Как мы решали задачу оптимизации доставки грузов с использованием численных методов на примере метода имитации отжига

В статье хотим поделиться своим опытом реализации алгоритма решения задачи маршрутизации на основе метода имитации отжига в Norbit CDS – умной системе управления доставкой.
Проанализировав материалы, можно обнаружить различные предлагаемые способы решения VRP-задач (Vehicle Routing Problem). Главная их цель – планирование маршрутов для транспортных средств оптимальным способом. Основными критериями, как всегда, остаются наикратчайший путь для транспортного средства и доставка услуг во все заданные точки. В рабочем месте логиста Norbit CDS задача не отличается.
Создавая свой алгоритм оптимизации построения маршрутов доставки, мы исходили из следующих входных данных: количество транспортных средств, число заявок для распределения с учетом их габаритов и окон желаемого времени доставки. Для реализации был выбран метод отжига.

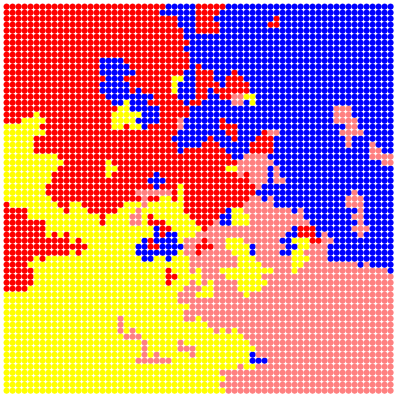
 на плоскости, имеющих метки 0 или 1. Требуется выделить область
на плоскости, имеющих метки 0 или 1. Требуется выделить область  , в которой отношение числа 1 к числу 0 максимально, при условии, что число нулей в этой области не меньше заданного числа.
, в которой отношение числа 1 к числу 0 максимально, при условии, что число нулей в этой области не меньше заданного числа.