Вы заметили, что Фейсбук обрёл сверхъестественную способность распознавать ваших друзей на ваших фотографиях? В старые времена Фейсбук отмечал ваших друзей на фотографиях лишь после того, как вы щёлкали соответствующее изображение и вводили через клавиатуру имя вашего друга. Сейчас после вашей загрузки фотографии Фейсбук отмечает любого для вас, что похоже на волшебство:

Дмитрий @Dreamastiy
Пользователь
Инфекционное распространение рекламы в социальных сетях
6 мин
Очевидно, что факт развития социальных сетей нивелирует расстояние между агентами, а также увеличивает вероятность случайного возникновения связи между двумя агентами – таким образом, заразить агентов информацией все проще и проще. А значит, актуальным становится вопрос способности предсказать, как именно распространится инфекция.
И хотя изначально потребность предсказания распространения инфекций в сетях возникла в биологии, данная проблема присутствует в том числе и в экономике. Ведь если, скажем, компания хочет распространить какую-то новинку через социальную сеть (данный способ диффузии информации является одним из самых популярных с момента начала активного развития социальных сетей), то ей нужно понимать, как будет идти инфекция по сети со временем, чтобы правильно выбрать амбассадоров для минимальных затрат на распространение информации о товаре. Таким образом, сетевое предсказательное моделирование оказывается востребованным и применительно к сетям экономических агентов.
Далее я покажу практическое применение моделей распространение инфекции на примере сети Flickr. Для этого будут реализованы две самые популярные и применимые на практике модели – SI (suspectible – infected) и SIR (suspectible – infected – recovered) [1], [5].
И хотя изначально потребность предсказания распространения инфекций в сетях возникла в биологии, данная проблема присутствует в том числе и в экономике. Ведь если, скажем, компания хочет распространить какую-то новинку через социальную сеть (данный способ диффузии информации является одним из самых популярных с момента начала активного развития социальных сетей), то ей нужно понимать, как будет идти инфекция по сети со временем, чтобы правильно выбрать амбассадоров для минимальных затрат на распространение информации о товаре. Таким образом, сетевое предсказательное моделирование оказывается востребованным и применительно к сетям экономических агентов.
Далее я покажу практическое применение моделей распространение инфекции на примере сети Flickr. Для этого будут реализованы две самые популярные и применимые на практике модели – SI (suspectible – infected) и SIR (suspectible – infected – recovered) [1], [5].
D3.js. Визуализация графов
13 мин
Туториал
D3.js — это библиотека JavaScript для управления документами, в основе которых лежат данные. D3 помогает претворить данные в жизнь, используя HTML, SVG и CSS. D3 позволяет привязывать произвольные данные к DOM, и затем применять результаты манипуляций с ними к документу.
Для понимания статьи пригодится знание основ D3, и в ней мы рассмотрим реализацию алгоритмов визуализации графа на основе сил (Force-directed graph drawing algorithms), которая в D3 (version 3) имеет название Force Layout. Это класс алгоритмов визуализации графов, которые вычисляют позицию каждого узла, моделируя силу притяжения между каждой парой связанных узлов, а также отталкивающую силу между узлами.

