаниям, ухудшает их положение и усиливает кризисы.
Этот вопрос мы рассмотрим на основе проблем в Boeing и Blizzard, разбора жёсткого поведения Amazon в отношении сотрудников, с примерами лучших практик Генри Форда и General Electric, а так же ссылками на исследования, с описанием психологических аспектов и ключевых трендов. И рекомендациями: что с этим делать.
Цель данной публикации - описать ключевые аспекты и нюансы проблемы, чтобы любой мог прийти к финансистам, кадровикам или генеральному директору с ней со словами “хватит вредить бизнесу оптимизацией ФОТ!"
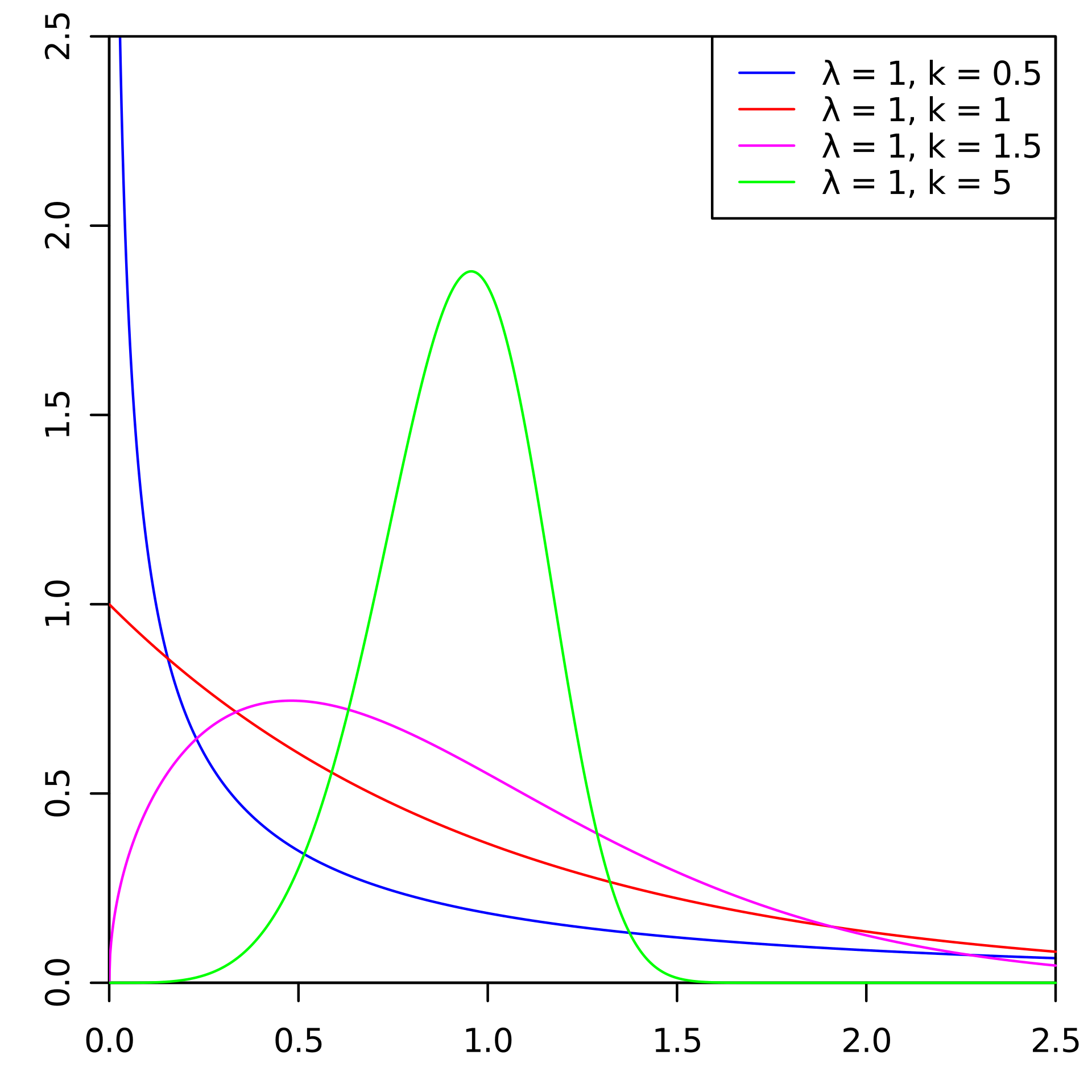
На Хабре имеется небольшое количество статей, главным образом в помощь начинающим аналитикам данных, в которых описываются всевозможные статистические распределения случайных величин. Упоминания об одном единственном я в них не нашел. Имя ему К-распределение. Хочу вам показать этого единорога.
На практике такое распределение используется, как правило, довольно узкими специалистами. В основном при математическом моделировании работы радиолокационных станций (РЛС), а также радаров с синтезированной апертурой и то в определенных условиях. Аналитиками данных в повседневной жизни конечно же не используется. Хотя, возможно К-распределение может описывать какие-то процессы, кто знает, эта сторона вопроса требует дополнительного изучения. Предлагаю аналитикам данных над этим подумать, а также всем желающим.
 Статистика приходит к нам на помощь при решении многих задач, например: когда нет возможности построить детерминированную модель, когда слишком много факторов или когда нам необходимо оценить правдоподобие построенной модели с учётом имеющихся данных. Отношение к статистике неоднозначное. Есть мнение, что существует три вида лжи: ложь, наглая ложь и статистика. С другой стороны, многие «пользователи» статистики слишком ей верят, не понимая до конца, как она работает: применяя, например, тест Стьюдента к любым данным без проверки их нормальности. Такая небрежность способна порождать серьёзные ошибки и превращать «поклонников» теста Стьюдента в ненавистников статистики. Попробуем поставить точки над i и разобраться, какие модели случайных величин должны использоваться для описания тех или иных явлений и какая между ними существует генетическая связь.
Статистика приходит к нам на помощь при решении многих задач, например: когда нет возможности построить детерминированную модель, когда слишком много факторов или когда нам необходимо оценить правдоподобие построенной модели с учётом имеющихся данных. Отношение к статистике неоднозначное. Есть мнение, что существует три вида лжи: ложь, наглая ложь и статистика. С другой стороны, многие «пользователи» статистики слишком ей верят, не понимая до конца, как она работает: применяя, например, тест Стьюдента к любым данным без проверки их нормальности. Такая небрежность способна порождать серьёзные ошибки и превращать «поклонников» теста Стьюдента в ненавистников статистики. Попробуем поставить точки над i и разобраться, какие модели случайных величин должны использоваться для описания тех или иных явлений и какая между ними существует генетическая связь.Недавно на Хабре вышла статья за авторством MilashchenkoEA , в которой автор восполняет обнаруженный им пробел в доступных материалах по методам построения кривых плотности распределения вероятности по имеющемуся набору числовых данных. Акцент в статье сделан на методическую сторону получения (оценки) плотности вероятности случайной величины, поэтому автор не преследует цели получения оптимального, с вычислительной точки зрения, алгоритма. Что ж, в данной заметке попытаемся исправить эту ситуацию, а также взглянем под другим углом на способ решения данной задачи.