
Шаблон для телеграмм ботов на go - Ваш надежный помощник в создании удобного и функционального бота.
В него можно легко добавлять новые модули, расширяющие возможности бота.
Не тратьте время на банальности, его уже потратили для Вас !

golang backend developer
Шаблон для телеграмм ботов на go - Ваш надежный помощник в создании удобного и функционального бота.
В него можно легко добавлять новые модули, расширяющие возможности бота.
Не тратьте время на банальности, его уже потратили для Вас !

Егор Гартман, бэкендер Авито, рассказал, как протестировал несколько библиотек Deep Copy, а потом сделал свою — быстрее и эффективнее.


Хмурое октябрьское утро началось, как обычно с просмотра телеграмчика. И почти сразу же я увидел, что мне там накидали ссылок на статью "Почему уходят из 1С", где упоминался ваш покорный слуга и которая являлась обличительным ответом на мой возмутительный пасквиль про "уход из 1С", где я смел сравнивать ее с другими экосистемами в положительном тоне. Вопиющая вещь, вне всяких сомнений.
Так получилось, что я дотошный и противный зануда, а посему я все-таки не могу пройти мимо и вынужден объясниться, что была за статья такая, и почему мой обличитель не умеет обличать правильно, а оттого вводит, сам не осознавая этого, людей в некоторое заблуждение.
Под катом правильные наезды на 1С и разбор неправильных наездов на 1С. Критика должна быть хорошей, иначе ее уныло читать. Давайте разберем (очередной) крик души 1С-ника по пунктам, а заодно, раз уж сей крик основан на моей статье - разберем и мою статью с точки зрения автора.
Добро пожаловать под кат. Там много сарказма, иронии, обид на 1С, а главное - трезвые мысли насчет этой системы с минимумом эмоций.
Приветствую тебя, дорогой друг! Эта публикация была создана для тебя, если ты хотел бы разобраться с этими непонятными словами из заголовка раз и на всегда. Как с идейной, так и с математической стороны. Признаюсь сразу, в свое время в универе частенько прогуливал семинары по высшей математике где-нибудь в приятном заведение со вкусной едой и хорошей музыкой или вообще дома, занимаясь чем-то "уникальным" и "сверхполезным". Но жизнь оказалась более ироничной, чем я думал. Сейчас я работаю продуктовым аналитиком в @IDFinance и познаю мат. статистику заново. И теперь уже с горящими глазами. Дается местами она не просто, а особенную трудность испытываю, когда хочу найти в интернете простые и понятные материалы по необходимой теме. Собственно, это меня и побудило написать данную статью, включающую в себя всю математику, почему она так работает и как это вообще запрограммировать.

По словам автора, фреймворк PyTorch Lightning был разработан для разработчиков и академических исследователей, работающих в области ИИ. Применение этого фреймворока упрощает написание кода, в частности нейронных сетей, и делает его более понятным для восприятия, вместе с тем открывая широкие возможности для создания масштабируемых моделей глубокого обучения, которые можно легко запускать на распределенном оборудовании.

TL;DR: Этой осенью сообщество Open Data Science и компания Huawei делают новый запуск курса по обработке естественного языка. Страница курса вот. Первая лекция - в среду, 14 сентября.

