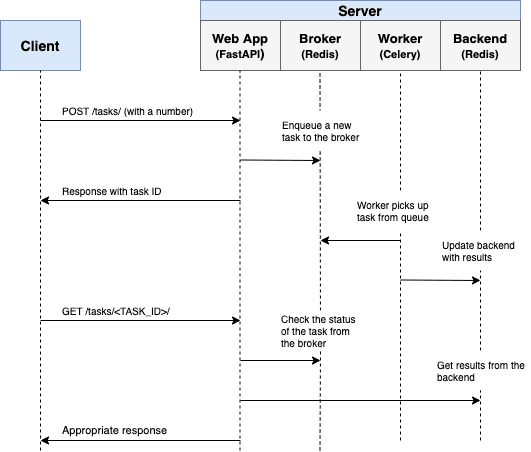
Всем добрый день, в сегодняшней рубрике я хочу затронуть достаточно интересную тему с точки зрения программирования, которая будет интересна даже обычным пользователям. Это – Telegram боты. Я создаю их уже около трёх лет, и сегодня я бы хотел вам рассказать, насколько это может быть полезно, а если данный материал станет вам интересным, то в будущем я мог бы углубиться в эту тему.
Начнём, пожалуй, с основ и терминологии. Telegram бот – это набор кода, который во время активации выполняет роль пользователя и его функционал зависит только от способностей и потребностей его создателя. Telegram ботом может воспользоваться каждый. Главное знать его название для поисковика.
На сегодняшний день Telegram ботов насчитывается бесчисленное количество. Создать своего не является проблемой. Разработка может быть, как через специальные сервисы, которые по заданным параметрам создадут вам необходимое технологическое решение для работы, так и с помощью самописного кода, но правда для этого вам нужно знать основы языков программирования таких как Python, Java или C++.
Хочу остановиться поподробнее на втором варианте, потому что для меня создавать своё всегда интереснее. При желании в интернете есть огромное количество материалов, которые помогут вам сделать его более работоспособным, а в этой статье я лишь покажу основы.
Итак, от долгой лирики к делу! Для того чтобы создать своего бота вам необходим аккаунт в Telegram. Далее, в поисковой строке вам нужно найти главного бота @BotFather. Это ваш личный менеджер и главный генерал ваших ботов. В его функционал входят регистрация ботов, их удаление, создание аватарки и название бота. Напишите этому боту команду /start, после этого вы активируете Бота “Отца”.