Методические заметки об отборе информативных признаков (feature selection)
39 мин
Туториал
Всем привет!
Меня зовут Алексей Бурнаков. Я Data Scientist в компании Align Technology. В этом материале я расскажу вам о подходах к feature selection, которые мы практикуем в ходе экспериментов по анализу данных.
В нашей компании статистики и инженеры machine learning анализируют большие объемы клинической информации, связанные с лечением пациентов. В двух словах смысл этой статьи можно свести к извлечению ценных крупиц знания, содержащихся в небольшой доле доступных нам зашумленных и избыточных гигабайтов данных.
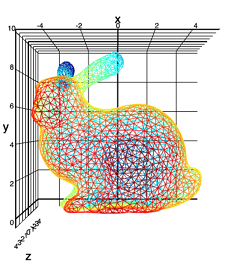
Источник.
Меня зовут Алексей Бурнаков. Я Data Scientist в компании Align Technology. В этом материале я расскажу вам о подходах к feature selection, которые мы практикуем в ходе экспериментов по анализу данных.
В нашей компании статистики и инженеры machine learning анализируют большие объемы клинической информации, связанные с лечением пациентов. В двух словах смысл этой статьи можно свести к извлечению ценных крупиц знания, содержащихся в небольшой доле доступных нам зашумленных и избыточных гигабайтов данных.
Данная статья предназначена для статистиков, инженеров машинного обучения и специалистов, которые интересуются вопросами обнаружения зависимостей в наборах данных. Также материал, изложенный в статье, может быть интересен широкому кругу читателей, неравнодушных к data mining. В материале не будут затронуты вопросы feature engineering и, в частности, применения таких методов как анализ главных компонент.
Источник.
Профилирование в R
4 мин
Перевод
В R есть встроенная утилита для профилирования производительности и памяти — Rprof. Наберите в консоли
Профайлер работает так:
?Rprof, чтобы узнать о ней больше.Профайлер работает так:
- запускаете профайлер, вызывая Rprof и передавая имя файла, где будут храниться данные профилирования
- вызываете функции R, которые хотите проанализировать
- вызываете
Rprof(NULL), чтобы остановить профайлер - анализируете файл, созданный Rprof, как правило, с помощью
summaryRprof
Twitter купил нейросеть Magic Pony для повышения резкости изображений и видео
3 мин
150 миллионов долларов за «очевидную технологию»

Буквально пару месяцев назад на Geektimes рассказывали о малоизвестном английском стартапе Magic Pony Technology, который основал инженер Роб Бишоп — один из создателей мини-компьютера Raspberry Pi.
Стартап разработал революционную технологию моделирования изображений, которая значительно повышает разрешение фотографий и видео в реальном времени. Обученная нейросеть не просто интерполирует пиксели, а добавляет недостающие детали. Разработчики говорили, что так можно автоматически генерировать элементы, например, для реалистичных виртуальных миров.
В комментариях на GT согласились, что «этот способ вполне очевидный, и его патент — это почти патентный троллинг». Более того, пользователь Sadler сообщил, что два года назад он уже реализовал такую технологию на автоэнкодерах (пример работы нейросети, обученной Sadler).
Работа мечты и бесплатный кластер на 1 миллион мета-данных
4 мин
Доброго времени суток!
Мы решили дать публичный доступ к архиву 1 млн насыщенных мета-данными сообщений соцмедиа (несколько сотен источников, включая посты и комментарии соцсетей, блогов, форумов, СМИ и т.п.).
Предлагаем попробовать свои силы в создании различных эвристик, закладываемых в классические SMA-системы (Social Media Analytics). Чем больше эвристик вы придумаете и сможете реализовать, тем выше ваш класс в Data Scientist. Возможно в вас живет настоящий профи: Data Scientist — одна из крутых профессий ближайшего будущего!
Для состоявшихся фанатов-профи — это возможность проверить и показать свои способности, а также, при обоюдном желании и радости, получить годовой контракт на $30.000 — $50.000.
Подробнее под катом
Мы решили дать публичный доступ к архиву 1 млн насыщенных мета-данными сообщений соцмедиа (несколько сотен источников, включая посты и комментарии соцсетей, блогов, форумов, СМИ и т.п.).
Предлагаем попробовать свои силы в создании различных эвристик, закладываемых в классические SMA-системы (Social Media Analytics). Чем больше эвристик вы придумаете и сможете реализовать, тем выше ваш класс в Data Scientist. Возможно в вас живет настоящий профи: Data Scientist — одна из крутых профессий ближайшего будущего!
Для состоявшихся фанатов-профи — это возможность проверить и показать свои способности, а также, при обоюдном желании и радости, получить годовой контракт на $30.000 — $50.000.
Подробнее под катом
Метрики качества ранжирования
7 мин
Туториал
В процессе подготовки задачи для вступительного испытания на летнюю школу GoTo, мы обнаружили, что на русском языке практически отсутствует качественное описание основных метрик ранжирования (задача касалась частного случая задачи ранжирования — построения рекомендательного алгоритма). Мы в E-Contenta активно используем различные метрики ранжирования, поэтому решили исправить это недоразуменее, написав эту статью.