При разработке систем распознавания речи мы сталкиваемся с заблуждениями среди потребителей и разработчиков, в первую очередь связанными с разделением формы и сути. Одним из таких заблуждений является то, что в устной речи якобы "можно услышать" грамматически верные знаки препинания и пробелы между словами, когда по факту реальная устная речь и грамотная письменная речь очень сильно отличаются (устная речь скорее похожа на "поток" слегка разделенный паузами и интонацией, поэтому люди так не любят монотонно бубнящих докладчиков).
Понятно, что можно просто начинать каждое высказывание с большой буквы и ставить точку в конце. Но хотелось бы иметь какое-то относительно простое и универсальное средство расстановки знаков препинания и заглавных букв в предложениях, которые генерирует наша система распознавания речи. Совсем хорошо бы было, если бы такая система в принципе работала с любыми текстами.
По этой причине мы бы хотели поделиться с сообществом системой, которая:
На всякий случай явно повторюсь — цель такой системы — лишь улучшать читабельность текста. Она не добавляет в текст информации, которой в нем изначально не было.
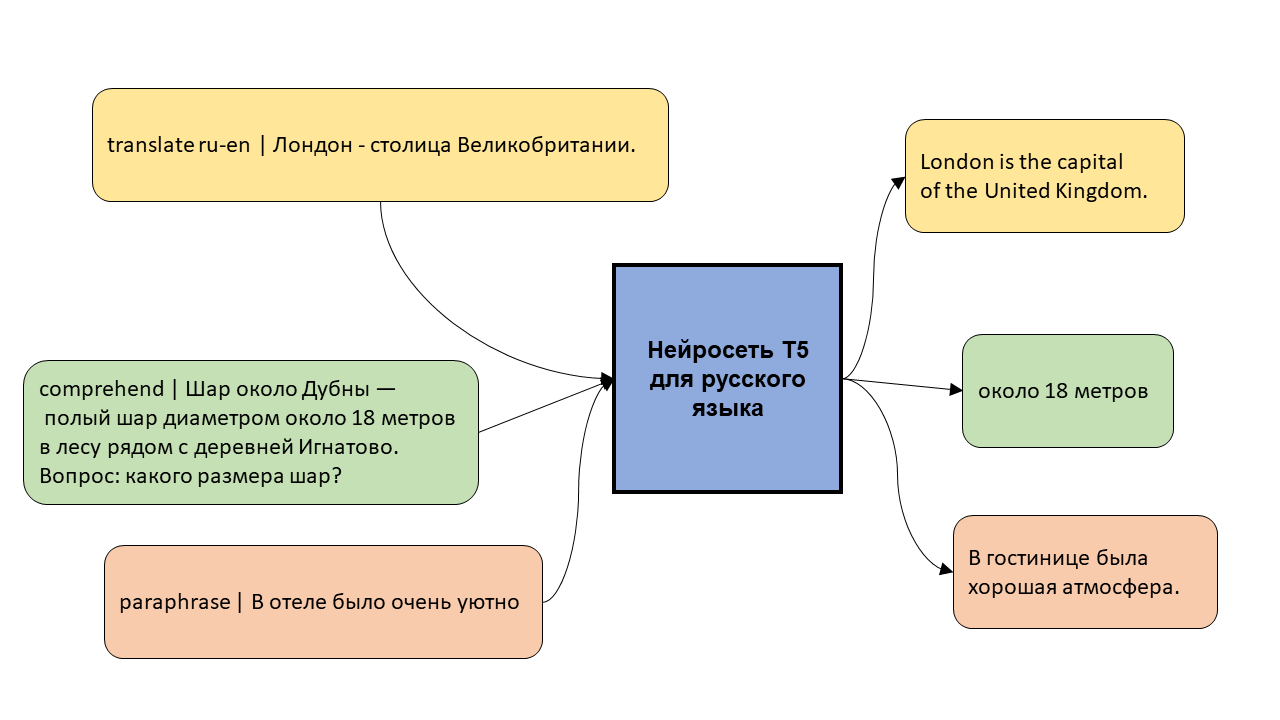
Модель T5 – это нейросеть, которая уже обучена хорошо понимать и генерировать текст, и которую можно дообучить на собственную задачу, будь то перевод, суммаризация текстов, или генерация ответа чат-бота.
В этом посте я рассказываю про первую многозадачную модель T5 для русского языка и показываю, как её можно обучить на новой задаче.
Очень много людей с самым разным бэкграундом, и не всегда даже техническим, в последнее время пытаются перейти в data science. И такой ажиотажный интерес - проблема для всех, кто рассматривает переквалификацию в эту сферу. Потому что рынок труда может оказаться наводнён соискателям без опыта.
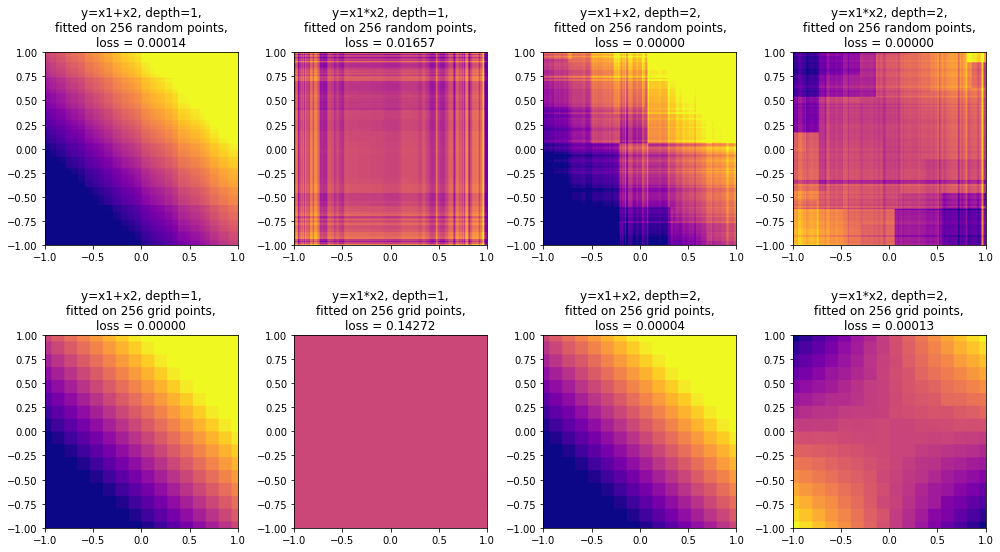
Сейчас существенная часть машинного обучения основана на решающих деревьях и их ансамблях, таких как CatBoost и XGBoost, но при этом не все имеют представление о том, как устроены эти алгоритмы "изнутри".
Данный обзор охватывает сразу несколько тем. Мы начнем с устройства решающего дерева и градиентного бустинга, затем подробно поговорим об XGBoost и CatBoost. Среди основных особенностей алгоритма CatBoost:
• Упорядоченное target-кодирование категориальных признаков
• Использование решающих таблиц
• Разделение ветвей по комбинациям признаков
• Упорядоченный бустинг
• Возможность работы с текстовыми признаками
• Возможность обучения на GPU
В конце обзора поговорим о методах интерпретации решающих деревьев (MDI, SHAP) и о выразительной способности решающих деревьев. Удивительно, но ансамбли деревьев ограниченной глубины, в том числе CatBoost, не являются универсальными аппроксиматорами: в данном обзоре приведено собственное исследование этого вопроса с доказательством (и экспериментальным подтверждением) того, что ансамбль деревьев глубины N не способен сколь угодно точно аппроксимировать функцию  . Поговорим также о выводах, которые можно из этого сделать.
. Поговорим также о выводах, которые можно из этого сделать.

