Привет, Хабр!
Этот пост написан специально для студентов. Если вы уже состоявшийся профессионал, лучше посмотрите, как в gif’ках выглядит жизнь Open Source разработчика, а если вы студент, да еще с
ИТ-шной специальностью, добро пожаловать под кат.
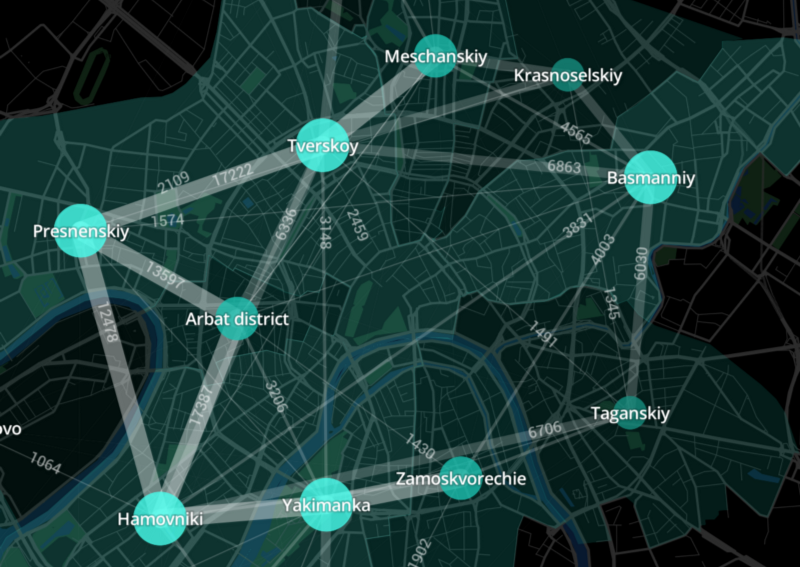
Чем хороша наша программа стажировок Sberseasons? У нас есть много больших интересных проектов на выбор. Они завязаны на современный технологический стек, и их потом можно положить в свое портфолио. Плюс, её можно совмещать с учебой. Разумеется, она у нас оплачивается.
Стажировка доступна сразу по 18 IT-направлениям. О некоторых из них рассказываем подробнее.

Этот пост написан специально для студентов. Если вы уже состоявшийся профессионал, лучше посмотрите, как в gif’ках выглядит жизнь Open Source разработчика, а если вы студент, да еще с
ИТ-шной специальностью, добро пожаловать под кат.
Чем хороша наша программа стажировок Sberseasons? У нас есть много больших интересных проектов на выбор. Они завязаны на современный технологический стек, и их потом можно положить в свое портфолио. Плюс, её можно совмещать с учебой. Разумеется, она у нас оплачивается.
Стажировка доступна сразу по 18 IT-направлениям. О некоторых из них рассказываем подробнее.