Хотя метод был разработан и представлен в 2001 году Полом Виолой и Майклом Джонсом [1, 2], он до сих пор на момент написания моего поста является основополагающим для поиска объектов на изображении в реальном времени [2]. По следам топика хабраюзера Indalo о данном методе, я попытался сам написать программу, которая распознает эмоцию на моём лице, но, к сожалению, не увидел на Хабре недостающей теории и описания работы некоторых алгоритмов, кроме указания их названий. Я решил собрать всё воедино, в одном месте. Сразу скажу, что свою программу успешно написал по данным алгоритмам. Как получилось рассказать о них ниже, решать Вам, уважаемые Хабрачитатели!

Вадим @wadik69
Пользователь
Работа каскада Хаара в OpenCV в картинках: теория и практика
7 мин

В прошлой статье мы подробно описали алгоритм распознавания номеров (ссылка), который заключается в получении текстового представления на заранее подготовленном изображении, содержащем рамку с номером + небольшие отступы для удобства распознавания. Мы лишь вскользь упомянули, что для выделения областей, где содержатся номера, использовался метод Виолы-Джонса. Данный метод уже описывался на хабре (ссылка, ссылка, ссылка, ссылка). Сегодня мы проиллюстрируем наглядно то, как он работает и коснёмся ранее необсужденных аспектов + в качестве бонуса будет показано, как подготовить вырезанные картинки с номерами на платформе iOS для последующего получения уже текстового представления номера.
Использование каскада Хаара для сравнения изображений
4 мин
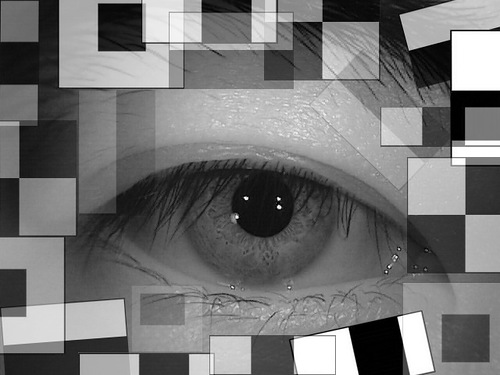
Признаки Хаара, про которые я расскажу, известны большинству людей, которые так или иначе связаны с системами распознавания и машинного обучения, но, судя по всему, мало кто использует их для решения задач вне стандартной области применения. Статья посвящена применению каскадов Хаара для сравнения близких изображений, в задачах сопровождение объекта между соседними кадрами видео, поиска соответствия на нескольких фотографиях, поиска образа на изображении и прочих подобных задач.
Suppgram: open-source служба поддержки на Telegram-ботах
Простой
7 мин

Однажды ко мне пришли с запросом. Нужно было поднять горячую линию, в которую могли бы обращаться люди и получать ответы на свои вопросы, переписываясь с волонтёрами. Звучит как саппорт-система? Да, потому что это она и есть.
Осложнялась задача тем, что её нужно было сделать к завтрашнему дню. А, ну и, конечно, бесплатно!
Так у меня на руках оказался прототип системы, которая отлично справилась с поставленной задачей и которую я в качестве упражнения аккуратно переписал в open-source проект, который представляю вам сегодня — Suppgram. В статье я расскажу, чем оказались удобны Telegram-боты, как я подошёл к архитектуре проекта и как мне (не?) помогло знание паттернов проектирования.
Моржовый оператор в Python
3 мин
Перевод

Моржовый (walrus) оператор, появившийся в Python 3.8, дает возможность решить сразу две задачи: присвоить значение переменной и вернуть это значение, поэтому порой можно написать код короче и сделать его более читаемым, и он может быть даже более эффективным с точки зрения вычислений.
Давайте посмотрим на моржовый оператор и приведем примеры того, где он может быть полезен.
Методы оптимизации в машинном и глубоком обучении. От простого к сложному
Сложный
29 мин
Туториал