К моему удивлению, в открытом доступе оказалось не так уж много подробных и понятных объяснений того как работает модель GPT от OpenAI. Поэтому я решил всё взять в свои руки и написать этот туториал.
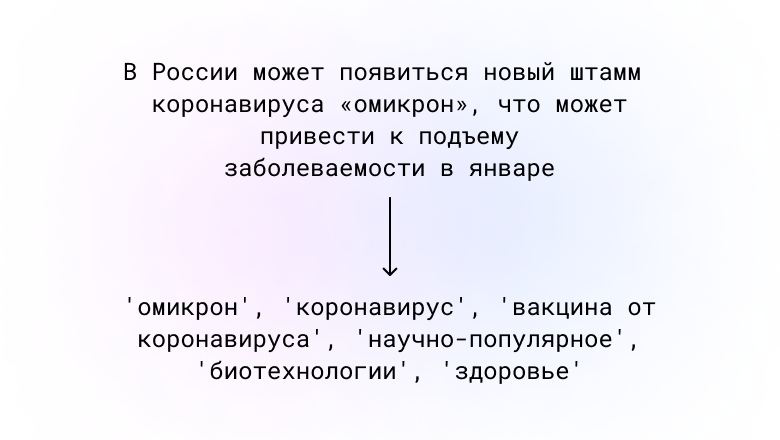
Я попытался обучить русскоязычную модель ruT5-base и ruT5-large на задаче извлечения ключевых слов из текста.

