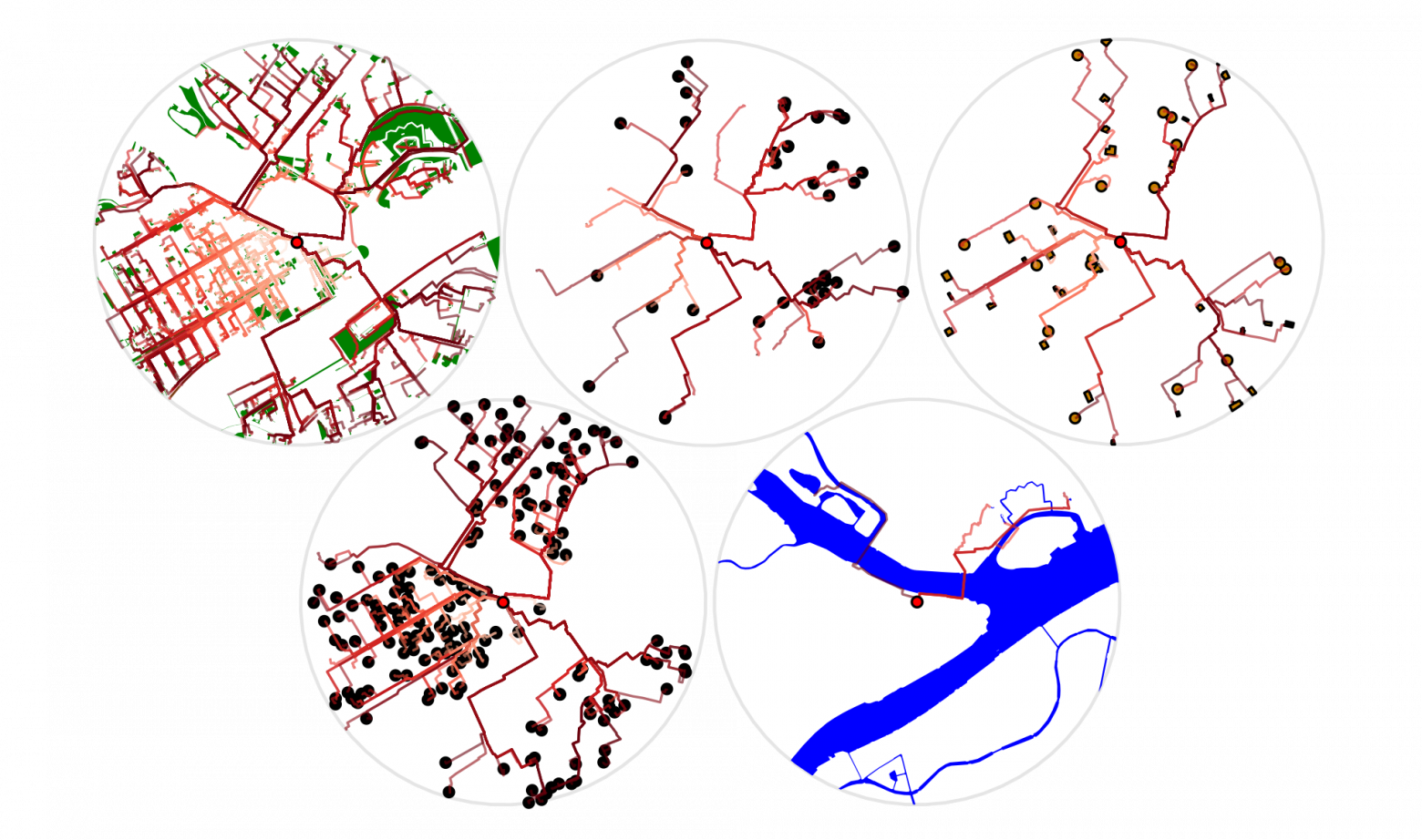
Даже не являясь навигатором, 2ГИС собирает и показывает информацию о пробках. Во-первых, это необходимо для построения оптимальных маршрутов, а во-вторых — такие данные очень нужны пользователям в больших городах.
В 2ГИС сервис пробок появился в сентябре 2011 года и сегодня работает в пяти городах (Новосибирск, Санкт-Петербург, Красноярск, Уфа, Казань). В планах на ближайшее будущее — запустить пробки во всех городах-миллионниках.
Под катом история про то, с какими проблемами мы столкнулись и как их решили.

В 2ГИС сервис пробок появился в сентябре 2011 года и сегодня работает в пяти городах (Новосибирск, Санкт-Петербург, Красноярск, Уфа, Казань). В планах на ближайшее будущее — запустить пробки во всех городах-миллионниках.
Под катом история про то, с какими проблемами мы столкнулись и как их решили.