Играть на уровне бога: как ИИ научился побеждать человека
27 мин

В 16 играх машины одолели человека (в 17, если брать в расчет поражение Ли Седоля в го), но в будущем их ждут еще более впечатляющие достижения: решение самых ошеломляющих математических, физиологических и биологических проблем, победа над болезнями и старостью, ликвидация дорожных аварий, триумф в военных конфликтах и многое другое.
Мир изменился прямо на наших глазах, но не все заметили это. Когда и как программы научились играть безошибочно? Всегда ли проигрыш одного человека свидетельствует о поражении всего человечества? Обретет ли искусственный интеллект сознание?
Об авторе. Статья основана на лекции «Искусственный интеллект. История и перспективы», проведенной в московском офисе Mail.Ru Group Сергеем oulenspiegel Марковым. Сергей Марков занимается machine learning в «Сбербанке». В банковской сфере строят предиктивные модели для управления бизнес-процессом на основе достаточно больших обучающих выборок, которые могут включать несколько сотен миллионов кейсов. Среди своих хобби Сергей указывает шахматное программирование, ИИ для игр, минимаксные задачи. Программа SmarThink, созданная Сергеем Марковым, становилась чемпионом России (2004) и СНГ (2005) среди шахматных программ (2004), и сегодня входит в топ-30 сильнейших программ в мире. Также Сергей является основателем некоммерческого научно-просветительского портала 22 век.
Подборка: 50+ материалов для понимания фондового рынка
3 мин
Recovery Mode

Торговля на бирже — источник дохода для многих фондов и онлайн-трейдеров. Однако начать зарабатывать на рынке ценных бумаг не так-то просто, ведь не каждый начинающий трейдер или неопытный инвестор сможет самостоятельно разобраться в его сложной структуре (к чему это приводит мы писали здесь). Мы предлагаем вашему вниманию 53 полезных материалов о торговых и финансовых инструментах, биржах и их сленге, которые сделают особенности фондового рынка более понятными для новичка.
«Нам плевать на ваши визитки и стильные сайты...» — Действия, которые не влияют на деньги в кассе
6 мин
Recovery Mode
Красивые визитки, брендированные конверты, красочные буклеты и прочие действия, которые отнимают время и не влияют на деньги в кассе. Типичные ошибки стартапов от идеи до первых продаж. Как не спутать важные действия и второстепенные?

Смотря на другие проекты и анализируя свои, захотелось собрать в одну кучу все типичные мысли и ошибки людей, у которых возникла «гениальная» идея по бизнесу. Не важно в какой отрасли, каждый стартап проходит через одинаковые точки развития. Главная проблема в том, чтобы уметь отличать важные действия от второстепенных. Можно сутками сидеть в офисе, поднимать пыль в воздух, решая ненужные задачи, а можно за 1 день сделать недельный результат.
Итак, вот те самые мысли и действия, которые кажутся такими важными, но которые так мало значат в реальности:
Смотря на другие проекты и анализируя свои, захотелось собрать в одну кучу все типичные мысли и ошибки людей, у которых возникла «гениальная» идея по бизнесу. Не важно в какой отрасли, каждый стартап проходит через одинаковые точки развития. Главная проблема в том, чтобы уметь отличать важные действия от второстепенных. Можно сутками сидеть в офисе, поднимать пыль в воздух, решая ненужные задачи, а можно за 1 день сделать недельный результат.
Итак, вот те самые мысли и действия, которые кажутся такими важными, но которые так мало значат в реальности:
Подводные камни A/Б-тестирования или почему 99% ваших сплит-тестов проводятся неверно?
8 мин

