

Читаем почту mail.ru из python при помощи imap

Подробно разбираем работу библиотек imaplib и email, открываем ящик и читаем письма (получаем из писем всё что есть) на примере mail.ru (хотя в целом, должно работать везде).
Рабочие задачи заставили обратиться к классике - электронной почте, материала довольно много в сети, но подробного развернутого изложения не хватило, делюсь результатами изысканий, кто не сталкивался ещё с этой задачей, надеюсь, будет полезно.
Как мы взяли бронзу вместо золота на Kaggle или умей верно выбрать сабмит

Привет, чемпион!
Мы тут недавно потратили месяц на соревнование «UW-Madison GI Tract Image Segmentation» и не взяли золото. Золотую медаль не взяли, но теперь у каждого из нас есть первая бронза. И сейчас мы кратко расскажем про сработавшие подходы в сегментации. А еще расскажем, что можно было сделать, чтоб все-таки забрать золото. (Спойлер: мы были в шаге от золота ...)
Фасад для python библиотеки

Для python существует множество различных библиотек, но часто бывает, что для конкретного проекта функционал какого-либо пакета - избыточен. В большинстве случаев необходимо вызывать лишь несколько постоянно повторяющихся методов, да и часть их аргументов не меняется от вызова к вызову.
В относительно простом приложении проблему константных аргументов можно решить при помощи functools.partial или вообще поместить повторяющийся код в отдельную функцию, но что, если даже в этом случае код со временем становится все более запутанным и сложным для читаемости?
На мой взгляд, неплохим выходом из ситуации служит использование объектно-ориентированного подхода, а именно написание некого класса "обвязки" с более простыми методами, инкапсулирующими в себе сложную логику обращения к оригинальной библиотеке.
Вот почему вам стоит использовать оператор Walrus в Python

