Optuna. Подбор гиперпараметров для вашей модели
6 мин
Туториал

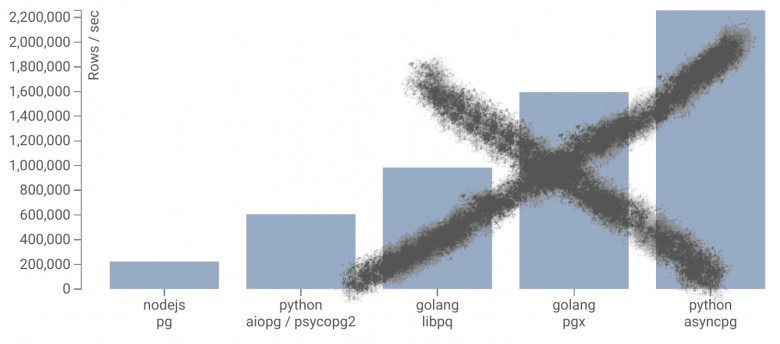
Optuna — это фреймворк для для автоматизированного поиска оптимальных гиперпараметров для моделей машинного обучения. Она подбирает оптимальные гиперпараметры методом проб и ошибок.
В данной статье представлен обзор фреймворка Optuna, рассмотрены ее основные возможности, базовые примеры использования.