

Писать SQL руками или использовать ORM — тема очень спорная, и я опишу, как использовать первый подход максимально эффективно. А какой из подходов выбрать, думаю, каждый сам для себя уже решил.
Писать SQL руками или использовать ORM — тема очень спорная, и я опишу, как использовать первый подход максимально эффективно. А какой из подходов выбрать, думаю, каждый сам для себя уже решил.




SQL — концептуально странный язык. Вы пишете ваше приложение на одном языке, скажем, на JavaScript, а затем направляете базе данных команды, написанные на совершенно другом языке — SQL. После этого база данных компилирует и оптимизирует эту команду на SQL, выполняет её и возвращает вам данные. Такой метод кажется ужасно неэффективным, но, всё-таки, ваше приложение может проделывать сотни таких операций в секунду. Просто безумие!
Но на самом деле всё ещё страннее.

За два года с момента релиза GPT-3 эту языковую модель использовали в множестве интересных задач — например, для сочинения поэзии, написания футурологических эссе и подготовки научных статей. Но как алгоритм обработки естественного языка может быть полезен программистам?
На этот вопрос в своей новой статье отвечает британский разработчик Саймон Уиллисон* — директор по архитектуре Eventbrite и один из создателей веб-фреймворка Django. Среди различных вариантов применения языковой модели GPT-3 Уиллисон особенно подчеркивает ее способность объяснять, что делает код. По словам специалиста, в этом GPT-3 поразительно эффективна, поскольку явно обучалась на огромном количестве исходного кода.
Под катом — наш перевод материала, в котором автор демонстрирует недавние примеры из своей практики: объяснение кода на Python, JavaScript, SQL, а также работу в рамках GPT-3 с математическими формулами.
*Обращаем ваше внимание, что позиция автора не всегда может совпадать с мнением МойОфис.

С момента первой же хабрапубликации о возможностях нашего сервиса визуализации планов запросов PostgreSQL explain.tensor.ru (а было это уже больше 2 лет назад) пользователи задавали резонный вопрос: "Все у вас круто, но у нас в запросах и планах есть коммерческая инфа, которую отправлять куда-то наружу низзя... Можно как-то ваш сервис развернуть на своей площадке?"
Ну, а почему бы и нет, подумали мы - тем более, некоторые пользователи уже интересовались возможностью интеграции нашего сервиса в свои системы.
В настоящее время тема миграции с СУБД Oracle на СУБД PostgreSQL (и разработанную на её основе СУБД Postgres Pro) является очень актуальной. В этой области у команды Postgres Professional накоплен многолетний опыт, которым мы решили поделиться. На основе наших материалов для внутреннего обучения мы подготовили серию статей для Хабра о миграции данных в PostgreSQL из «оракловой» базы.
Также на близкие темы можно посмотреть следующие доклады и мастер-классы.

Типовые таск-менеджеры отлично подходят для конкретных ситуаций, но чаще всего их не получится настроить под свои нужды. Джира медленная, дорогая и часто слишком сложная, trello слишком простой, а персональные таск менеджеры не дают нужного взаимодействия с командой.


SQL - декларативный язык - то есть вы описываете "что" хотите получить, а СУБД сама решает, "как" именно она будет это делать. Некоторые из них при этом позволяют им "подсказывать", как именно лучше выполнять запрос, но PostgreSQL - нет.
Тем не менее, "синтаксический сахар" некоторых языковых конструкций позволяет не только писать меньше кода (учите матчасть!), но и добиться, что ваша база будет делать часть вычислений "лениво", только при фактической необходимости.
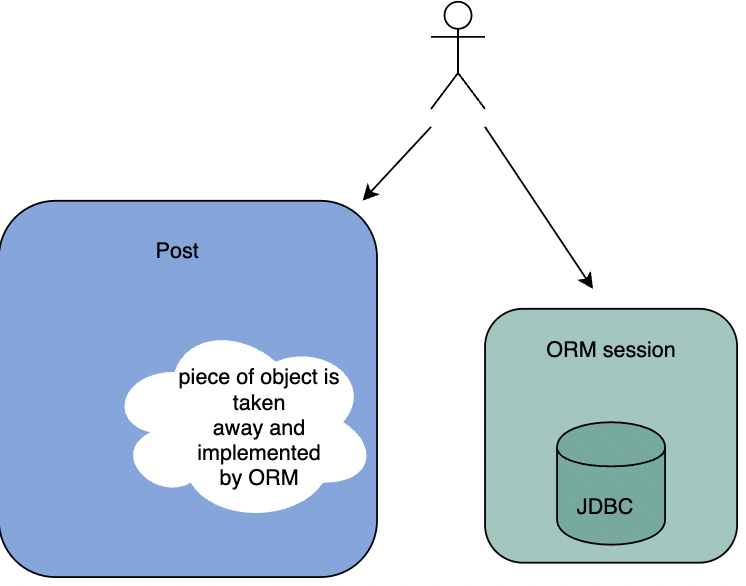
От автора перевода: Написанный далее текст может не совпадать с мнением автора перевода. Все высказывания идут от лица оригинального автора, просьба воздержаться от неоправданных минусов. Оригинальная статья выпущена в 2014 году, поэтому некоторые фрагменты кода могут быть устаревшими или "нежелаемыми".
Содержание статьи:
В статье приведены доводы, которые ставят под вопрос правильность присутствия ORM в рамках ООП.