Выражение присваивания (также известное как оператор walrus) — это функциональность, которая появилась в Python недавно, в версии 3.8. Однако применение walrus является предметом дискуссий и множество людей испытывают безосновательную неприязнь к нему.
Под катом эксперт компании IBM Мартин Хайнц*, разработчик и DevOps-инженер, постарается убедить вас в том, что оператор walrus — действительно хорошее дополнение языка. И его правильное использование поможет вам сделать код более лаконичным и читаемым.
*Обращаем ваше внимание, что позиция автора может не всегда совпадать с мнением МойОфис.
Обновления VS Code: Python, Markdown, настраиваемое свёртывание кода и многое другое
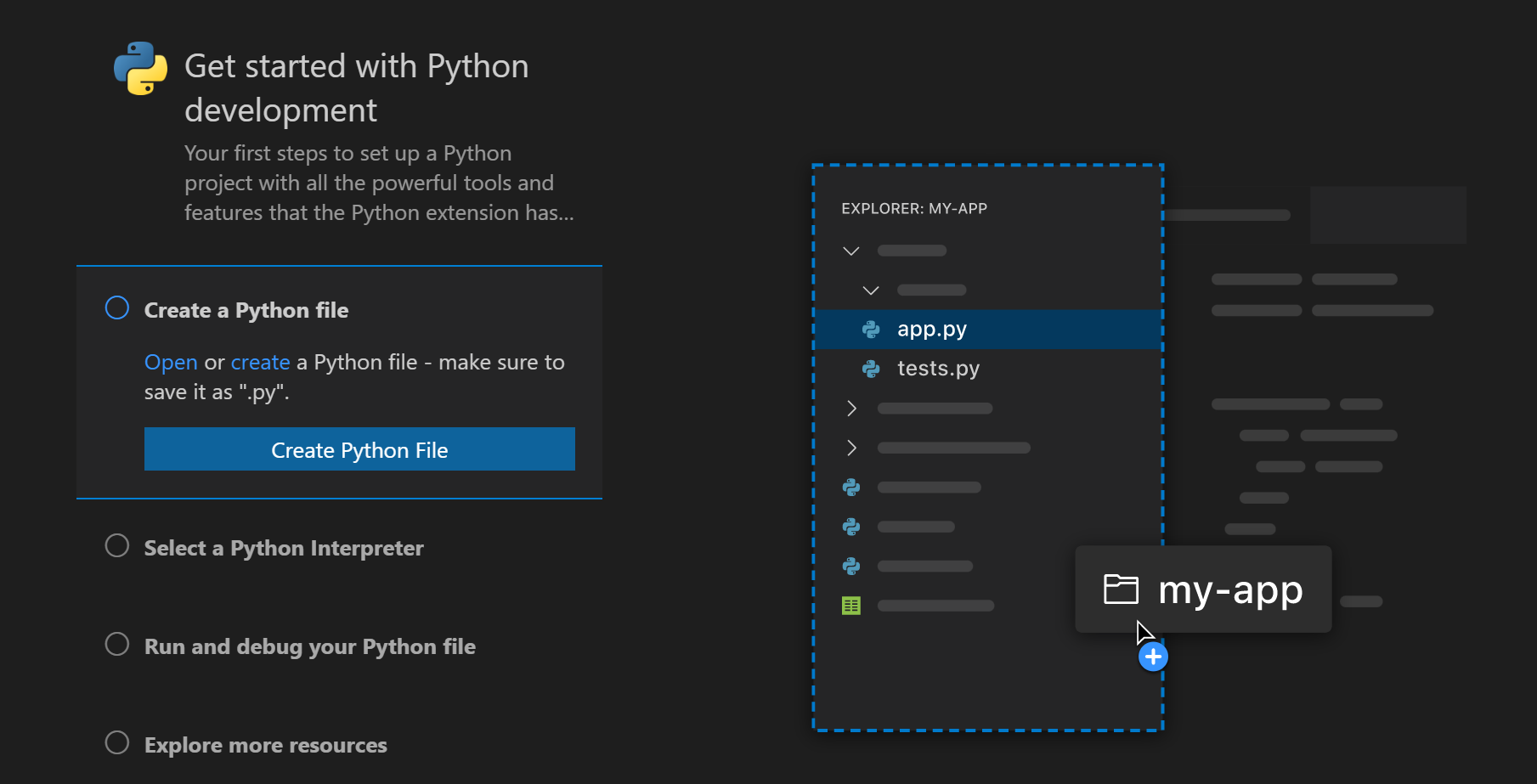
Работа с Python в VS Code 1.70 стала проще, точность определения конфликтов слияния Git — выше, а ещё появились доработки интеграции с интерактивными блокнотами Jupyter. К старту нашего флагманского курса по Data Science делимся подробностями.
Уроки компьютерного зрения. Оглавление

Уроки компьютерного зрения на Python + OpenCV с самых азов. Часть 1.
Уроки компьютерного зрения на Python + OpenCV с самых азов. Часть 2.
Уроки компьютерного зрения на Python + OpenCV с самых азов. Часть 3.
Уроки компьютерного зрения на Python + OpenCV с самых азов. Часть 4.
Уроки компьютерного зрения на Python + OpenCV с самых азов. Часть 5.
Уроки компьютерного зрения на Python + OpenCV с самых азов. Часть 6.
Уроки компьютерного зрения на Python + OpenCV с самых азов. Часть 7.
Уроки компьютерного зрения на Python + OpenCV с самых азов. Часть 8.
Создание IoT-приложения с использованием HTTP API

Уже несколько лет не снижается ажиотаж вокруг IoT-устройств. Эти устройства могут быть почти чем угодно: от будильника, показывающего погоду, до холодильника, сообщающего о ценах в ближайших продуктовых магазинах. Какой бы ни была реализация, для общения с источниками данных эти устройства используют API. Но как конкретно подключаются сообщения, данные и устройства?
В этом посте мы покажем пример проектирования и моделирования данных для IoT-устройства. Для этого будет использовано M5Stack — небольшое модульное IoT-устройство с экраном, и подключение к API Metropolitan Transportation Authority Нью-Йорка (MTA) для получения актуального графика движения поездов на разных станциях.
Пожалуйста, не используйте Python для инструментария

