ВСТУПЛЕНИЕ
В каком году — рассчитывай,
В какой земле — угадывай,
На столбовой дороженьке
Сошлись семь мужиков:
Семь временнообязанных,
Подтянутой губернии,
Уезда Терпигорева,
Пустопорожней волости,
Из смежных деревень:
Заплатова, Дырявина,
Разутова, Знобишина.
Горелова, Неелова —
Неурожайка тож,
Сошлися — и заспорили:
Кому живется весело,
Вольготно на Руси?
Н.Некрасов
Пару месяцев назад на одном IT мероприятии мне довелось лицезреть в работе Pandas. Парень, который с ним работал не делал ничего особенно удивительного. Но простые сложения значений, вычисления средних, группировки проиводились так виртуозно, что, даже при всей своей предвзятости к Питону, я был очарован. Манипуляции выполнялись на довольно приличных датасетах по данным капитального ремонта за период кажется с 2004 по 2019 год. Сотни тысяч строк, но все работало очень быстро.
В общем когда мне еще через пару месяцев пришлось кое-что анализировать, я решил попробовать сделать это с помощью Pandas. Провозился пару дней с тем, что с помощью Excel я бы смог сделать за день. Тем не менее мне удалось.
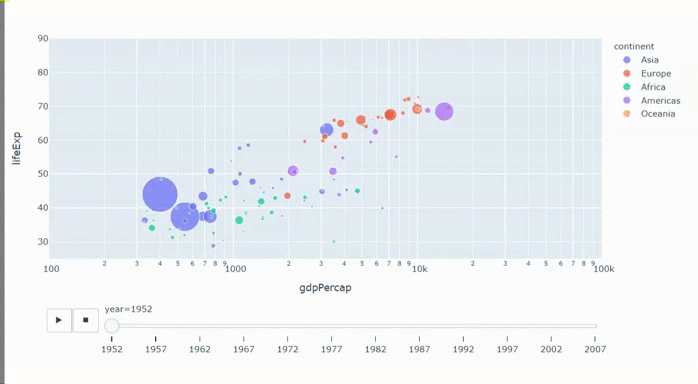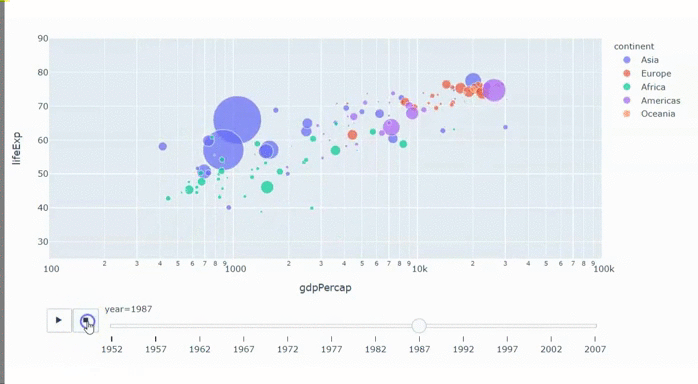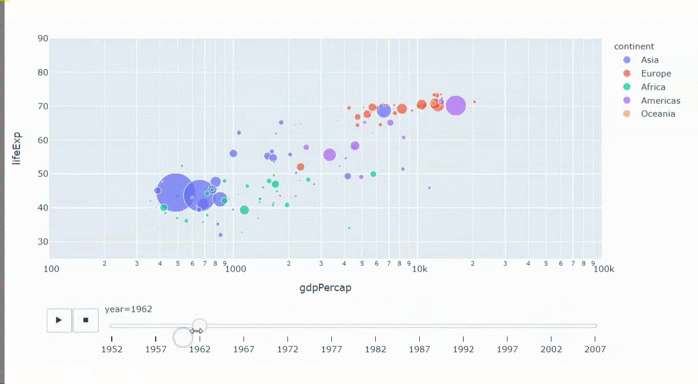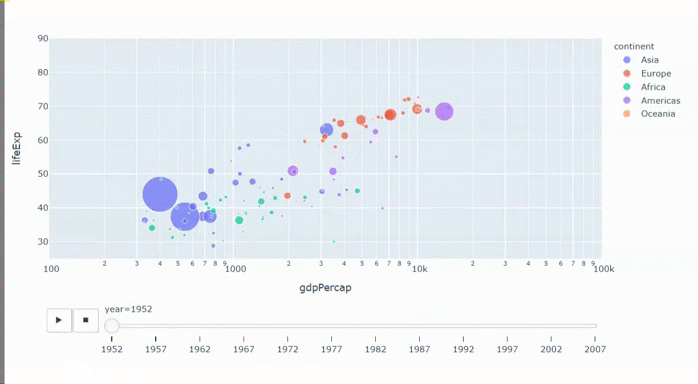
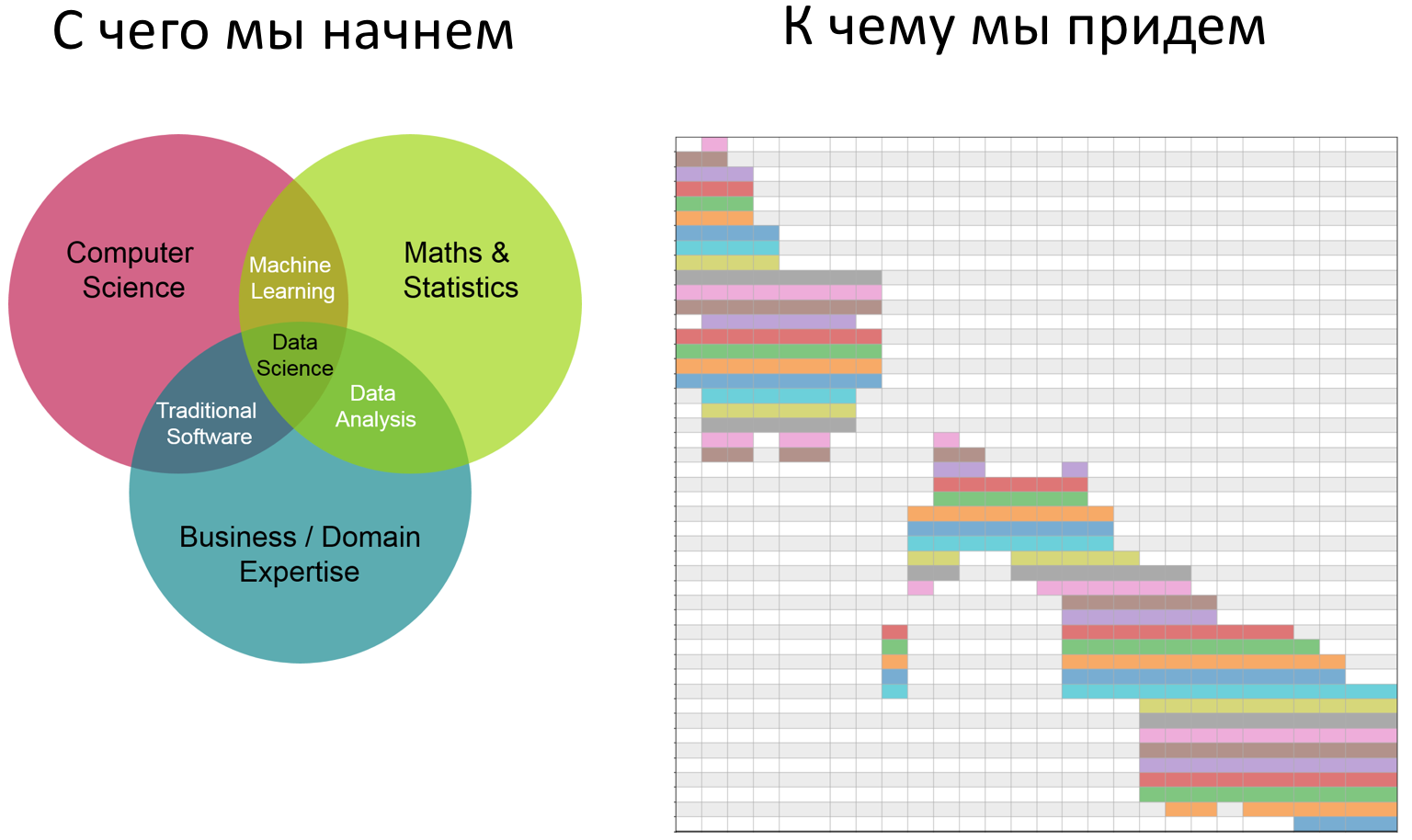
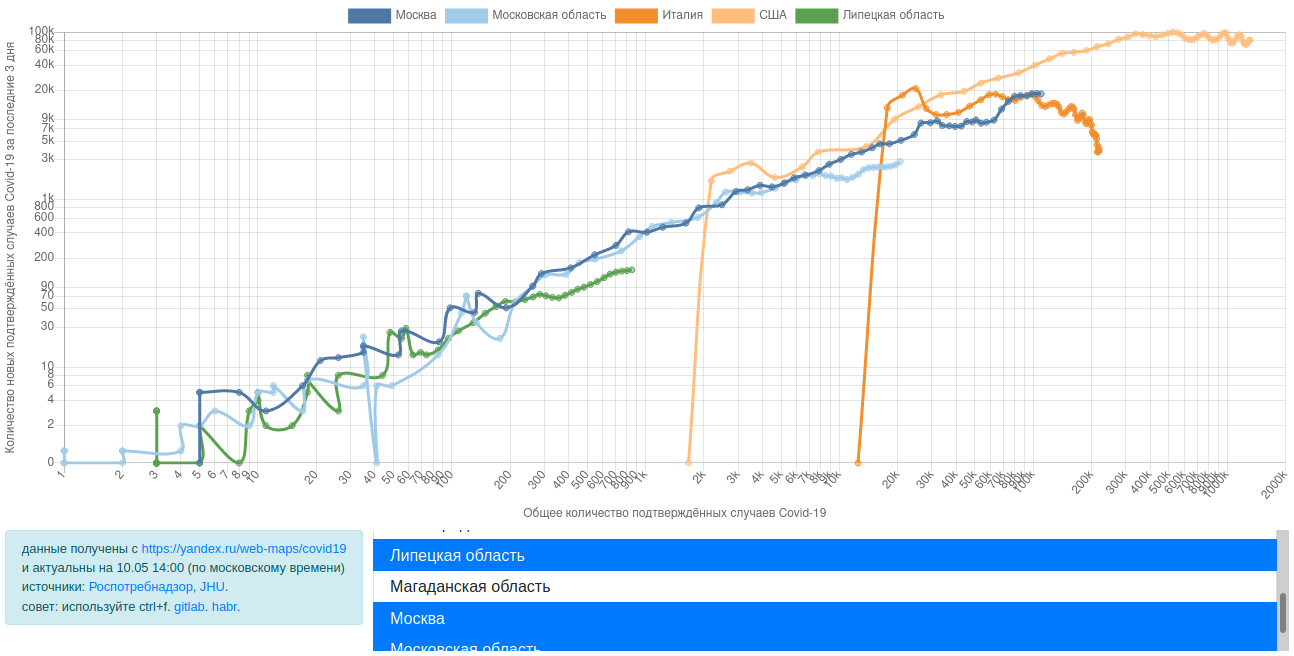
С апреля мы все сидим на карантине. Сидел я и думал, что бы мне такое сделать, чтобы не очень сложное и чтобы стильно и модно было. К тому времени я уже видел кучу всякой инфографики про коронавирус, про пожары в лесу, про выборы. Делать то, что уже делали не хотелось, да и браться сразу за сложное не решался, сомневаясь, что смогу закончить. Тут мне попалась какая-то статья про уже отшумевшее явление "barchart race" или по-русски "гонки столбчатых диаграмм". Вы можете подумать, что эта статья будет про barchart race. Да, но только отчасти. Barchart race будет только в конце, а статья скорее о том, как не обладая, какими-то выдающимися способностями и знаниями в области матана и прочей черной магии, можно сделать анализ больших данных и представить результат в доступной для широких масс форме. Итак, поехали.