Привет, Хабр! Меня зовут Георгий Лебедев, я работаю в команде разработки ядра Tarantool. В 2021 году мы впервые участвовали в Google Summer of Code (GSoC): одним из предложенных студентам проектов была миграция SQL с VDBE на JIT-платформу — с неё и начался мой путь в Tarantool.
Имея за плечами год учебных проектов по разработке различных компонент toolchain’а и вооружившись поддержкой менторов (Никиты Петтика, Тимура Сафина и Игоря Мункина), я взялся за этот проект. Создавая летом, фактически с нуля, платформу для JIT- компиляции SQL- запросов в Tarantool, я наступил на некоторые грабли и приобрёл, на мой взгляд, интересный опыт и знания, которыми хочу поделиться. Статья будет, в первую очередь, интересна тем, кто захочет дальше развивать этот проект, а также тем, кто рассматривает возможность внедрения JIT-компиляции в свой собственный SQL.

Видимо я сделала какое-то очень плохое зло, поэтому живу во время перемен. Справиться с эмоциями и повысить конкурентоспособность на рынке Data Enigneer’ов мне помогает сайт Hackerrank. На пути к решению вообще всех задач по SQL с этого сайта мне попалась задачка на нетривиальные запросы.
В задачке требовалось звёздочками нарисовать прямоугольный треугольник...

Помните, как вы были студентами, и готовились к экзаменам по ночам?
Предлагаю вашему вниманию простую шпаргалку по SQL с теорией и практикой, которой вы сможете воспользоваться в любое время.
Изучите теорию на примерах и закрепите на 13 практических задачах по SQL.

Привет всем!
Сразу хочется отметить, что данная статья написана исключительно для людей, начинающих свое путь в изучении SQL и оконных функций. Здесь могут быть не разобраны сложные применения функций и могут не использоваться сложные формулировки определений - все написано максимально простым языком для базового понимания.
P.S. Если автор что-то не разобрал и не написал, значит он посчитал это не обязательным в рамках этой статьи)))
Для примеров будем использовать небольшую таблицу, которая показывает оценки учеников по разным предметам. В БД табличка выглядит следующим образом

Вчера Hubert 'depesz' Lubaczewski закрыл доступ с российских IP ко всем своим сайтам, включая широко известный визуализатор планов PostgreSQL-запросов explain.depesz.com.
Но это не беда, потому что в компании "Тензор" мы разработали сервис explain.tensor.ru, функционал которого гораздо обширнее, и которым можете воспользоваться и вы.

Сегодня SQL используют уже буквально все на свете: и аналитики, и программисты, и тестировщики, и т.д. Отчасти это связано с тем, что базовые возможности этого языка легко освоить.
Однако работая с большим количеством junior-ов, мы раз от раза находим в их решениях одни и те же ошибки. Реально — иногда просто создается ощущение, что они копируют друг у друга код.
Кстати, иногда такая же участь постигает и специалистов более высокого полета.
Сегодня мы решили собрать 7 таких ошибок в одном месте, чтобы как можно меньше людей их совершали.
Росстат ежегодно публикует порядка 4 тысяч показателей государственной статистики. Они доступны всем без каких-либо ограничений по статусу, правам доступа и т.п. Но публикуя данные, Росстат прежде всего ориентируется на то, что пользователи будут работать с ними вручную (глазами и руками), хотя последние 20 лет, мягко говоря, это не совсем тренд.
Меня зовут Веденьков Максим, я работаю в ЦПУР (Центр перспективных управленческих решений), некоммерческой организации, которая проводит исследования на государственных данных с целью повышения информированности общества о происходящих в стране процессах. Также мы собираем, обогащаем и публикуем датасеты с государственными данными, как ранее опубликованными, так и теми, которые раньше не публиковались.
В этой статье хочу рассказать об одном из таких наборов данных. Большом, сложном, важном, но при этом доступном в крайне неудобном для исследователей формате — базе данных показателей муниципальных образований (БД ПМО).

Развитие происходит по спирали: когда-то люди не умели правильно индексировать, потом (в основном) научились, потом пришли noSQL и все снова забыли знание древних. Что вы будете делать, когда последние из старых DBA отплывут в Валинор?
Снова и снова и сталкиваюсь с полным набором антипаттернов индексирования. Я их перечислю, но! Для каждого антипаттерна есть исключение, когда именно это и стоит делать. Поэтому кликбейтно сформулированное правило верно в 95% случаях, но если вы хотите копнуть глубже, то прочитайте про исключения.
И в конце полезные скрипты для MSSQL, Postgres и MySQL.