Разработчики любят спорить о языках программирования и инструментах. Если опустить типичные претензии, обычно все сводится к тому, что люди просто защищают свой выбор. Это проявление тенденции оправдывать и защищать свои инвестиции - время потраченное на изучение используемых языка и инструментов. И в этом есть смысл. Но не всегда это поведение является рациональным.
Фокусы оптимизации размера исполняемых файлов ELF. Поддержка 4 ОС в 400 байт единственного бинарника
В этом посте я расскажу о некоторых уловках, которыми я воспользовалась, чтобы уменьшить двоичные файлы С/С++/Python с помощью ассемблера для x86. Здесь всё крутится вокруг кодовой базы Cosmopolitan. Дело в том, что из недавнего отзыва по проекту ELKS я узнала, что мой код там всем понравился и они хотят узнать больше о том, что трюки cosmo могут дать проектам вроде «Linux-порта i8086». Я почувствовала, что мы с ребятами проекта ELKS «одной крови», ведь первое, что я написала при создании Cosmopolitan, — это загрузчик i8086, который назывался Actually Portable Executable. А ещё мне было приятно узнать, что людям, которые погрузились в эту проблему гораздо раньше меня, нравятся мои наработки в Cosmopolitan. И тогда я решила, что неплохо было бы поделиться ими с более широкой аудиторией.
![[Shinmyoumaru Sukuna]](https://habrastorage.org/webt/fz/j8/2s/fzj82s9csxx81rj8iyj7ph38l3q.png)
Обнаружение препятствий на OpenCV. Часть 2

С момента последней статьи прошел почти год. За это время произошло немало событий, времени на мое хобби с автономным катером нашлось откровенно мало. :/
Но идея создания алгоритма обнаружения абстрактных препятствий не давала мне покоя. Постоянно казалось, что до результата уже рукой подать.
Удобный print с номером строки и названием переменной
Допустим Вы что-то хотите распечатать в консоль.
hello = "world"
print(hello)
>>> world
Пока программа небольшая, то с этим нет никаких проблем.
Уроки компьютерного зрения на Python + OpenCV с самых азов. Часть 8

На прошлом уроке мы углубились в изучение контуров. В частности, научились работать со структурой, которую возвращает функция выделения контуров, научились аппроксимировать и обходить контур, научились программировать кое-какие геометрические операции, чтобы создать инвариантное описание объекта. Напомню, как это мы сделали: нашли контур объекта, аппроксимировали его, обошли этот контур, вычислили косинусы углов между гранями аппроксимированного контура.
Сегодня продолжим тему прошлого урока. Вычислим инвариантный вектор новым методом: через отношения длин сторон. Мы начнем обход так же с самой удаленной от центра точки, только будем брать стороны, а не углы межу сторонами. И первая сторона это та, что прилегает к первой точке. То есть она соединяет первую точку и следующую за ней по часовой стрелке. И все эти длины сторон мы разделим на самую длинную сторону. Хотя нет, сделам лучше. Сделаем минимакс нормализацию: вычтем из длины стороны минимум и разделим на разницу между минимумом и максимумом. У нас будет вектор чисел от 0 до 1.
И так, займемся кодингом. Сначала напишем цикл, создающий исходный масcив:
Ближайшие события
Celery: проясняем неочевидные моменты

Да, действительно, в этом посте не будет гайда, как поднять Celery в Django. Это статья для тех, кто уже пощупал Celery и хочет погрузиться в детали.
Мотивацией перевести эту статью были следующие вопросы, на которые я не знал ответа: при запуске создается процесс или поток? В какую очередь попадают отложенные задачи с ETA? А какие бывают очереди (спойлер: она не одна)? А в какой момент задача удаляется из очереди? Если я создам задачу с ETA=завтра_в_12:00, она ровно в этот момент и выполнится (спойлер: нет)?
Ответы на все эти вопросы в статье, велком!
Обработка естественного языка (NLP) методами машинного обучения в Python

