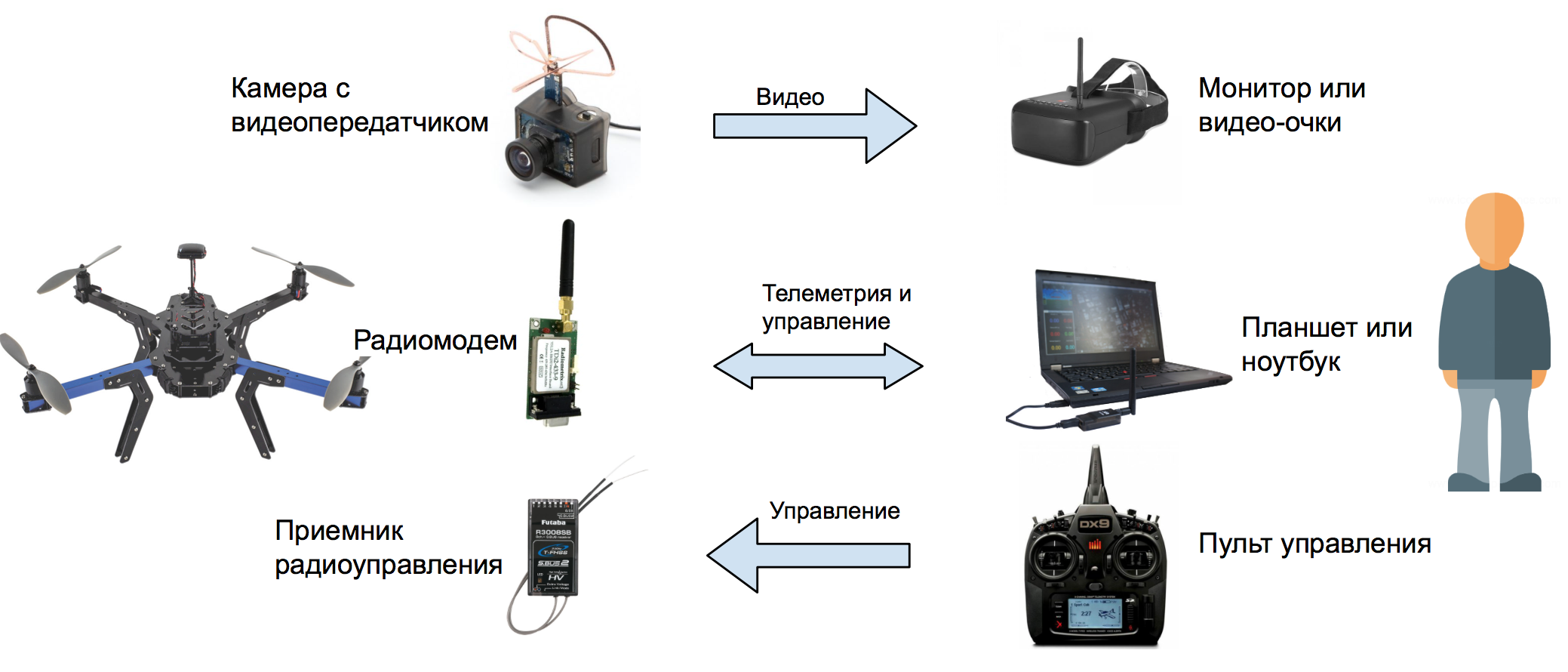
Для того, чтобы охватить все краевые случаи, встречающиеся в реальном мире, критические системы восприятия нуждаются в огромных массивах данных. Один из распространенных подходов к обучению алгоритмов для беспилотных автомобилей – подбор и разметка данных о реальном вождении. На CVPR 2020 Андрей Карпатый рассказывал, что Tesla тоже использует этот подход – их автомобили адаптируют метки объектов в режиме онлайн. «Вариация и контроль» очень важны, поскольку инженеры постоянно адаптируют онтологию и методику маркировки данных, так как беспилотные автомобили постоянно сталкиваются с новыми сценариями, которые необходимо анализировать.
Впрочем, этот подход, основанный на использовании данных, имеет различные ограничения – они обусловлены масштабируемостью, стоимостью сбора данных и множеством усилией, необходимых для точной маркировки датасетов. В этом тексте команда Applied расскажет о подходе, основанном на синтетических размеченных данных. Этот подход обеспечивает ускорение и экономичность обучения и разработки критических алгоритмов для беспилотного транспорта.

Пример синтетических данных для изображений с камер с эталонной разметкой. Оригинальное RGB изображение (вверху слева), 2D-рамки (вверху справа), семантическая разметка (внизу слева) и 3D-рамки (внизу справа).