Эта статья посвящена основным современным моделям для генерирующего реферирования и генерации текста в целом: BertSumAbs, GPT, BART, T5 и PEGASUS, и их использованию для русского языка.
В отличие от извлекающих моделей, которые рассмотрены в предыдущих двух статьях, эти модели создают новые тексты, а не только выделяют предложения из оригинального документа. Из-за этого они могут нетривиально изменять исходный текст: удалять слова или заменять их на синонимы, сливать и упрощать предложения, а значит делать ровно то, что делают люди при составлении рефератов.
Ещё десять лет назад методы из этой категории казались фантастикой. Развитие систем нейросетевого машинного перевода сделало генерирующее автоматическое реферирование намного более лёгкой задачей.
Серьёзные методы оценки качества реферирования будут в следующих частях цикла. Сейчас же для наглядности мы испытаем алгоритмы на одной конкретной новости про секвенирование РНК клеток коры головного мозга. Это свежая новость, то есть модели заведомо не могли её видеть. К тому же она довольно сложная: 5.7 баллов по шкале N+1.
Кстати говоря, заголовок к этой статье написан одной из описываемых моделей.

__1. Давайте подумаем, какой уровень у человека, который читает английскую классику почти без словаря?
Я был таким человеком в 2008 году, когда приехал в частную школу английского языка в Лондоне. В школе были группы семи уровней: Beginner, Elementary, Intermediate (и Pre- и Upper-), Advanced, Advanced+. После тестирования меня определили в группу Advanced+. Наверно, у меня было что-то в районе Proficiency, C2?
Ребята-казахи из группы Pre-Intermediate как-то посмеялись надо мной в пабе, потому что меня официант не понял, а их – без проблем. А ещё я не знал некоторых простых разговорных выражений, которые знали люди из групп Intermediate и даже ниже, поскольку в предыдущие пять лет делал упор на чтение классической литературы. И ещё очень, ОЧЕНЬ плохо понимал живую речь на слух. Похоже на С2?
А какой уровень у человека, которого чуть не застрелила полиция в США потому, что он не смог разобрать на слух простые слова “the police”? Это произошло со мной в 2012 году в городе Чарльстон, Южная Каролина. На тот момент, кстати, я как профессионал вырос на голову по сравнению с 2008 годом и уже успел поработать переводчиком. А ведь реально написали бы потом, что был он иностранец, плохо знал язык. Справедливости ради, “the police” проорал афроамериканец с характерным выговором, в гражданской одежде, из автомобиля без полицейской маркировки (“undercover police” это называется).
В бюро переводов обычно есть отдел редакторов, где сидят довольно серьёзные профессионалы. Они проверяют уже сделанные переводы на наличие ошибок перед тем, как отдать заказчику. В том бюро, где работал я, в отделе редакторов был мужчина, который спокойно признавался, что очень плохо говорит и почти не воспринимает на слух бытовую английскую речь. Хорошо, что плевать он хотел на то, какой у него «уровень», а то б, наверно, уволился с работы и впал в депрессию.