В данной статье хотелось бы рассказать о том, как можно применить различные методы машинного обучения (ML) для обработки текста, чтобы можно было произвести его бинарную классифицию.
Рассмотрим задачу обработки естественного языка (NLP — Natural Lanuage Processing) на примере классификации психического здоровья для определения депрессии по комментариям в Reddit.
Подтесты в Python

Недавно я сделал опрометчивый твит, в котором намекнул на то, что у меня имеется глубоко продуманное мнение по одному важному вопросу. Я написал, что пакет pytest-subtests достоин того, чтобы им пользовалось бы больше программистов. Я даже дошёл до того, что, говоря о подтестах (subtests), сказал, что они были единственным, что мне по-настоящему нравилось в unittest до появления их поддержки в pytest. И, как на грех, Брайан Оккен предложил мне поучаствовать в подкасте Test and Code, чтобы подробнее обсудить подтесты. Я могу лишь догадываться о том, что он это сделал, дабы преподнести мне урок, показать мне, что я не должен, накачавшись продуктами Splenda и травяным чаем, выдавать скороспелые мнения о тестировании кода.Но, тем не менее, когда Брайан взглянет на меня со своей хитрой улыбкой и скажет: «Итак, ты готов поговорить о подтестах?», я планировал ответить: «Да, я готов — сделал обширные заметки и набрал справочных материалов». А когда мы вместе будем стоять на сцене, получая Дневную премию «Эмми» за лучший подкаст о тестировании, я шепну ему: «Я раскрыл твою хитрость, и хотя я тебя обыграл, ты реально показал мне — что такое скромность», а по его щеке скатится одинокая слеза.
Или, что скорее всего так и есть, ему просто хотелось пригласить кого-то, с кем можно поговорить об этом конкретном аспекте Python-тестирования, а я оказался одним из тех немногих, встретившихся ему, кто высказывал по этому поводу своё мнение. В любом случае, этот пост будет играть роль моих заметок по механизму подтестов из unittest, который появился в Python 3.4. Здесь же пойдёт речь о сильных и слабых сторонах подтестов, о сценариях их использования. Этот материал можно считать дополнением к подкасту Test and Code Episode 111.
Financial News Sentiment Dataset: определяем точку входа в акции по настроению новостей

Набор данных Financial News Sentiment Dataset (FiNeS) содержит в себе заголовки финансовых новостей о компаниях, торгующихся на Московской и СПб биржах. Целевой переменной датасета является оценка тональности новостных заголовков в виде вещественного числа. Идеи для использования датасета: Создание трейдинговых стратегий на основе анализа тональности новостей "на лету"; Анализ новостного фона в разрезе времени (день/неделя) или в разрезе компании.
Плагины, горячие клавиши, настройки для PyCharm

Пару лет назад, когда я впервые ставил PyCharm я пытался найти по нему гайды, статьи где рассказывалось бы о прикольных плагинах и горячих клавишах. Но таких стезей почти не находилось.
Поэтому я принял решение написать данную статью, она является сборником плагинов и хоткеев у многих разработчиков, которые часто ими пользуются.
Факторный анализ для интерпретации исследования клиентского опыта

Вы провели опрос клиентского опыта в вашей компании. В данном случае на каждый вопрос клиенты отвечали по 10 бальной шкале, где 1 - совсем неудовлетворен, а 10 - полностью удовлетворен. Вопросы разбиты на несколько тематических блоков. В начале блок основных вопросов:
Обзор метрик обнаружения аномалий (плюс много дополнительной информации)

Привет, Хабр! На связи снова Юрий Кацер, эксперт по ML и анализу данных в промышленности, а также руководитель направления предиктивной аналитики в компании «Цифрум» Госкорпорации “Росатом”.
До сих пор рамках рабочих обязанностей решаю задачи поиска аномалий, прогнозирования, определения остаточного ресурса и другие задачи машинного обучения в промышленности. В рамках рабочих задач мне приходится часто сталкиваться с проблемой правильной оценки качества решения задачи, и, в частности, выбора правильной data science метрики в задачах обнаружения аномалий.