«Горячая» и часто обсуждаемая сегодня тема оптимизации конверсии привела к безусловной популяризации А/Б-тестирования, как единственного объективного способа узнать правду о работоспособности тех или иных технологий/решений, связанных с увеличением экономической эффективности для онлайн-бизнеса.
За этой популярностью скрывается практически полное отсутствие культуры в организации, проведении и анализе результатов экспериментов. В Retail Rocket мы накопили большую экспертизу в оценке экономической эффективности от систем персонализации в электронной коммерции. За два года был отстроен идеальный процесс проведения A/Б-тестов, которым мы и хотим поделиться в рамках этой статьи.
Лучшие пакеты для работы с данными в R, часть 2
5 мин
Перевод
Есть два отличных пакета для работы с данными в R —
Здесь можно найти руководство и краткое описание
В первой части: начало работы с данными, выбор, удаление и переименование столбцов.
dplyr и data.table. У каждого пакета свои сильные стороны. dplyr элегантнее и похож на естественный язык, в то время как data.table лаконичный, с его помощью многое можно сделать всего в одну строку. Более того, в некоторых случаях data.table быстрее (сравнительный анализ доступен здесь), и это может определить выбор, если есть ограничения по памяти или производительности. Сравнение dplyr и data.table можно также почитать на Stack Overflow и Quora.Здесь можно найти руководство и краткое описание
data.table, а здесь — для dplyr. Также можно почитать обучающие материалы по dplyr на DataScience+.В первой части: начало работы с данными, выбор, удаление и переименование столбцов.
Пишем свой канал-бот для Telegram как у Хабра на Python
5 мин
Недавно ко мне обратился друг с просьбой написать бота, импортирующего новости из RSS-канала на сайте в Telegram-канал. Огромнейшим плюсом данного способа оповещения являются push-уведомления, которые приходят каждому подписанному пользователю на его устройство. Уже давно хотелось заняться чем-то подобным. Недолго думая, в качестве образца я выбрал канал Хабра telegram.me/habr_ru. В качестве языка программирования был выбран Python.
Внезапный диван леопардовой расцветки
8 мин
Если вы интересуетесь искусственным интеллектом и прочим распознаванием, то наверняка уже видели эту картинку:

А если не видели, то это результаты Хинтона и Крижевского по классификации ImageNet-2010 глубокой сверточной сетью
Давайте взглянем на ее правый угол, где алгоритм опознал леопарда с достаточной уверенностью, разместив с большим отрывом на втором и третьем месте ягуара и гепарда.
Это вообще довольно любопытный результат, если задуматься. Потому что… скажем, вы знаете, как отличить одного большого пятнистого котика от другого большого пятнистого котика? Я, например, нет. Наверняка есть какие-то зоологические, достаточно тонкие различия, типа общей стройности/массивности и пропорций тела, но мы же все-таки говорим о компьютерном алгоритме, которые до сих пор допускают какие-то вот такие достаточно глупые с человеческой точки зрения ошибки. Как он это делает, черт возьми? Может, тут что-то связанное с контекстом и фоном (леопарда вероятнее обнаружить на дереве или в кустах, а гепарда в саванне)? В общем, когда я впервые задумался над конкретно этим результатом, мне показалось, что это очень круто и мощно, разумные машины где-то за углом и поджидают нас, да здравствует deep learning и все такое.
Так вот, на самом деле все совершенно не так.
А если не видели, то это результаты Хинтона и Крижевского по классификации ImageNet-2010 глубокой сверточной сетью
Давайте взглянем на ее правый угол, где алгоритм опознал леопарда с достаточной уверенностью, разместив с большим отрывом на втором и третьем месте ягуара и гепарда.
Это вообще довольно любопытный результат, если задуматься. Потому что… скажем, вы знаете, как отличить одного большого пятнистого котика от другого большого пятнистого котика? Я, например, нет. Наверняка есть какие-то зоологические, достаточно тонкие различия, типа общей стройности/массивности и пропорций тела, но мы же все-таки говорим о компьютерном алгоритме, которые до сих пор допускают какие-то вот такие достаточно глупые с человеческой точки зрения ошибки. Как он это делает, черт возьми? Может, тут что-то связанное с контекстом и фоном (леопарда вероятнее обнаружить на дереве или в кустах, а гепарда в саванне)? В общем, когда я впервые задумался над конкретно этим результатом, мне показалось, что это очень круто и мощно, разумные машины где-то за углом и поджидают нас, да здравствует deep learning и все такое.
{kind=link}
Так вот, на самом деле все совершенно не так.
Лучшие пакеты для работы с данными в R, часть 1
6 мин
Перевод
Есть два отличных пакета для работы с данными в R —
Здесь можно найти руководство и краткое описание
dplyr и data.table. У каждого пакета свои сильные стороны. dplyr элегантнее и похож на естественный язык, в то время как data.table лаконичный, с его помощью многое можно сделать всего в одну строку. Более того, в некоторых случаях data.table быстрее (сравнительный анализ доступен здесь), и это может определить выбор, если есть ограничения по памяти или производительности. Сравнение dplyr и data.table можно также почитать на Stack Overflow и Quora.Здесь можно найти руководство и краткое описание
data.table, а здесь — для dplyr. Также можно почитать обучающие материалы по dplyr на DataScience+.Не мы такие — жизнь такая: Тематический анализ для самых нетерпеливых
13 мин