Современный человек много чем занимается в интернете: ходит по магазинам, слушает музыку, читает новости. Все эти задачи подразумевают поиск и выбор того, что ему нужно. При этом важную роль тут играют рекомендательные системы. Они помогают людям не утонуть в многообразии вариантов и увидеть именно то, что им подойдёт, то, что иначе им сложно было бы найти. Предоставление пользователям качественных рекомендаций — это важнейшая часть обеспечения первоклассного уровня удовлетворения клиента. Это — один из самых эффективных способов взращивания лояльности клиентов и повышения ценности продукта или услуги в их глазах. Всё это так важно, что целые бизнес-модели некоторых компаний построены вокруг предоставления их клиентам наилучших рекомендаций, что делает рекомендательные системы важнейшими факторами, влияющими на прибыль подобных компаний! В результате неудивительно то, что клиенты проекта Microsoft CSE часто обращаются к нам с просьбами, касающимися реализации эталонных рекомендательных техник. Один из таких проектов был моим первым опытом в данной сфере.
 Статистика приходит к нам на помощь при решении многих задач, например: когда нет возможности построить детерминированную модель, когда слишком много факторов или когда нам необходимо оценить правдоподобие построенной модели с учётом имеющихся данных. Отношение к статистике неоднозначное. Есть мнение, что существует три вида лжи: ложь, наглая ложь и статистика. С другой стороны, многие «пользователи» статистики слишком ей верят, не понимая до конца, как она работает: применяя, например, тест Стьюдента к любым данным без проверки их нормальности. Такая небрежность способна порождать серьёзные ошибки и превращать «поклонников» теста Стьюдента в ненавистников статистики. Попробуем поставить точки над i и разобраться, какие модели случайных величин должны использоваться для описания тех или иных явлений и какая между ними существует генетическая связь.
Статистика приходит к нам на помощь при решении многих задач, например: когда нет возможности построить детерминированную модель, когда слишком много факторов или когда нам необходимо оценить правдоподобие построенной модели с учётом имеющихся данных. Отношение к статистике неоднозначное. Есть мнение, что существует три вида лжи: ложь, наглая ложь и статистика. С другой стороны, многие «пользователи» статистики слишком ей верят, не понимая до конца, как она работает: применяя, например, тест Стьюдента к любым данным без проверки их нормальности. Такая небрежность способна порождать серьёзные ошибки и превращать «поклонников» теста Стьюдента в ненавистников статистики. Попробуем поставить точки над i и разобраться, какие модели случайных величин должны использоваться для описания тех или иных явлений и какая между ними существует генетическая связь.В интернете есть много статей с описанием алгоритма градиентного спуска. Здесь будет еще одна.
8 июля 1958 года The New York Times писала: «Психолог показывает эмбрион компьютера, разработанного, чтобы читать и становиться мудрее. Разработанный ВМФ… стоивший 2 миллиона долларов компьютер "704", обучился различать левое и правое после пятидесяти попыток… По утверждению ВМФ, они используют этот принцип, чтобы построить первую мыслящую машину класса "Перцептрон", которая сможет читать и писать; разработку планируется завершить через год, с общей стоимостью $100 000… Ученые предсказывают, что позже Перцептроны смогут распознавать людей и называть их по имени, мгновенно переводить устную и письменную речь с одного языка на другой. Мистер Розенблатт сказал, что в принципе возможно построить "мозги", которые смогут воспроизводить самих себя на конвейере и которые будут осознавать свое собственное существование» (цитата и перевод из книги С. Николенко, «Глубокое обучение, погружение в мир нейронный сетей»).
Ах уж эти журналисты, умеют заинтриговать. Очень интересно разобраться, что на самом деле представляет из себя мыслящая машина класса «Перцептрон».

 Еще я создала канал в Telegram: GameDEVils, буду делиться там клевыми материалами (про геймдизайн, разработку и историю игр).
Еще я создала канал в Telegram: GameDEVils, буду делиться там клевыми материалами (про геймдизайн, разработку и историю игр). Еще я веду канал в Telegram: GameDEVils, делюсь там клевыми материалами (про геймдизайн, разработку и историю игр).
Еще я веду канал в Telegram: GameDEVils, делюсь там клевыми материалами (про геймдизайн, разработку и историю игр).