GPU, гексагональные ускорители и линейная алгебра
18 мин
Все эти слова гораздо сильнее связаны с мобильной разработкой, чем кажется на первый взгляд: гексагональные ускорители уже помогают обучать нейронные сети на мобильных устройствах; алгебра и матан пригодится, чтобы устроиться работать в Apple; а GPU-программирование не только позволяет ускорять приложения, но и учит видеть суть вещей.
Во всяком случае, так говорит руководитель мобильной разработки Prisma Андрей Володин. А еще о том, как идеи перетекают в мобильную разработку из GameDev, чем отличаются парадигмы, почему в Android нет нативного размытия — да много еще чего, продуктивный вышел выпуск AppsCast. Под катом поговорим про доклад Андрея на AppsConf без спойлеров.

Во всяком случае, так говорит руководитель мобильной разработки Prisma Андрей Володин. А еще о том, как идеи перетекают в мобильную разработку из GameDev, чем отличаются парадигмы, почему в Android нет нативного размытия — да много еще чего, продуктивный вышел выпуск AppsCast. Под катом поговорим про доклад Андрея на AppsConf без спойлеров.
 Это Лесли Лэмпорт — автор основополагающих работ в распределённых вычислениях, а ещё вы его можете знать по буквам La в слове LaTeX — «Lamport TeX». Это он впервые, ещё в 1979 году, ввёл понятие
Это Лесли Лэмпорт — автор основополагающих работ в распределённых вычислениях, а ещё вы его можете знать по буквам La в слове LaTeX — «Lamport TeX». Это он впервые, ещё в 1979 году, ввёл понятие 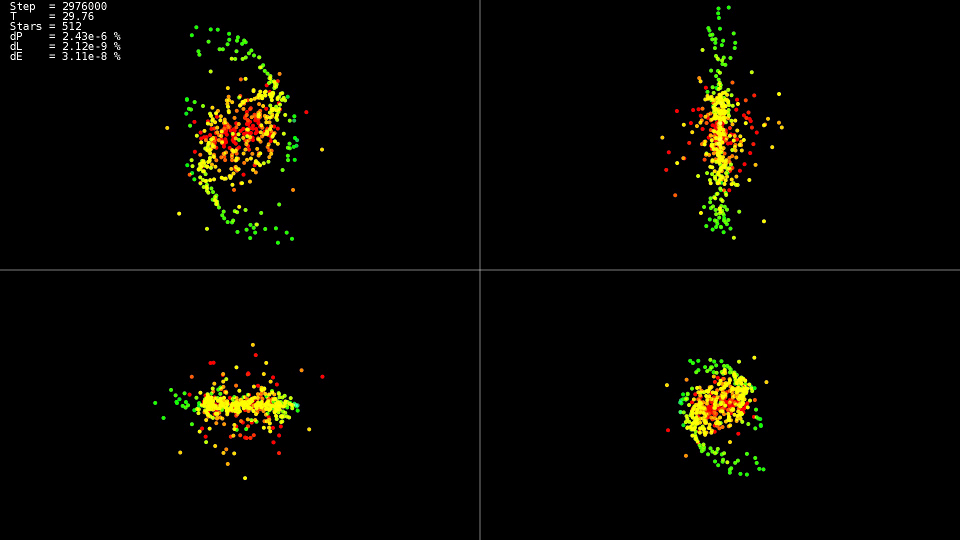


 Во время разработки
Во время разработки 

 Я говорю о неверном использовании функции
Я говорю о неверном использовании функции