
Адаптация алгоритма Дейкстры для расчёта кратчайших путей в IP-сетях.
Для сетевиков, программистов и интересующихся.

Любитель математики
Адаптация алгоритма Дейкстры для расчёта кратчайших путей в IP-сетях.
Для сетевиков, программистов и интересующихся.

Беспилотные автомобили, продвинутые голосовые ассистенты, рекомендательные системы – это только малая часть тех классных продуктов, которые создаются с помощью инженеров по машинному обучению и, думаю, не для кого не секрет, что за кулисами сего чуда стоит математика. Именно она играет главную роль в понимании алгоритмов машинного и глубокого обучения.
Машинное обучение держится на трёх основных столпах:

Простой и красивый синтаксис, множество библиотек под самые разные задачи и большое комьюнити делают Python одним из самых популярных языков программирования на сегодняшний день, который активно используется в data science и машинном обучении, веб-разработке и других областях программирования.
Когда я начал изучать питон, у меня возникло несколько вопросов.

То, что данные называют нефтью 21 века известно уже давно: на них учатся нейросети, их мгновенная обработка и передача сильно упростили нашу жизнь, и одной из самых распространенных структур хранения данных является реляционная.
Основным инструментом для взаимодействия с реляционными БД является структурированный язык запросов или же SQL.
Вкратце, на мой взгляд, необходимо знать следующие разделы:
Кластеризация — это набор методов без учителя для группировки данных по определённым критериям в так называемые кластеры, что позволяет выявлять сходства и различия между объектами, а также упрощать их анализ и визуализацию. Из-за частичного сходства в постановке задач с классификацией кластеризацию ещё называют unsupervised classification.
В данной статье описан не только принцип работы популярных алгоритмов кластеризации от простых к более продвинутым, но а также представлены их упрощённые реализации с нуля на Python, отражающие основную идею. Помимо этого, в конце каждого раздела указаны дополнительные источники для более глубокого ознакомления.

На сегодняшний день градиентный бустинг (gradient boosting machine) является одним из основных production-решений при работе с табличными, неоднородными данными, поскольку обладает высокой производительностью и точностью, а если быть точнее, то его модификации, речь о которых пойдёт чуть позже.
В данной статье представлена не только реализация градиентного бустинга GBM с нуля на Python, но а также довольно подробно описаны ключевые особенности его наиболее популярных модификаций.

Дерево решений CART (Classification and Regressoin Tree) — алгоритм классификации и регрессии, основанный на бинарном дереве и являющийся фундаментальным компонентом случайного леса и бустингов, которые входят в число самых мощных алгоритмов машинного обучения на сегодняшний день. Деревья также могут быть не бинарными в зависимости от реализации. К другим популярным реализациям решающего дерева относятся следующие: ID3, C4.5, C5.0.

Наивный байесовский классификатор (Naive Bayes classifier) — вероятностный классификатор на основе формулы Байеса со строгим (наивным) предположением о независимости признаков между собой при заданном классе, что сильно упрощает задачу классификации из-за оценки одномерных вероятностных плотностей вместо одной многомерной.
Помимо теории и реализации с нуля на Python, в данной статье также будет приведён небольшой пример использования наивного Байеса в контексте фильтрации спама со всеми подробными расчётами вручную.

Привет, Хабр! Меня зовут Кирилл Колодяжный, я ведущий инженер-программист в YADRO. Помимо основных рабочих задач, включающих исследование проблем производительности СХД, я увлекаюсь машинным обучением. Участвовал в коммерческих проектах, связанных с техническим зрением, 3D-сканерами и обработкой фотографий. В задачах часто использовал С++, хотя машинное обучение традиционно ассоциируется с Python. Этот язык программирования буквально захватил сферу, его используют повсюду — от обучающих курсов до серьезных ML-проектов.
Однако Python — не единственный язык, на котором можно решать задачи машинного обучения. Так, альтернативой может стать С++. Если последний вам ближе, вам будет интересен и полезен этот текст.
Под катом разберемся:
• как организовать работу с данными и загрузку обучающего датасета,
• как описать структуру нейронной сети,
• как использовать уже готовые алгоритмы машинного обучения из доступных библиотек и фреймворков,
• как организовать конвейер обучения сети,
• как использовать предобученные глубокие сети для решения задач.