Почему?
Сейчас Relap.io генерирует 40 миллиардов рекомендаций в месяц на 2000 медиаплощадках Рунета. Почти любая рекомендательная система, рано или поздно, приходит к необходимости брать в расчет содержимое рекомендуемого контента, и довольно быстро упирается в необходимость как-то его классифицировать: найти какие-то кластеры или хотя бы понизить размерность для описания интересов пользователей, привлечения рекламодателей или еще для каких-то темных или не очень целей.
Задача звучит довольно очевидно и существует немало хорошо зарекомендовавших себя алгоритмов и их реализаций: Латентное размещение Дирихле (LDA), Вероятностный латентно-семантический анализ (pLSA), явный семантический анализ (ESA), список можно продолжить. Однако, мы решили попробовать придумать что-нибудь более простое, но вместе с тем, жизнеспособное.
Обработка данных в iPython notebook для задач SEO
6 мин

При выполнении аналитических задач SEO, SMM, маркетинга мы столкнулись с непомерно растущим количеством инструментов для обработки данных. Каждый заточен под свои возможности или доступность для пользователя: Excel и VBA, сторонние SEO-инструменты, PHP и MySQL, Python, C, Hive и другие. Разнообразные системы и источники данных добавляют проблем: счетчики, рекламные системы, CRM, инструменты вебмастера Яндекса и Google, соцсети, HDFS. Необходим инструмент, совмещающий в себе простоту настройки и использования, модули для получения, обработки и визуализации данных, а также работы с различными типами источников. Выбор пал на iPython notebook (с недавних пор Jupyter notebook), представляющий собой платформу для работы со скриптами на 40 языках программирования. Широкое распространение платформа получила для научных вычислений, среди специалистов по обработке данных и машинному обучению. К сожалению для автоматизации и обработки данных маркетинговых задач Jupyter notebook используется крайне редко.
Дайджест Университета ИТМО: #3 Нейронные сети: интересные статьи из журналов Университета ИТМО
3 мин

Сегодня в дайджесте (первый выпуск и второй выпуск) вас ждет подборка научных статьей о нейронных сетях, вышедших в разные годы в журналах Университета ИТМО: начиная со свойств и характеристик нейронных сетей разных типов, возможностей улучшения качества и ускорения работы нейронных сетей при решении тех или иных задач, моделирования различных процессов человеческого мозга и заканчивая различными практическими вариантами применения нейросетей.
Алгоритм Метромарафона. Как аналитик Яндекса просчитал, что все станции можно посетить за один день
9 мин
12 мая мы с товарищами зашли в московское метро с его открытием утром и, не выбираясь наверх, посетили все 199 доступных в данный момент станций до закрытия метрополитена. Зачем мы всё это сделали – совершенно не ясно, но я попробую рассказать, как так получилось.
Давным-давно, кажется, с год назад жена сказала мне, что хотела бы как-нибудь сфотографировать все станции метро в Москве. Я тогда пошутил, что под такое дело можно рассчитать оптимальный маршрут, позволяющий посетить все станции, напрягаясь по-минимуму. Пошутил и забыл, а тут зимой вспомнил и решил попробовать.

По мере изучения вопроса я обнаружил, что идея сама по себе не то чтобы очень нова – в нью-йоркской подземке аналогичные соревнования проходят с 1966 года. Что же касается московского метро, то ЖЖ-пользователь estrella-de-sur полгода назад проехал его за 12 часов 36 минут (расчётное время – 11 часов 50 минут) по правилу «один шаг на каждую станцию». Но у нас была другая задача – мы хотели выйти на каждой станции и по возможности красиво её сфотографировать. Это означало, что нам в большинстве случаев придётся ждать на ней следующего поезда. Исходя из этого я и строил расчёт.
Предупреждение: если вы умеете решать задачу коммивояжёра на 200 узлах (с помощью генетических алгоритмов или без них) – вас, скорее всего, ждут в другом месте. Можете просто пролистать пост и посмотреть картинки.