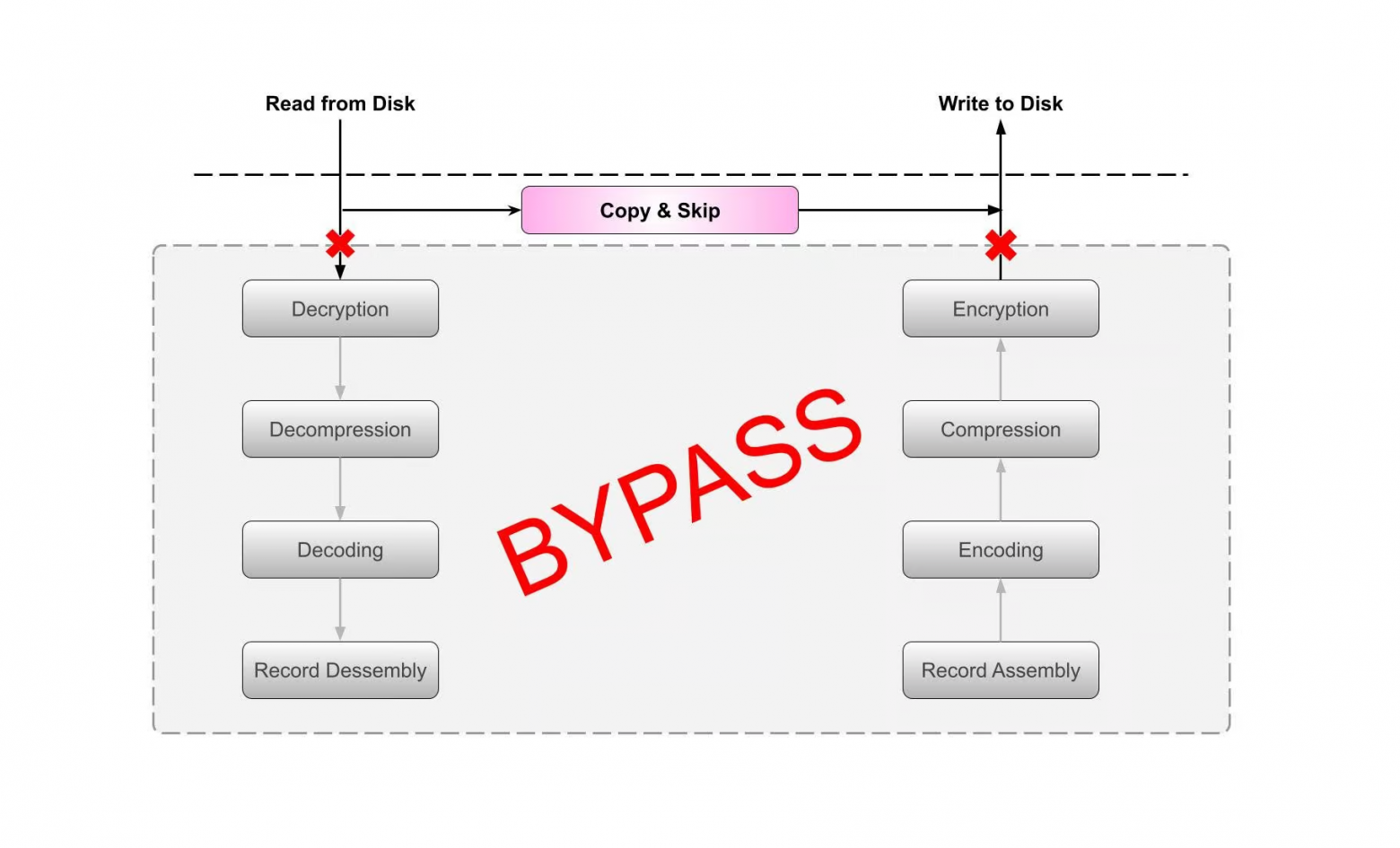
В голосовых технологиях используется глубокое обучение (особый вид машинного обучения), позволяющее обучать Speech-to-Text (STT) — компонент обработки голоса, получающий от пользователя в аудиоформате входные данные (например, речь) и преобразующий этот фрагмент в текст. [
Ссылка] В этом отношении большинство обучающих модели STT компаний полностью зависят от ручной транскрипции всех обучающих фрагментов, однако затраты на связанное с этой методикой аннотирование данных оказываются очень высокими.
Эта проблема применения ручного труда также влияет и на Natural Language Understanding (NLU) — компонент, получающий текстовое описание пользовательского ввода и извлекающий из него структурированные данные (например, запросы действий и сущности), которые позволяют системе понимать человеческий язык. [
Ссылка] Например, в некоторых задачах NLU (например, в Named Entity Recognition, распознавании именованных сущностей) требуется присвоение метки каждому слову во фразе, чтобы система поняла, что это слово означает в пользовательском вводе.