К-ближайших соседей (K-Nearest Neighbors или просто KNN) — алгоритм классификации и регрессии, основанный на гипотезе компактности, которая предполагает, что расположенные близко друг к другу объекты в пространстве признаков имеют схожие значения целевой переменной или принадлежат к одному классу.
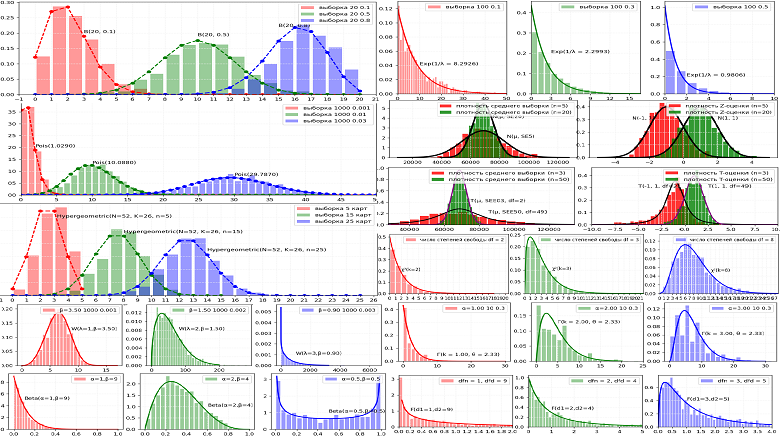
Статистические исследования и эксперименты являются краеугольным камнем развития любой компании. Особенно это касается интернет-проектов, где учёт количества пользователей в день, времени нахождения на сайте, нажатий на целевые кнопки, покупок товаров является обычным и необходимым явлением. Любые изменения в пользовательском опыте на сайте компании (внешний вид, структура, контент) приводят к изменениям в работе пользователя и, как результат, изменения наблюдаются в собираемых данных. Важным элементом анализа изменений данных и его фундаментом является использование основных типов распределений случайных величин, от понимания которых напрямую зависит качество оценки значимости наблюдаемого изменения. Рассмотрим их подробнее на наглядных примерах.
В C и C++ есть особенности, о которых вас вряд ли спросят на собеседовании (вернее, не спросили бы до этого момента). Почему не спросят? Потому что такие аспекты имеют мало практического значения в повседневной работе или попросту малоизвестны.
Целью статьи является не освещение какой-то конкретной особенности языка или подготовка к собеседованиям, и уж тем более нет цели рассказать все потайные смыслы языка, т. к. для этого не хватит одной статьи и даже книги. Напротив, статья нужна для того, чтобы показать малоизвестные и странные решения, принятые в языках C и C++. Своего рода солянка из фактов. Вопрос “что делать с этими знаниями?” я оставляю читателю.
Если вы, как и я, любите и интересуетесь C/C++, и эти языки являются неотъемлемой частью вашей жизни, в том числе и его углубленного изучения, то эта статья для вас. По большей части я надеюсь, что эта статья сможет развлечь и заставить поработать головой. И если получится, рассказать что-то, чего вы, возможно, еще не знали.

Бывает ли у вас ощущение, что несмотря на все усилия, вы не получаете тех результатов, на которые рассчитываете? Что последние несколько лет в жизни ничего не меняется или становится только хуже. Кажется, что вы зашли в тупик – развития нет, роста нет, перспективы не радуют. Если это про вас, то причина, скорее всего, в одной из ловушек мышления, которые мешают развитию.

Написать этот материал меня побудило... отсутствие хороших статей по корутинам в C++ в русскоязычном интернете, как бы странно это не звучало. Ну серьезно, C++20 существует уже несколько лет как, но до сих пор почти все статьи про корутины, что встречаются в рунете, относятся к одному из двух типов. Или обзор начинается с самых глубин и мелочей, пересказывая cppreference, а потом автор выдыхается и все сводится к "ну а дальше все понятно, возьмите и примените это в своем коде", что напоминает известную картинку с совой. Либо иногда в статьях рассматривается применение корутин на примере генераторов, и этим все и ограничивается. Но, давайте будем честны, генераторы — это замечательно, но за все время моей многолетней карьеры разработчика я, вероятно, делал что‑то подобное генераторам разве что разок, в то время как асинхронный ввод‑вывод приходится использовать почти в каждом проекте. И поэтому меня гораздо больше интересует реализация асинхронного ввода‑вывода с использованием корутин, а не генераторы. Поэтому пришлось разбираться во всем самому.

 Статистика приходит к нам на помощь при решении многих задач, например: когда нет возможности построить детерминированную модель, когда слишком много факторов или когда нам необходимо оценить правдоподобие построенной модели с учётом имеющихся данных. Отношение к статистике неоднозначное. Есть мнение, что существует три вида лжи: ложь, наглая ложь и статистика. С другой стороны, многие «пользователи» статистики слишком ей верят, не понимая до конца, как она работает: применяя, например, тест Стьюдента к любым данным без проверки их нормальности. Такая небрежность способна порождать серьёзные ошибки и превращать «поклонников» теста Стьюдента в ненавистников статистики. Попробуем поставить точки над i и разобраться, какие модели случайных величин должны использоваться для описания тех или иных явлений и какая между ними существует генетическая связь.
Статистика приходит к нам на помощь при решении многих задач, например: когда нет возможности построить детерминированную модель, когда слишком много факторов или когда нам необходимо оценить правдоподобие построенной модели с учётом имеющихся данных. Отношение к статистике неоднозначное. Есть мнение, что существует три вида лжи: ложь, наглая ложь и статистика. С другой стороны, многие «пользователи» статистики слишком ей верят, не понимая до конца, как она работает: применяя, например, тест Стьюдента к любым данным без проверки их нормальности. Такая небрежность способна порождать серьёзные ошибки и превращать «поклонников» теста Стьюдента в ненавистников статистики. Попробуем поставить точки над i и разобраться, какие модели случайных величин должны использоваться для описания тех или иных явлений и какая между ними существует генетическая связь.
