Привет! Меня зовут Александр, я работаю в команде матчинга Ozon. Ежедневно мы имеем дело с десятками миллионов товаров, и наша задача — поиск и сопоставление одинаковых предложений (нахождение матчей) на нашей площадке, чтобы вы не видели бесконечную ленту одинаковых товаров.
На странице любого товара на Ozon есть картинки, заголовок, описание и дополнительные атрибуты. Всю эту информацию мы хотим извлекать и обрабатывать для решения разных задач. И особенно она важна для команды матчинга.
Чтобы извлекать признаки из товара, мы строим его векторные представления (эмбеддинги), используя различные текстовые модели (fastText, трансформеры) для описаний и заголовков и целый набор архитектур свёрточных сетей (ResNet, Effnet, NFNet) — для картинок. Далее эти векторы используются для генерации фичей и товарного сопоставления.
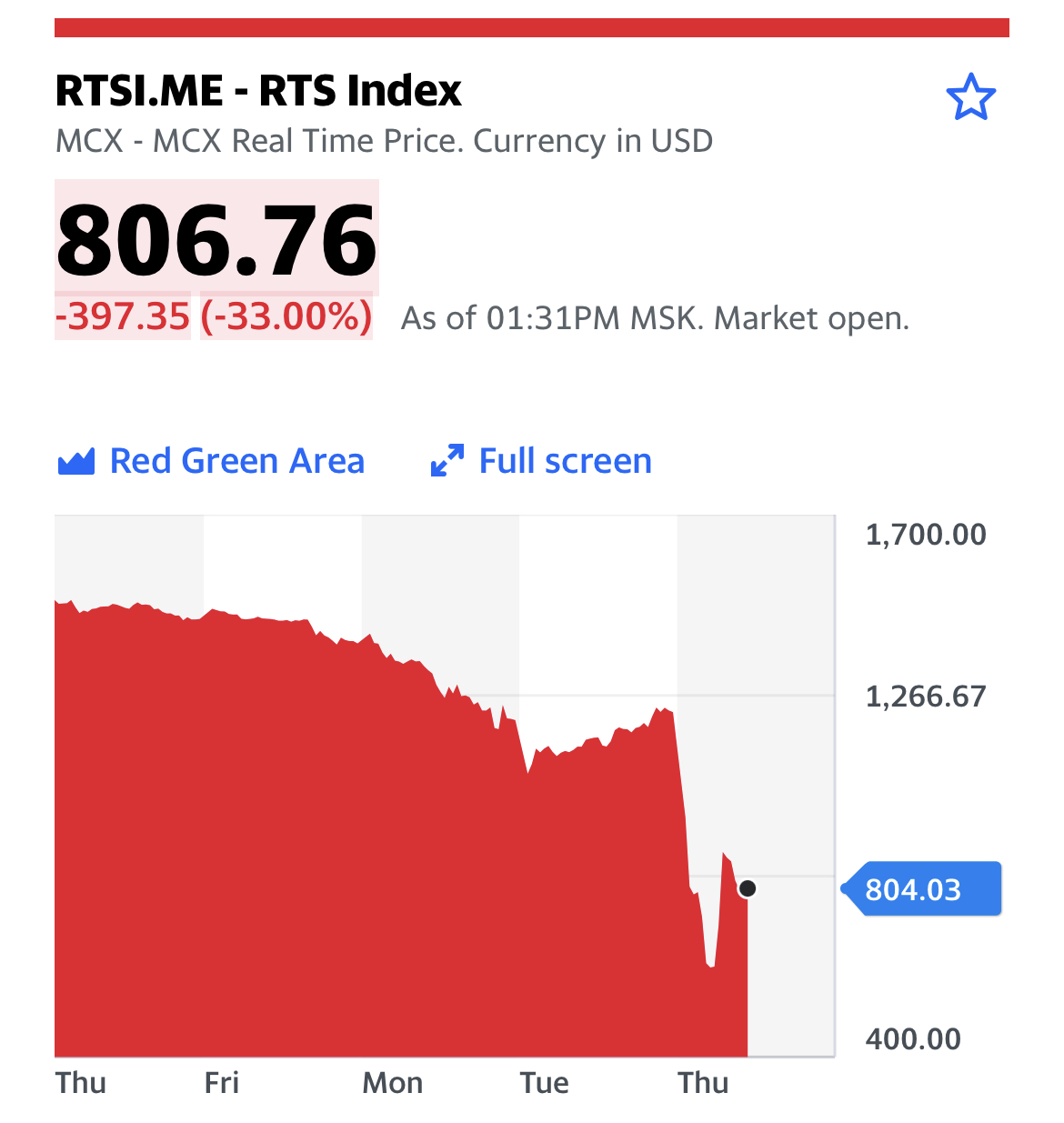
На Ozon ежедневно появляются миллионы обновлений — и считать эмбеддинги для всех моделей становится проблематично. А что, если вместо этого (где каждый вектор описывает отдельную часть товара) мы получим один вектор для всего товара сразу? Звучит неплохо, только как бы это грамотно реализовать…