В серии предыдущих статей я описывал, почему повсеместно используемые VPN- и прокси-протоколы такие как OpenVPN и L2TP очень уязвимы к выявлению и могут быть легко заблокированы цензорами при желании, обозревал существующие гораздо более надежные протоколы обхода блокировок, клиенты для них, а также описывал настройку сервера двух видов для всего этого.
Многим читателям, однако, ручная настройка показалась сложной и неудобной - хотелось иметь понятный легко устанавливаемый графический интерфейс без необходимости ручного редактирования конфигов и вероятности допустить ошибки, а еще мы не поговорили про механизм "подписок", позволяющих клиентам автоматически подключать список новых серверов с настройками подключений.
Поэтому сегодня мы поговорим об установке и использовании графической панели 3X-UI для сервера X-Ray с поддержкой всего того, что умеет X-Ray: Shadowsocks-2022, VLESS с XTLS и т.д.




 Коллекция в Python — программный объект (переменная-контейнер), хранящая набор значений одного или различных типов, позволяющий обращаться к этим значениям, а также применять специальные функции и методы, зависящие от типа коллекции.
Коллекция в Python — программный объект (переменная-контейнер), хранящая набор значений одного или различных типов, позволяющий обращаться к этим значениям, а также применять специальные функции и методы, зависящие от типа коллекции. 
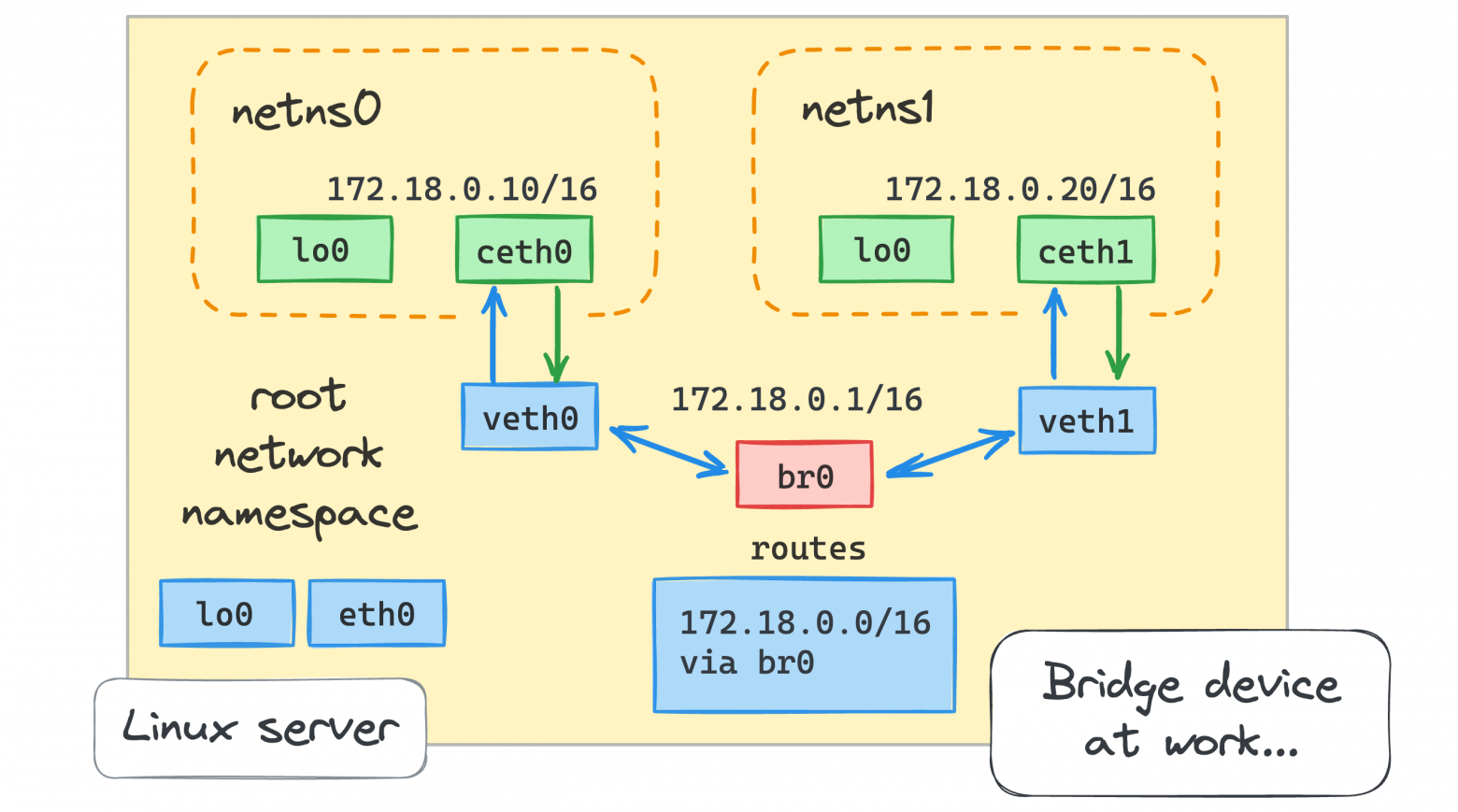
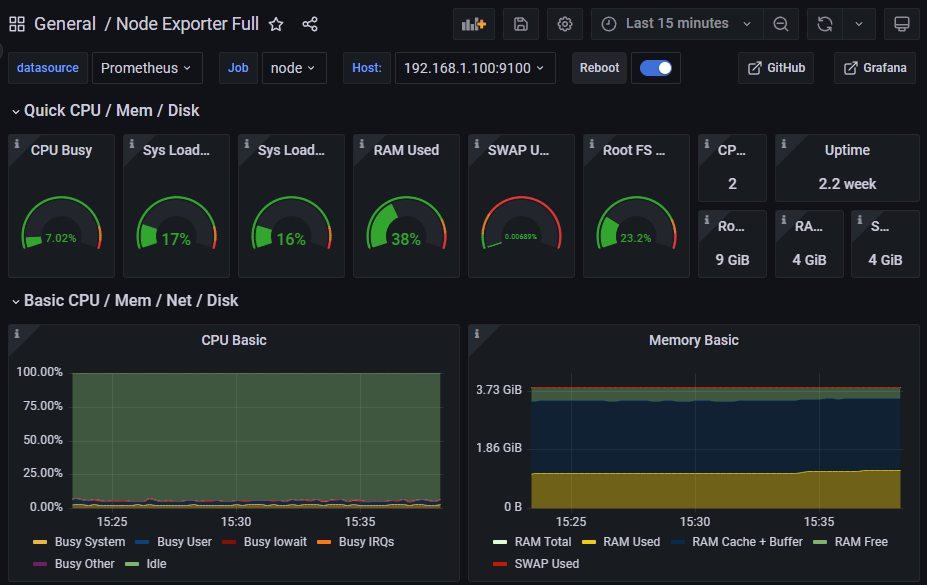


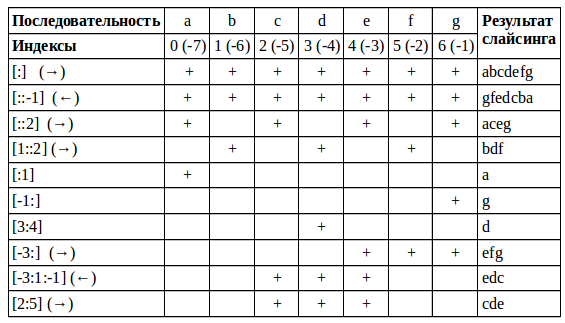 Данная статья является продолжением моей статьи "
Данная статья является продолжением моей статьи "