Предисловие
В ходе разработки ios-приложения, перед разработчиком может встать задача unit-тестирования кода. Именно с такой задачей столкнулся я.

Пользователь
В ходе разработки ios-приложения, перед разработчиком может встать задача unit-тестирования кода. Именно с такой задачей столкнулся я.
Как часто нам, iOS разработчикам, приходится собирать приложение для загрузки в iTunes Connect App Store Connect? В процессе этапа активного бета-тестирования приложения нужно оперативно фиксить баги и поставлять обновленную сборку для тестирования. А также необходимо скачивать сертификаты, Provision profiles, прокликивать много разных галочек и кнопочек при каждой выкладке нового билда.
К счастью, есть такой замечательный инструмент, как fastlane, который помогает нам автоматизировать ручные действия мобильного разработчика.
В этом посте я расскажу: что такое fastlane и как быстро начать его использовать в своих iOS проектах.




С каждым годом курсовые для моих студентов становятся все объемнее. Например, в этом году одним из заданий была разработка метеостанции, ведь только ленивый не делает метеостанции, а студенты они по определению не ленивые, поэтому должны её сделать. Её можно быстро накидать в Cube или собрать на Ардуино, но задача курсового не в этом. Основная задача — самостоятельно, с нуля разобраться с модулями микроконтроллера, продумать архитектуру ПО и, собственно, закодировать все на С++, начиная от регистров и заканчивая задачами РТОС. Кому интересно, здесь пример отчета по такому курсовому
Так вот, появилась небольшая проблема, а именно, бесплатный IAR позволяет делать ПО размером не более 30 кБайт. А это уже впритык к размеру курсового в неоптимизированном виде. Анализ кода студентов выявил, что примерно 1/4 часть их приложения занимает FreeRtos — около 6 кБайт, хотя для того, чтобы сделать вытесняющую переключалку и управлялку задачами хватило бы, наверное… да байт 500 причем вместе с 3 задачами (светодиодными моргунчиками).
Эта статья будет посвящена тому, как можно реализовать Очень Простой Планировщик(он же SST), описанный в статье аж 2006 года и сейчас поддерживаемый Quantum Leaps в продукте Qp framework.
С помощью этого ядра очень просто реализовать конечный автомат, и оно очень хорошо может использоваться в небольших проектах студентами (и не только), которые могут получить дополнительно 5 кБайт в свое распоряжение.
Я попробую показать как можно реализовать такой планировщик самому. Чтобы не сильно перегружать статью, рассмотрю переключение контекста на CortexM0 у которого нет аппаратного модуля с плавающей точкой.
Все кто заинтересовался и хочет понять как можно переключать контекст, добро пожаловать под кат.


Привет, Хабр! Продолжаем публиковать рецензии на научные статьи от членов сообщества Open Data Science из канала #article_essense. Хотите получать их раньше всех — вступайте в сообщество!
Статьи на сегодня:
SELECT, FROM и WHERE. Чем больше SQL-конструкций знает специалист — тем легче ему будет создавать запросы на получение из баз данных всего, что ему может понадобиться.


Общеизвестно, что семантика инициализации — одна из наиболее сложных частей C++. Существует множество видов инициализации, описываемых разным синтаксисом, и все они взаимодействуют сложным и вызывающим вопросы способом. C++11 принес концепцию «универсальной инициализации». К сожалению, она привнесла еще более сложные правила, и в свою очередь, их перекрыли в C++14, C++17 и снова поменяют в C++20.
Под катом — видео и перевод доклада Тимура Домлера (Timur Doumler) с конференции C++ Russia. Тимур вначале подводит исторические итоги эволюции инициализации в С++, дает системный обзор текущего варианта правила инициализации, типичных проблем и сюрпризов, объясняет, как использовать все эти правила эффективно, и, наконец, рассказывает о свежих предложениях в стандарт, которые могут сделать семантику инициализации C++20 немного более удобной. Далее повествование — от его лица.
TEST_CLASS(EvaluatorTests) {
public:
TEST_METHOD(Should_return_zero_when_evaluate_empty_list) {
double result = Evaluator::Evaluate({});
Assert::AreEqual(0.0, result);
}
};
TEST_CLASS(ParserTests) {
public:
TEST_METHOD(Should_return_empty_list_when_put_empty_list) {
Tokens tokens = Parser::Parse({});
Assert::IsTrue(tokens.empty());
}
};
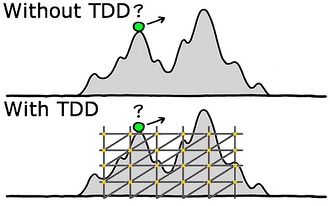
popen и вычислить выражение через него. Целью данной статье является пошаговая разработка достаточно сложной системы с помощью TDD, поэтому будет использоваться только стандартная библиотека C++ и встроенный в IDE тестовый фреймворк.