Python за месяц
6 мин
Перевод
Руководство для абсолютных чайновичков.
(Прим. пер.: это советы от автора-индуса, но вроде дельные. Дополняйте в комментах.)

Месяц — это много времени. Если тратить на обучение по 6-7 часов каждый день, то можно сделать дофига.
Цель на месяц:
Так вы станете младшим разработчиком (джуном) Python.
Теперь план по неделям.
(Прим. пер.: это советы от автора-индуса, но вроде дельные. Дополняйте в комментах.)
Месяц — это много времени. Если тратить на обучение по 6-7 часов каждый день, то можно сделать дофига.
Цель на месяц:
- Ознакомиться с основными понятиями (переменная, условие, список, цикл, функция)
- Освоить на практике более 30 проблем программирования
- Собрать два проекта, чтобы применить на практике новые знания
- Ознакомиться хотя бы с двумя фреймворками
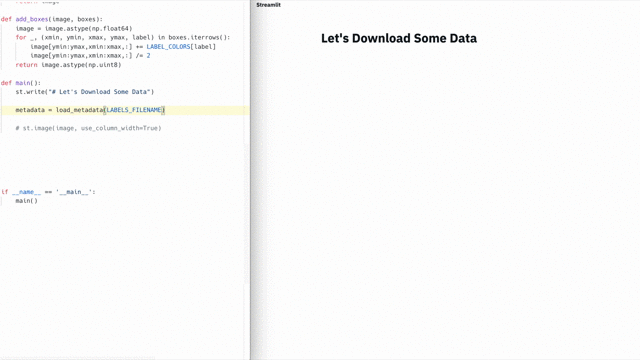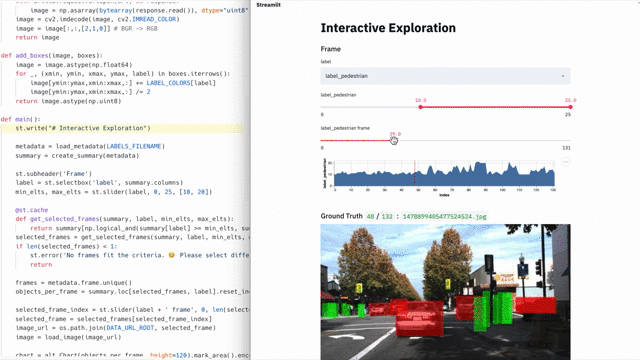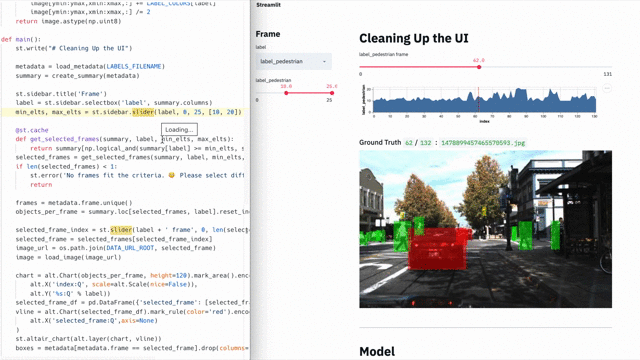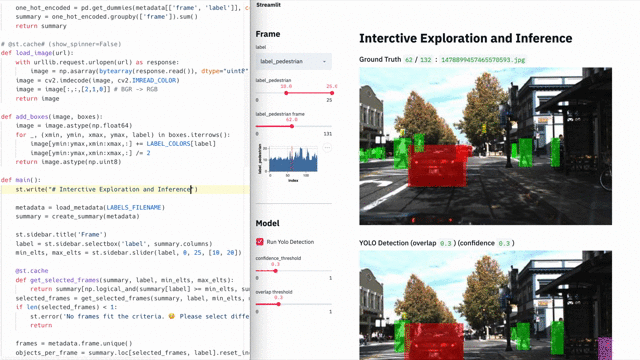
- Начать работу с IDE (средой разработки), Github, хостингом, сервисами и т. д.
Так вы станете младшим разработчиком (джуном) Python.
Теперь план по неделям.
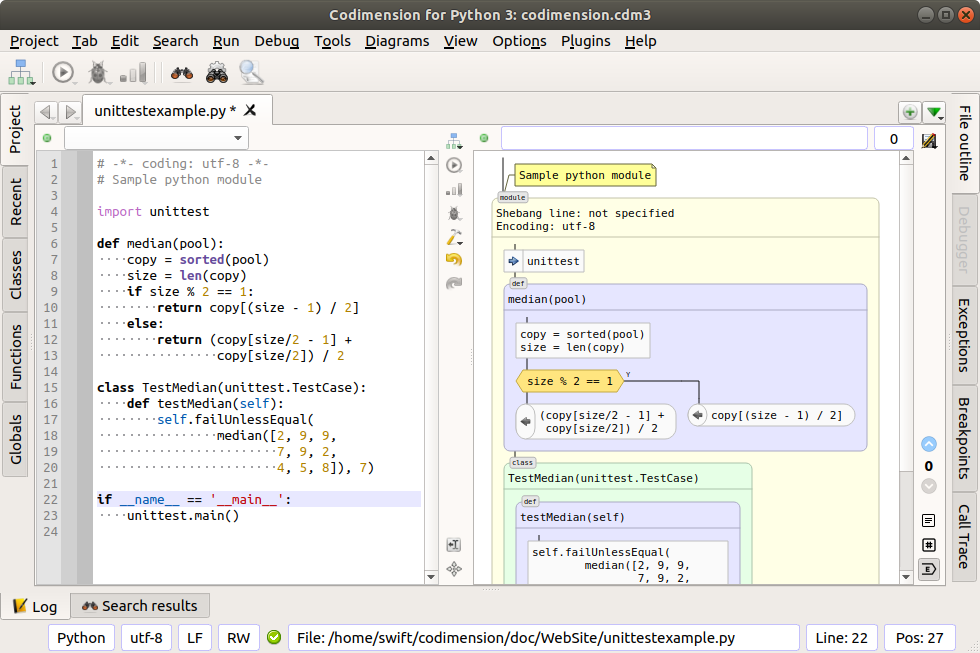

 Основной работой при создании утилиты
Основной работой при создании утилиты