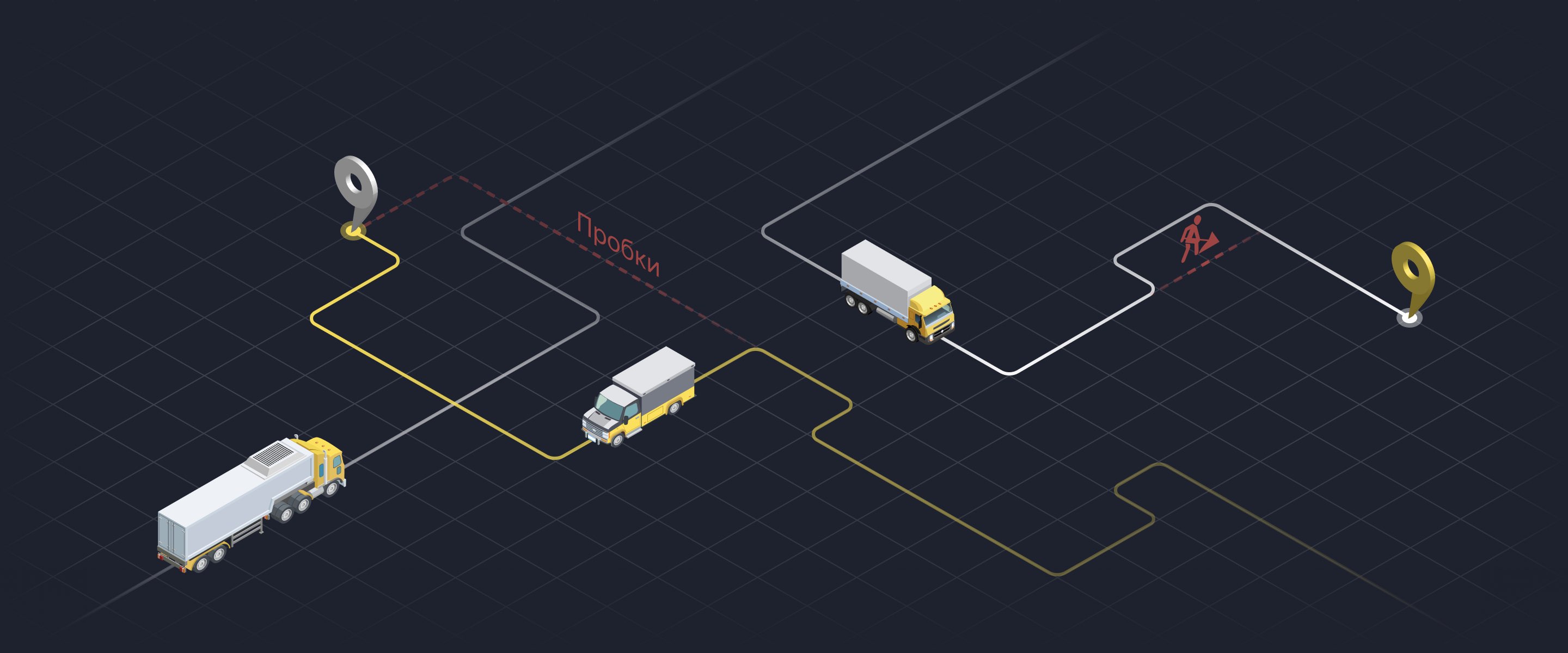
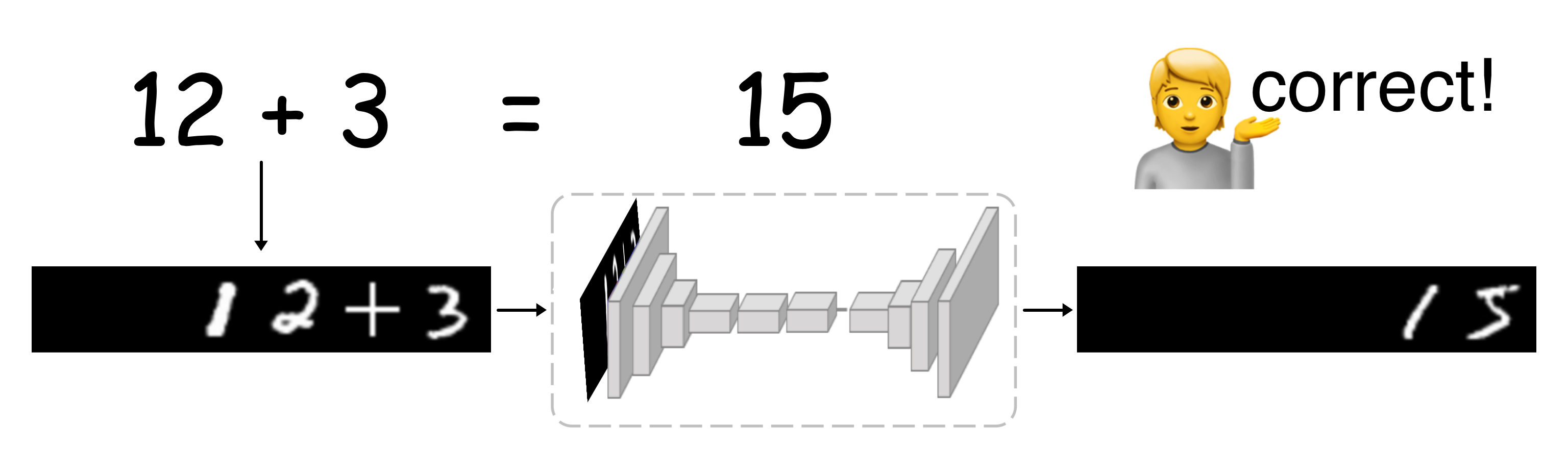
Международные научные конференции помогают следить за трендами в индустрии, узнавать о передовых разработках ведущих компаний, университетов и рассказывать о себе. Конечно, это относится только ко времени, когда мир не погружён в пучину пандемии.
До того, как все страны перешли на режим самоизоляции, мы командой
Яндекс.Толоки успели съездить на конференцию WSDM (произносится как wisdom), чтобы провести туториал по краудсорсингу, презентовать нашу статью и пообщаться с коллегами по цеху.
Меня зовут Алексей Друца, я руководитель отдела эффективности и развития управления краудсорсинга и платформизации в Яндексе. В компании занимаюсь теоретическими и прикладными исследованиями в областях, связанных с дискретными алгоритмами, теорией аукционов, машинным обучением, анализом данных и вычислительной математикой. За время работы я опубликовал более 20 научных статей, в том числе в рамках конференций NIPS, KDD, WWW, WSDM, SIGIR и CIKM. В этом посте расскажу о своих впечатлениях после посещения WSDM, а также сделаю небольшой обзор самых интересных докладов.
 Плакат конференции
Плакат конференции








 Проведение испытаний и оценка качества работы радиоустройств — то ещё веселье. Для таких лабораторных исследований порой требуется специфическое оснащение, которое стоит больших денег. В том числе — безэховые экранированные боксы.
Проведение испытаний и оценка качества работы радиоустройств — то ещё веселье. Для таких лабораторных исследований порой требуется специфическое оснащение, которое стоит больших денег. В том числе — безэховые экранированные боксы.