В данной статье представлен обзор различных популярных (и не только) оптимизаторов, которые применяются в машинном и глубоком обучении, в частности для обучения нейронных сетей. Мы рассмотрим их основную идею и ключевые особенности, переходя от простых к более сложным концепциям. Помимо этого, в самом конце вы сможете найти большое количество дополнительных источников для более детального ознакомления с материалом.
Архитектура Stable Diffusion: Face ID, Lighting
Средний
7 мин
Обзор

Это перевод моей статьи на medium.com.
Год назад я провёл краткий обзор по теме переноса стиля. Пару месяцев назад я решил вернуться к этому вопросу и исследовать прогресс за последний год. За это время случилось много значимых изменений: архитектура open-source модели Stable Diffusion стала, лидирующей среди моделей для задач генерации изображений. Особенно её модификация SDXL [1]. Hugging Face превратился в лидирующую платформу для запуска модели Stable Diffusion с помощью библиотеки diffusers [2].
Погружение в метаклассы в Python
Средний
16 мин
FAQ

Задумывались ли вы, почему функция isinstance(int, object) возвращает True? Объяснение, что все является объектом, которое можно часто услышать, хоть и является правдой, но не дает ответа на вопрос и на самом деле есть профанация, потому что не дает настоящего понимания, а создает только его видимость. Ведь совсем непонятно, почему int (как и любой другой стандартный класс) является непременно экземпляром базового класса. Да, он является подклассом, но почему именно экземпляром? Ответ будет дан по ходу изложения.
Фундамент AI: обратное распространение ошибки простыми словами
Простой
7 мин
Туториал

Что если бы я вам сказал, что без понимания того, что такое backpropagation (обратное распространение ошибки), вы никогда не сможете использовать AI эффективно? Тогда я бы, конечно, соврал. Знать такие детали не требуется для использования AI в прикладных задачах, но, тем не менее, это базовый фундамент ML/AI, и понимать, как все устроено, полезно, ну или как минимум, интересно.
Как сделать pruning, чтобы потом не плакать
Простой
14 мин
Туториал

Обрезка нейросетей или же, если вникать в термины, pruning — то, что помогает уменьшить размер нашей модели без потери ее эффективности. Да, это далеко не новинка — в стэнфордских лекциях еще в 2017 году об этом говорили!
Идея проста: мы просто убираем из модели все, что нам не нужно. Как в магазине, когда решил экономить: если в корзине лежат лишние товары, то почему бы их не убрать? Так и здесь — мы убираем избыточные нейроны и связи, которые только занимают место, но не приносят особой пользы.
Принцип обрезки можно применять в разных ситуациях. Например, если у нас есть модель, которая обучена для распознавания ста классов объектов, а нам на самом деле нужно только десять, то почему бы не убрать те девяносто лишних? Это позволит нам сделать модель поменьше, но не менее эффективной. А если мы создаем модель с нуля, то обрезка может помочь нам сразу сделать ее компактнее и эффективнее.
Короче, pruning — это для тех, кто хочет сделать свои модели легче и быстрее без потери качества.
ClearML Data Management
15 мин
Туториал

Очевидный для ML-инженера факт: если на вход модели подать мусор — на выходе тоже будет мусор. Это правило действует всегда, независимо от того, насколько у нас крутая модель. Поэтому важно понимать, как ваши данные будут храниться, использоваться, версионироваться и воспроизведутся ли при этом результаты экспериментов. Для всех перечисленных задач есть множество различных инструментов: DVC, MLflow, W&B, ClearML и другие. Git использовать недостаточно, потому что он не был спроектирован под требования ML. Но есть инструмент, который подходит для версионирования данных и не только — это ClearML. О нем я сегодня и расскажу.
Миссия выполнима: как Smart Engines обучила нейросеть распознавать все страницы паспорта РФ и находить подделки
Простой
8 мин
Ретроспектива

Восемь лет упорного труда, немного удачи и ... девять из тринадцати крупнейших банков России наши клиенты. В этой статье мы расскажем, как мы решили задачу распознавания (даже в темноте) и проверки подлинности паспорта и почему корпорации теперь отказываются от ручного ввода данных (спойлер: чтобы не утекли).
Градиенты наносят ответный удар: атакуем распознавание паспорта
Средний
7 мин
Обзор

