Привет, Хабр!
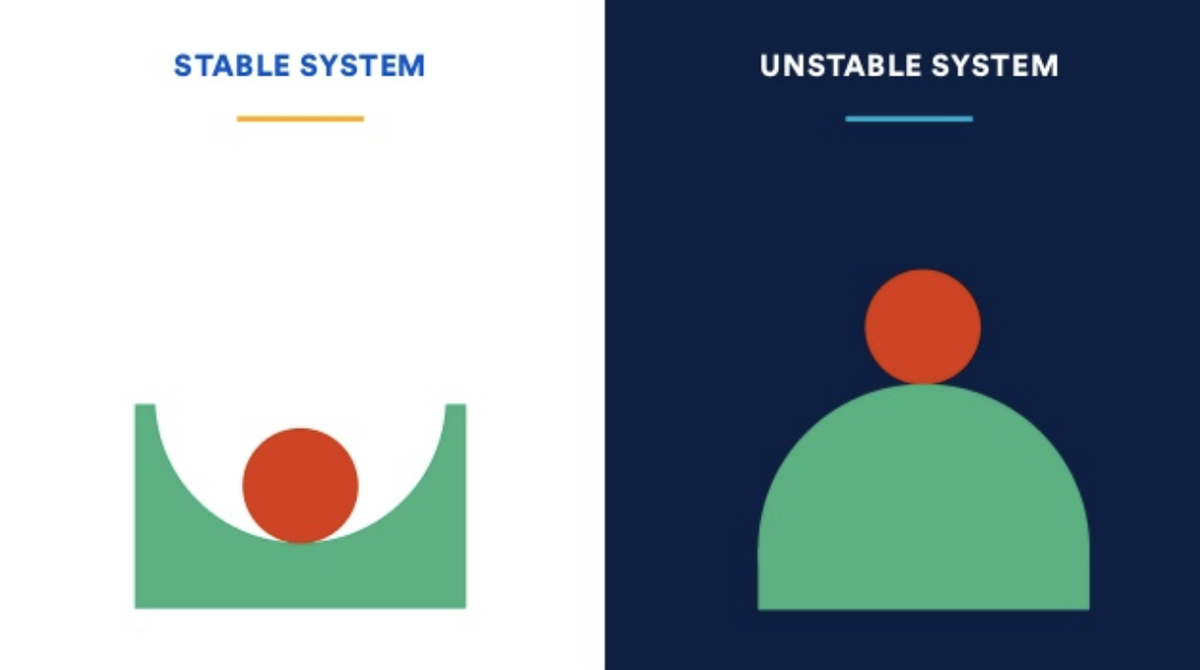
Каждая миллисекунда имеет значение, кэширование стало безусловно важной частью проектирования высокопроизводительных приложений. Оптимизация скорости и доступности данных стала приоритетом для разработчиков, и кэширование является одним из наиболее эффективных способов достижения этой цели. Redis и Memcached играют занимают важную роль в этом процессе.
Redis и Memcached – два из самых популярных и мощных инструментов для реализации кэширования. Redis, изначально разработанный как in-memory хранилище данных, позволяет эффективно хранить и быстро извлекать информацию в памяти, что делает его идеальным выбором для кэширования. Memcached, с другой стороны, специализируется исключительно на кэшировании данных и предоставляет простой, но мощный способ ускорить доступ к данным.