Как собрать датасет за неделю: опыт студентов магистратуры «Наука о данных»
12 мин
Привет, Хабр! Сегодня хотим представить вам некоммерческий открытый датасет, собранный командой студентов магистратуры «Наука о данных» НИТУ МИСиС и Zavtra.Online (подразделении SkillFactory по работе с вузами) в рамках первого учебного Дататона. Мероприятие проходило как один из форматов командной практики. Данная работа заняла первое место из 18 команд.
Датасет содержит полный список объектов торговли и услуг в Москве с транспортными, экономическими и географическими метаданными. Исходная гипотеза состоит в том, что близость объекта к транспортным узлам является одним из важнейших показателей и ключевым фактором экономического успеха. Мы попросили команду детально описать свой опыт сбора такого датасета, и вот что получилось.
TLTR: Ближе к концу статьи вы найдёте информативные графики, карты и ссылки.
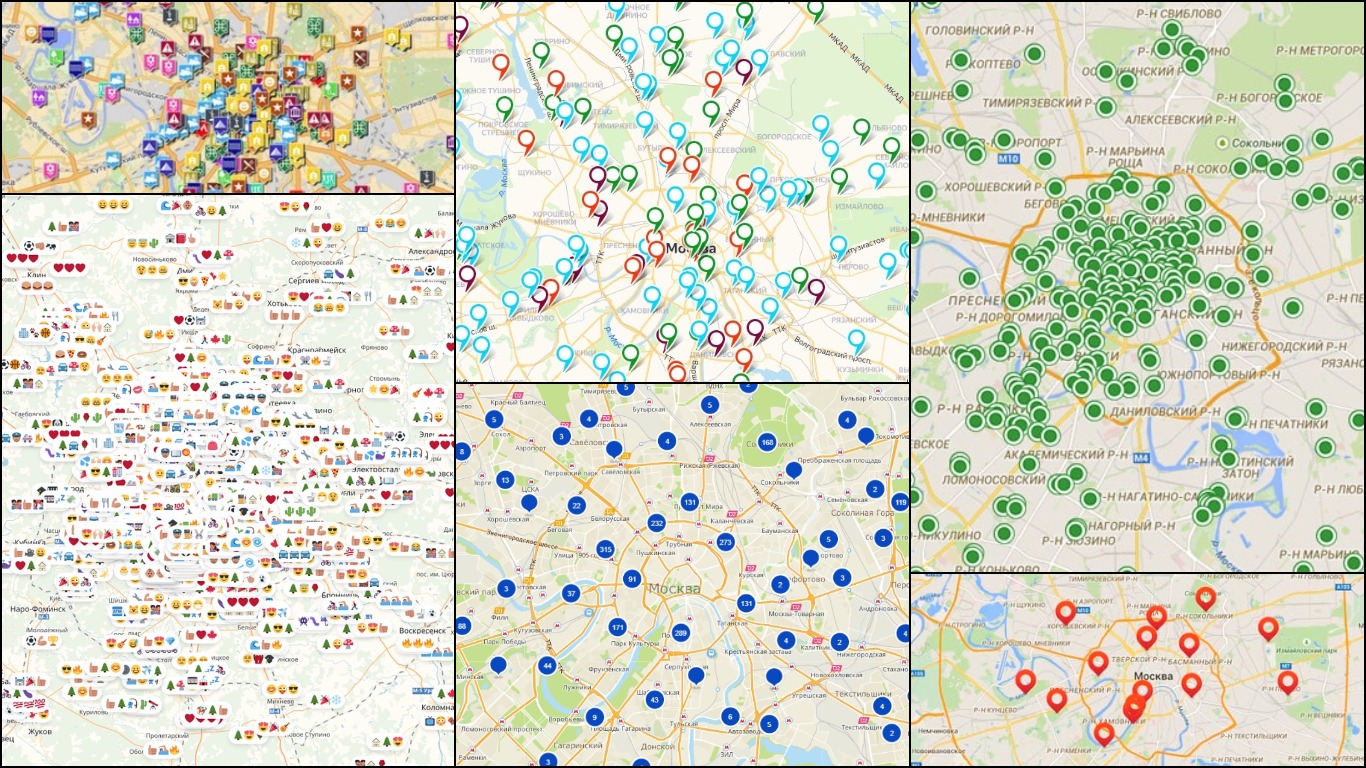
Датасет содержит полный список объектов торговли и услуг в Москве с транспортными, экономическими и географическими метаданными. Исходная гипотеза состоит в том, что близость объекта к транспортным узлам является одним из важнейших показателей и ключевым фактором экономического успеха. Мы попросили команду детально описать свой опыт сбора такого датасета, и вот что получилось.
TLTR: Ближе к концу статьи вы найдёте информативные графики, карты и ссылки.