В данной статье мы продолжим говорить про атаки на нейронные сети (часть 1 тут). Сегодня мы возьмем нейронную сеть, решающую реальную задачу, и покажем, какие изображения генерируют разные методы атак и как это влияет на качество распознавания с количественной точки зрения. Делать это мы будем с помощью фреймворка Adversarial Robustness Toolbox (ART).
Как мы искали оранжевый спасательный плот c помощью черно-белой камеры
7 мин

В этой публикации мы расскажем о том, как мы решали реальную, стратегически важную задачу компьютерного зрения и машинного обучения, разрабатывали подсистему бортового программного обеспечения для пилотируемых и беспилотных спасательных летательных аппаратов, предназначенную для детектирования и распознавания на изображениях малоразмерных трудноразличимых объектов.
MIDV-2020: как мы создали крупнейший датасет документов, удостоверяющих личность
8 мин
Ретроспектива

В этой статье мы хотим рассказать как мы создали крупнейший на данный момент набор искусственно созданных документов с большим разнообразием типов документов, их содержания и условий съемки. Каждый из документов имеет уникальные (хоть и выдуманные) значения текстовых полей, уникальную подпись и уникальные искусственно созданные лица.
Как правильно генерировать обучающие данные для OCR?
Простой
7 мин

Мы в Smart Engines много пишем про распознавание документов. И, конечно, для распознавания документов нам требуется обучать нейросети, в частности, сети, распознающие текст на картинке. А им, как известно, нужно больше золота данных. И сегодня мы бы хотели поговорить о влиянии обучающих данных на итоговую сеть и о том, как такие данные синтезировать.
Топовые подходы к решению алгоритмических задач
11 мин

Привет! Меня зовут Дмитрий Королёв, я бэкенд-разработчик в Авито. В этой статье я расскажу про ключевые аспекты и концепции работы с наиболее популярными алгоритмами и структурами данных. Это поможет и в реальных проектах, и чтобы глубже понять алгоритмические принципы. Статья подойдёт специалистам, которые хотят углубить свои знания в программировании, и укрепить навыки нахождения оптимальных решений алгоритмических задач.
Вы должны перестать вручную писать Dockerfile'ы
Средний
3 мин
Перевод

Вы тоже устали вручную заполнять Dockerfile и docker-compose.yaml под каждый новый проект?
Я всегда задумывался, применяю ли я известные best practices, когда пишу конфиг для Docker, и не занесу ли я случайно какие-нибудь уязвимости, вручную заполняя конфиг-файлы.
Что же, теперь мне больше не придется беспокоиться об этом, благодаря добрым людям из Docker, которые недавно реализовали инструмент для этого - docker init .
Интересно, как экономить время и быстро генерировать конфиги, даже если вы не профи в Docker? Прошу под кат.
Книга «SQL. Pocket guide, 4-е изд.»
7 мин
 Привет, Хаброжители!
Привет, Хаброжители!Если вы аналитик или инженер по обработке данных и используете SQL, популярный карманный справочник станет для вас идеальным помощником. Найдите множество примеров, раскрывающих все сложности языка, а также ключевые аспекты SQL при его использовании в Microsoft SQL Server, MySQL, Oracle Database, PostgreSQL и SQLite.
В обновленном издании Элис Жао описывает, как в этих СУБД используется SQL для формирования запросов и внесения изменений в базу. Получите подробную информацию о типах данных и их преобразованиях, синтаксисе регулярных выражений, оконных функциях, операторах PIVOT и UNPIVOT и многом другом.
Дескрипторы в Python
Простой
7 мин
Обзор

Привет, Хабр!
Дескриптор — это объектовый атрибут с поведением, определяемым методами в его классе. Если просто — это способ, с помощью которого объект может контролировать доступ к его атрибутам, используя специально определенные методы __get__, __set__, и __delete__. Если говорить еще проще — дескрипторы позволяют задавать точки доступа к атрибутам объекта, добавляя дополнительную логику, когда атрибут читается, записывается или удаляется.
В этой статье поговорим подробней про дескрпиторы.